Descenso de Gradiente y Variaciones Sobre el Tema
Mariano Rivera
agosto 2018
Una excelente compilación de métodos tipo descenso puede encontrase en el blog
[http://ruder.io/optimizing-gradient-descent/index.html#fn:6]
Descenso de Gradiente Simple (Descenso de Gradiente, GD)
Sea el problema de optimización
para suave (2 veces continuamente diferenciable).
Luego, sea el punto actual. Entonces el vector
es una dirección de descenso (esto es, satisface ).
Notación. Para simplificar nuestra notación definimos:
Por lo que el punto obtenido mediante la formula de actualización
donde es el tamaño de paso y para una sufientemente pequeña se garantiza:
si .
Ejemplo GD
Calcular la raiz cuadrada de 2.
Notémos que es solución de la ecuación no lineal:
Luego
# solo por usar sympy
import sympy as sym
from sympy.abc import x
sym.init_printing()
sym.integrate(x**2-2, x)
entonces definimos la función tal que . Y resolvemos:
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(-3,3,.1) # from -3 to 3 in steps of .1
plt.plot(x,x**3/3-2*x)
[<matplotlib.lines.Line2D at 0x11d67cd68>]
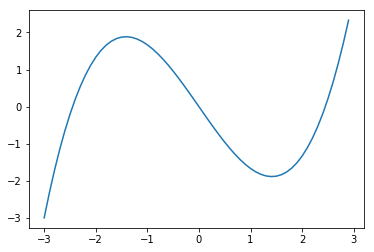
Note que el mínimo esta precisamente en (y la otra raiz está en el máximo, en ).
Usamos descenso de gradiente para culcular el mínimo.
x = 0 # valor inicial de x
alpha = 0.2 # tamaño (pequeño) de paso
for t in range(40):
x = x - alpha*(x**2-2)
print('x1({0}) = {1}'.format(t,x))
x1(0) = 0.4
x1(1) = 0.768
x1(2) = 1.0500352
x1(3) = 1.229520415752192
x1(4) = 1.3271763252019033
x1(5) = 1.3748969255666177
x1(6) = 1.3968286143801103
x1(7) = 1.4066025787898986
x1(8) = 1.41089641585822
x1(9) = 1.4127706766019057
x1(10) = 1.4135864796686644
x1(11) = 1.413941132568255
x1(12) = 1.414095227294575
x1(13) = 1.414162164923116
x1(14) = 1.414191239183109
x1(15) = 1.4142038669866575
x1(16) = 1.4142093515066543
x1(17) = 1.41421173352888
x1(18) = 1.414212768078728
x1(19) = 1.4142132173993485
x1(20) = 1.4142134125459451
x1(21) = 1.4142134973009757
x1(22) = 1.4142135341113242
x1(23) = 1.414213550098596
x1(24) = 1.414213557042101
x1(25) = 1.4142135600577665
x1(26) = 1.4142135613675142
x1(27) = 1.4142135619363567
x1(28) = 1.4142135621834133
x1(29) = 1.4142135622907135
x1(30) = 1.4142135623373155
x1(31) = 1.4142135623575556
x1(32) = 1.414213562366346
x1(33) = 1.414213562370164
x1(34) = 1.414213562371822
x1(35) = 1.414213562372542
x1(36) = 1.414213562372855
x1(37) = 1.4142135623729908
x1(38) = 1.4142135623730498
x1(39) = 1.4142135623730754
que es muy cercano a
np.sqrt(2)
Ejemplo de regresión
Datos
from sklearn import linear_model, datasets
n_samples = 500
X, y = datasets.make_regression(n_samples=n_samples,
n_features=1,
n_informative=2,
noise=5,
random_state=0) #2)
n_outliers=100
X[:n_outliers], y[:n_outliers] = datasets.make_regression(n_samples=n_outliers,
n_features=1,
n_informative=2,
noise=2,
random_state=61)
y=np.expand_dims(y,axis=1)
plt.scatter(X[:],y[:], marker='.')
<matplotlib.collections.PathCollection at 0x120012eb8>
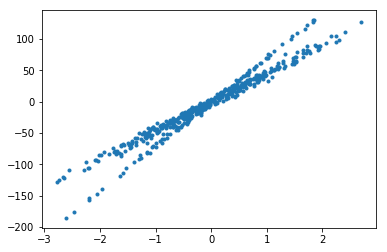
Agregamos in 1 a los datos de tal forma que nos queden en coordenadas homogéneas:
y en vector de corficientes para regresión lineal esta dado por
Luego, la función objetivo la definimos como
con derivadas parciales:
y
Entonces el gradiente de la función objetivo es
#-------------------------------------------------------------
def grad_quadratic(theta, f_params):
'''
Gradiente de la funcion de costo
sum_i (theta@x[i]-y[i])**2
'''
X = f_params['X']
y = f_params['y']
err=theta[0]*X+theta[1]-y
partial0=err
partial1=X*partial0
gradient= np.concatenate((partial1, partial0), axis=1)
return np.sum(gradient, axis=1)
#-------------------------------------------------------------
def grad_exp(theta, f_params):
'''
Gradiente de la funcion de costo
sum_i 1-exp(-k(theta@x[i]-y[i])**2)
'''
kappa= f_params['kappa']
X = f_params['X']
y = f_params['y']
err=theta[0]*X+theta[1]-y
partial0=err*np.exp(-kappa*err**2)
partial1=X*partial0
gradient= np.concatenate((partial1, partial0), axis=1)
return np.mean(gradient, axis=0)
#-------------------------------------------------------------
Implementación descenso de gradiente simple (GD)
def GD(theta=[], grad=None, gd_params={}, f_params={}):
'''
Descenso de gradiente
Parámetros
-----------
theta : condicion inicial
grad : función que calcula el gradiente
gd_params : lista de parametros para el algoritmo de descenso,
nIter = gd_params[0] número de iteraciones
alpha = gd_params[1] tamaño de paso alpha
f_params : lista de parametros para la funcion objetivo
kappa = f_params['kappa'] parametro de escala (rechazo de outliers)
X = f_params['X'] Variable independiente
y = f_params['y'] Variable dependiente
Regresa
-----------
Theta : trayectoria de los parametros
Theta[-1] es el valor alcanzado en la ultima iteracion
'''
nIter = gd_params['nIter']
alpha = gd_params['alpha']
Theta=[]
for t in range(nIter):
p = grad(theta,f_params=f_params)
theta = theta - alpha*p
Theta.append(theta)
return np.array(Theta)
Descenso de Gradiente Estocástico (SGD)
Ahora considermos una variante del problema general, uno cuya función objetivo, o costo, se pueda denotar como la suma de muchos (si, muchos) pequeños costos. Esto es
En este caso, la dirección de descenso de gradiente esta dado por
Note que, puede ser interpretado como un valor esperado (promedio sobre toda la población). Esto es:
donde denota la cardinalidad (número de elementos) en el conjunto .
El término estocástico viene por el hecho de que, si en cada iteración, en vez de tomar la suma sobre toda la población, solo lo hacemnos sobre una muestra
Luego
Esto equivale a calcular el gradiente como el promedio de los gradientes de la muestra.
Ventajas del SGD:
-
Si la función objetivo es la suma de de costos individuales (errores) sobre un conjunto muy grande de datos. La muestra suele ser representativa y producir un valor muy cercano al de la población.
-
Se reduce el número de cálculos en cada iteración.
-
Cuando hay datos atípicos (outliers), las muestras pueden ser robustas a esas “pocas” grandes desviaciones (salvo en aquellas muestras que sean incluidos, que se esperan sean pocas).
-
Si la función objetivo es (ruidosa, tiene muchos mínimos locales pequeños). El gradiente estocástico permite suavizar la función objetivo y reduce el riesgo de tener una convergencia temprana.
Desventajas del SGD:
- El efecto de los outliers en el gradiente de una muestra puede afectar mas fuertemente y desviar al algoritmo de su trayectoria de convergencia.
[1] Herbert Robbins and Sutton Monro, A Stochastic Approximation Method, Ann. Math. Statist., Vol 22(3), 400-407 (1951).
Implementación descenso de gradiente estocástico (SGD)
def SGD(theta=[], grad=None, gd_params=[], f_params=[]):
'''
Descenso de gradiente estocástico
Parámetros
-----------
theta : condicion inicial
grad : funcion que calcula el gradiente
gd_params : lista de parametros para el algoritmo de descenso,
nIter = gd_params['nIter'] número de iteraciones
alpha = gd_params['alpha'] tamaño de paso alpha
batch_size = gd_params['batch_size'] tamaño de la muestra
f_params : lista de parametros para la funcion objetivo,
kappa = f_params['kappa'] parametro de escala (rechazo de outliers)
X = f_params['X'] Variable independiente
y = f_params['y'] Variable dependiente
Regresa
-----------
Theta : trayectoria de los parametros
Theta[-1] es el valor alcanzado en la ultima iteracion
'''
(high,dim) = f_params['X'].shape
batch_size = gd_params['batch_size']
nIter = gd_params['nIter']
alpha = gd_params['alpha']
Theta=[]
for t in range(nIter):
# Set of sampled indices
smpIdx = np.random.randint(low=0, high=high, size=batch_size, dtype='int32')
# sample
smpX = f_params['X'][smpIdx]
smpy = f_params['y'][smpIdx]
# parametros de la funcion objetivo
smpf_params ={'kappa' : f_params['kappa'],
'X' : smpX ,
'y' : smpy}
p = grad(theta,f_params=smpf_params)
theta = theta - alpha*p
Theta.append(theta)
return np.array(Theta)
Descenso de Gradiente con Momento (Inercia)
Descenso de gradiente es un método muy robusto y se mantiene aproximandose constantemente hacia un mínimo local. Este puede ser a su vez un problema:
-
En caso de tener funciones de costo con muchas pequeñas oscilaciones, GD es propenso a ser atrapado en “malos minímos locales”.
-
Si se esta muy lejos del óptimo y el tamaño de paso es pequeño, entonces GD tendrá una convergencia muy lenta
Para reducir el efecto de los problemas mencionados, se ha propuesto incluir inercia. Esto es, mientras GD puede comprenderse con la analogía de un caminante que siempre dá un paso cosntante en la dirección que localmente tienen el mayor descenso. Descenso de Gardiente con Momento (MGD) sería el equivalente a una partícula masiva bajo el efecto de la gravedad. En tal caso, la partícula se acelera conforme acumule varios pasos en descenso. En el caso de la partícula, la acelaración puede incrementarse hasta alcanzar su velocidad límite: aquella en la que la fuerza de gravedad se equipare con la fuerza que ejerce la fricción de la superficie y del aire. La velocidad límite es la explicación al porqué un proyectil lanzado por un arma de fuego verticalmente no regresa con la misma velocidad con que salió del fusil, o el porqué la caida de los paracaidistas no se acelera durante todo el descenso; de hecho los paracaidistas maniobran para modificar su arrastre y así incrementar o decrementar la velocidad de caida; y así poder mantenerse acercarse y permanecer junto a otros miembros del grupo. Igualmente, podemos imponer a nuestra partícula en su descenso por la superficie de la función costo que además de momento (momentum), tenga una velocidad límite. Esto lo dejaremos para después, por lo pronto nos centraremos en el momento o inercia.
La modificación para incluir momento en GD consiste en lo siguiente
-
Sea el gradiente en el punto actual; luego
-
calcular la dirección de descenso con ; y
-
actualizar el punto con .
La siguiente figura muestra gráficamente la actualización mediante MGD

Analizando el cálculo de la dirección de descenso observamos que:
donde asumimos que .
Notamos que se están integrando todos los gradientes de la trayectoria, pesando mas los gradientes mas recientes.
Para conservar el efecto de los gradientes recientes y suavizar la trayectoria, se recomienda cercana y menor que 1 , de hecho es un valor comúnmente utilizado.
eta =0.9
t=10
etapow = [eta**i for i in range(t)]
print('Efecto de t (peso) en gradientes pasados')
print('\n'.join('{0} : {1:2.2E}'.format(*k) for k in enumerate(etapow)))
plt.plot(etapow)
plt.show()
Efecto de t (peso) en gradientes pasados
0 : 1.00E+00
1 : 9.00E-01
2 : 8.10E-01
3 : 7.29E-01
4 : 6.56E-01
5 : 5.90E-01
6 : 5.31E-01
7 : 4.78E-01
8 : 4.30E-01
9 : 3.87E-01
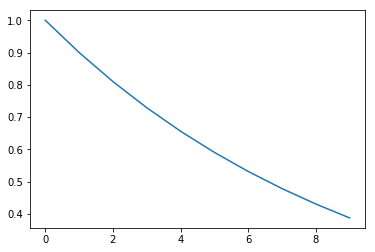
La integración de los gradientes pasados permite accumular la componente de los gradientes que apuntan en la misma dirección y cancelar las componentes normales a dicha trayectoria.
Implementación descenso de gradiente con momento (MGD)
def MGD(theta=[], grad=None, gd_params={}, f_params={}):
'''
Descenso de gradiente con momento (inercia)
Parámetros
-----------
theta : condicion inicial
grad : funcion que calcula el gradiente
gd_params : lista de parametros para el algoritmo de descenso,
nIter = gd_params['nIter'] número de iteraciones
alpha = gd_params['alpha'] tamaño de paso alpha
eta = gd_params['eta'] parametro de inercia (0,1]
f_params : lista de parametros para la funcion objetivo,
kappa = f_params['kappa'] parametro de escala (rechazo de outliers)
X = f_params['X'] Variable independiente
y = f_params['y'] Variable dependiente
Regresa
-----------
Theta : trayectoria de los parametros
Theta[-1] es el valor alcanzado en la ultima iteracion
'''
nIter = gd_params['nIter']
alpha = gd_params['alpha']
eta = gd_params['eta']
p_old = np.zeros(theta.shape)
Theta=[]
for t in range(nIter):
g = grad(theta, f_params=f_params)
p = g + eta*p_old
theta = theta - alpha*p
p_old=p
Theta.append(theta)
return np.array(Theta)
Descenso acelerado de Nesterov (NAG)
El algoritmo de descenso con momento no ha demostrado que si bien el momento ayuda a accelerar la convergencia y reducir el riesgo de quedar atrapado en mínimos locales, también tienen una tendencia a sobrepasar los valles. Por ello, mediante una pequeña modificación se reducirá el effecto de sobrepaso (overshooting). Esta modificación es el algoritmo de Descenso Acelerado de Neasterov (NAG) [2].
El algoritmo NAG puede considerarse del tipo de dos pasos Predictor-Corrector. En el paso predictor se extrapola linealmente la trayectoria actual. Luego, en el punto predicho, se evalua el gradiente y se hace la correción de la trayectoria. Con ello se logra un aproximación de segundo orden de la trayectoria con un costo computacional similar al de Descenso de Gardiente con Momento (MGD). Al mantener el efecto de inercia pero reducir los sobrepasos, NAG también se incrementa la razón de convergencia
Las fórmulas de actualización del algoritmo NAG estan dadas por los siguientes puntos
-
Sea el punto predicho en primer orden (usando la dirección anterior); luego
-
Calcular el gradiente en el punto predicho: ; entonces
-
Calcular la dirección de descenso con ; y
-
Actualizar el punto con
La siguiente figura muestra gráficamente la actualización mediante NAG
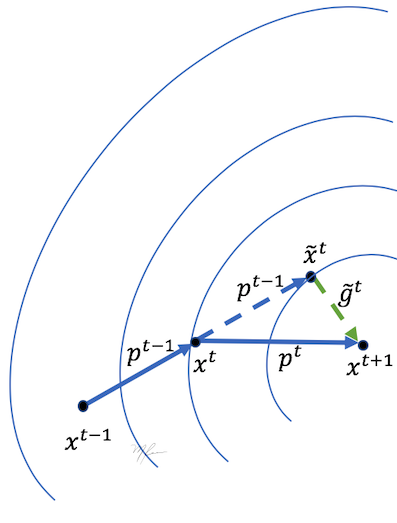
[2] Nesterov, Y., A method for unconstrained convex minimization problem with the rate of convergence o(1/k2). Doklady ANSSSR (translated as Soviet.Math.Docl.), vol. 269, pp. 543-547 (1993)
Implementación del algoritmo NAG
def NAG(theta=[], grad=None, gd_params={}, f_params={}):
'''
Descenso acelerado de Nesterov
Parámetros
-----------
theta : condicion inicial
grad : funcion que calcula el gradiente
gd_params : lista de parametros para el algoritmo de descenso,
nIter = gd_params['nIter'] número de iteraciones
alpha = gd_params['alpha'] tamaño de paso alpha
eta = gd_params['eta'] parametro de inercia (0,1]
f_params : lista de parametros para la funcion objetivo,
kappa = f_params['kappa'] parametro de escala (rechazo de outliers)
X = f_params['X'] Variable independiente
y = f_params['y'] Variable dependiente
Regresa
-----------
Theta : trayectoria de los parametros
Theta[-1] es el valor alcanzado en la ultima iteracion
'''
nIter = gd_params['nIter']
alpha = gd_params['alpha']
eta = gd_params['eta']
p = np.zeros(theta.shape)
Theta=[]
for t in range(nIter):
pre_theta = theta - 2.0*alpha*p
g = grad(pre_theta, f_params=f_params)
p = g + eta*p
theta = theta - alpha*p
Theta.append(theta)
return np.array(Theta)
Descenso de Gradiente Adaptable (ADAGRAD)
Considere el caso en que la magnitud del gradiente de la función es relativamente grande (aun estamos lejos del óptimo). Dado que la magitud del gradiente es una cantidad a la que contribuyen todas las derivadas parciales, es posible que a pesar de tener una magnitud grande, existan coordenadas donde la función cambia poco (derivadas parciales de norma pequeña). Lo que convienen hacer es que se den pasos grandes en las componentes del gradiente que son grandes (en valor absoluto) y pasos cortos en las componentes pequeñas.
Los algortimos MGD como NAG se enfocan en estimar mejor la dirección de descenso. Sin embargo, el desempeño de dichos algoritmos se ve comprometido por la correcta selección del tamaño de paso . Para ello, el algoritmo ADAGRAD [3] busca estimar el correcto tamaño de paso en cada iteración estimando un tamaño de paso para cada una de las variables en forma independiente.
Las fórmulas de actualización del algoritmo NAG estan dadas por los siguientes puntos
-
Sea
la -ésima derivada parcial de la función en el punto actual ; esto es , entonces -
Calcular la suma de los cuadrados de las parciales hasta la iteración actual:
y -
Actualiza el punto con
donde es una constante pequeña que evita la división por cero.
[3] Duchi, J., Hazan, E., & Singer, Y., Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. Journal of Machine Learning Research, 12, pp 2121–2159 (2011). see http://jmlr.org/papers/v12/duchi11a.html
Descenso de Gradiente Adaptable (ADADELTA)
Note que el término en ADAGRAD se mantienen acumulando las derivadas parciales desde el inicio de las iteraciones. Esto puede reducir en forma temprana el tamaño de paso para algunos parámetros. Por ello, es mejor ir reduciendo paulatinamente la contribución de términos pasados.
Para ello, es conveniente realizar ajuste similar a la intergación de las direcciones pasadas:
-
Sea
la -ésima derivada parcial de la función en el punto actual ; esto es , entonces -
integrar los cuadrados de las parciales hasta la iteración actual:
con grandes (típicamente ); y -
actualizar el punto, donde cada elemento tienen su propio paso
[4] Bengio, Y., Boulanger-Lewandowski, N., & Pascanu, R., Advances in Optimizing Recurrent Networks (2012)
Implementación del algoritmo ADADELTA
def ADADELTA(theta=[], grad=None, gd_params={}, f_params={}):
'''
Descenso de Gradiente Adaptable (ADADELTA)
Parámetros
-----------
theta : condicion inicial
grad : funcion que calcula el gradiente
gd_params : lista de parametros para el algoritmo de descenso,
nIter = gd_params['nIter'] número de iteraciones
alphaADA = gd_params['alphaADADELTA'] tamaño de paso alpha
eta = gd_params['eta'] parametro adaptación del alpha
f_params : lista de parametros para la funcion objetivo,
kappa = f_params['kappa'] parametro de escala (rechazo de outliers)
X = f_params['X'] Variable independiente
y = f_params['y'] Variable dependiente
Regresa
-----------
Theta : trayectoria de los parametros
Theta[-1] es el valor alcanzado en la ultima iteracion
'''
epsilon= 1e-8
nIter = gd_params['nIter']
alpha = gd_params['alphaADADELTA']
eta = gd_params['eta']
G = np.zeros(theta.shape)
g = np.zeros(theta.shape)
Theta=[]
for t in range(nIter):
g = grad(theta, f_params=f_params)
G = eta*g**2 + (1-eta)*G
p = 1.0/(np.sqrt(G)+epsilon)*g
theta = theta - alpha * p
Theta.append(theta)
return np.array(Theta)
Momentum Adaptable (ADAM)
El algoritmo ADAM [5]_ Calcula la dirección de descenso usando momentum (similar a MGD) y utiliza una estrategia similar para calcular adaptar el tamaño de paso. Es decir, utiliza momuntum para actualizar el paso, lo que evita cambios bruscos en el paso. Esto lo hace muy estable para su uso en estrategia tipo Gradiente Estocástico (SGD) donde las muestras pueden provocar cambios grandes en la magnitud del gradiente, además calcula un paso global en vez de usar un paso para cada variable. También adecuado en estrategias de entrenamiento tipo estocásticas o por lotes, como en el caso de Redes Neuronales Profundas (Deep Learning)
Una mejora importante es la correción del sezgo (bias) en la estimación de los momentos.
Generalmente las razones de aprendizaje (momentum) son cercanas a 1, típicamente: y .
[5] D. P. Kingma and J. L. Ba. Adam: a Method for Stochastic Optimization. In procc. ICLR 2015, 1–13 (2015)
Una iteración del algoritmo ADAM se resume en los siguientes pasos
Sea
la -ésima derivada parcial de la función en el punto actual . Entonces
-
Calcular la dirección de descenso con momentum
donde conserva la escala de y el gradiente
. -
Luego, actualizar, a la vez con momentum, el factor adaptativo del descenso :
donde es el vector de elementos a cuadrado del gradiente. -
Escalar la dirección de descenso y el momentum (reducción del sezgo):
-
Actualizar el punto con la fórmula de paso adaptable
Importancia de la reducción del sezgo
El paso 1 del algoritmo ADAM pretende mejorar el cálculo del gradiente, calculado general mente sobre solo una muestra, promediandolo con los gradientes recientemente calculados:
Si asumimos como condicion inicial de las iteraciones, nos lleva a
Tomando valores esperados, y usando , si y son independientes:
Luego usamos la propiedad de la serie geométrica
lo que resulta en
por loque para corregur este facor se hace
Implementación del algoritmo ADAM
def ADAM(theta=[], grad=None, gd_params={}, f_params={}):
'''
Descenso de Gradiente Adaptable con Momentum(A DAM)
Parámetros
-----------
theta : condicion inicial
grad : funcion que calcula el gradiente
gd_params : lista de parametros para el algoritmo de descenso,
nIter = gd_params['nIter'] número de iteraciones
alphaADA = gd_params['alphaADAM'] tamaño de paso alpha
eta1 = gd_params['eta1'] factor de momentum para la direccion
de descenso (0,1)
eta2 = gd_params['eta2'] factor de momentum para la el
tamaño de paso (0,1)
f_params : lista de parametros para la funcion objetivo,
kappa = f_params['kappa'] parametro de escala (rechazo de outliers)
X = f_params['X'] Variable independiente
y = f_params['y'] Variable dependiente
Regresa
-----------
Theta : trayectoria de los parametros
Theta[-1] es el valor alcanzado en la ultima iteracion
'''
epsilon= 1e-8
nIter = gd_params['nIter']
alpha = gd_params['alphaADAM']
eta1 = gd_params['eta1']
eta2 = gd_params['eta2']
p = np.zeros(theta.shape)
v = 0.0
Theta = []
eta1_t = eta1
eta2_t = eta2
for t in range(nIter):
g = grad(theta, f_params=f_params)
p = eta1*p + (1.0-eta1)*g
v = eta2*v + (1.0-eta2)*(g**2)
#p = p/(1.-eta1_t)
#v = v/(1.-eta2_t)
theta = theta - alpha * p / (np.sqrt(v)+epsilon)
eta1_t *= eta1
eta2_t *= eta2
Theta.append(theta)
return np.array(Theta)
Evaluación del los algoritmos de descenso de gradiente
# condición inicial
theta=10*np.random.normal(size=2)
#theta= [-0.61752689 -0.76804482]
# parámetros del algoritmo
gd_params = {'alpha' : 0.95,
'alphaADADELTA' : 0.7,
'alphaADAM' : 0.95,
'nIter' : 300,
'batch_size' : 100,
'eta' : 0.9,
'eta1' : 0.9,
'eta2' : 0.999}
# parámetros de la función objetivo
f_params={'kappa' : 0.01,
'X' : X ,
'y' : y}
Descenso de Gradiente
ThetaGD = GD(theta=theta, grad=grad_exp,
gd_params=gd_params, f_params=f_params)
print('Inicio:', theta,'-> Fin:', ThetaGD[-1,:])
Inicio: [ 6.92950223 -10.81700592] -> Fin: [45.67020876 -0.27659597]
Descenso de Gradiente Estocástico
ThetaSGD = SGD(theta=theta, grad=grad_exp,
gd_params=gd_params, f_params=f_params)
print('Inicio:', theta,'-> Fin:', ThetaSGD[-1,:])
Inicio: [ 6.92950223 -10.81700592] -> Fin: [45.89263223 -0.2931078 ]
Descenso de Gradiente con Inercia
ThetaMGD = MGD(theta=theta, grad=grad_exp,
gd_params=gd_params, f_params=f_params)
print('Inicio:', theta,'-> Fin:', ThetaMGD[-1,:])
Inicio: [ 6.92950223 -10.81700592] -> Fin: [45.67020783 -0.27659608]
Nesterov
ThetaNAG = NAG(theta=theta, grad=grad_exp,
gd_params=gd_params, f_params=f_params)
print('Inicio:', theta,'-> Fin:', ThetaMGD[-1,:])
Inicio: [ 6.92950223 -10.81700592] -> Fin: [45.67020783 -0.27659608]
ADADELTA
ThetaADADELTA = ADADELTA(theta=theta, grad=grad_exp,
gd_params=gd_params, f_params=f_params)
print('Inicio:', theta,'-> Fin:', ThetaADADELTA[-1,:])
Inicio: [ 6.92950223 -10.81700592] -> Fin: [46.02421512 -0.62897892]
ADAM
ThetaADAM = ADAM(theta=theta, grad=grad_exp,
gd_params=gd_params, f_params=f_params)
print('Inicio:', theta,'-> Fin:', ThetaADAM[-1,:])
Inicio: [ 6.92950223 -10.81700592] -> Fin: [45.67020748 -0.27659608]
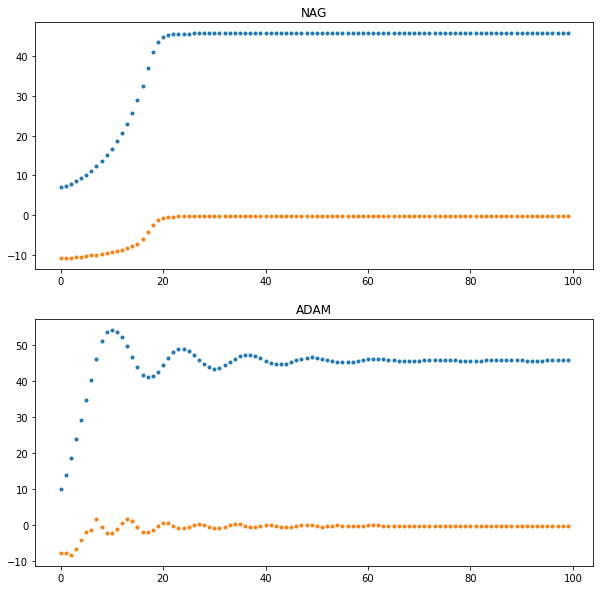
Tmax=100
plt.figure(figsize=(10,10))
plt.subplot(211)
plt.plot(ThetaNAG[:Tmax], '.')
plt.title('NAG')
plt.subplot(212)
plt.plot(ThetaADAM[:Tmax], '.')
plt.title('ADAM')
plt.show()
import matplotlib as mpl
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
import matplotlib.pyplot as plt
mpl.rcParams['legend.fontsize'] = 14
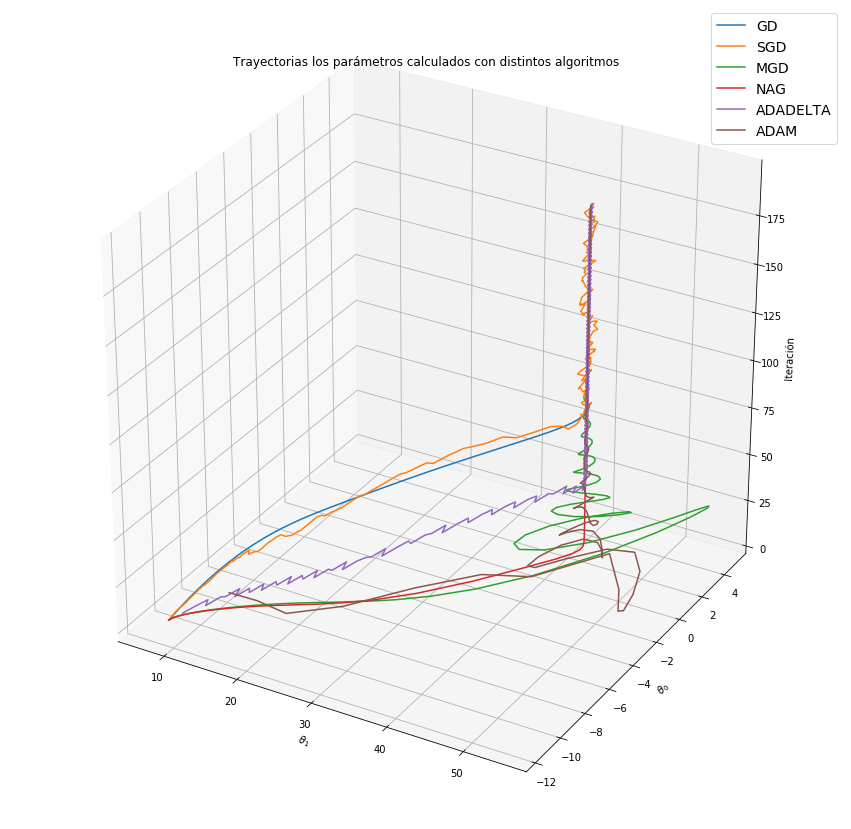
fig = plt.figure(figsize=(15,15))
ax = fig.gca(projection='3d')
nIter=np.expand_dims(np.arange(ThetaGD.shape[0]),1)
Tmax=200
ax.plot(ThetaGD[:Tmax,0], ThetaGD [:Tmax,1], nIter[:Tmax,0], label='GD')
ax.plot(ThetaSGD[:Tmax,0], ThetaSGD[:Tmax,1], nIter[:Tmax,0], label='SGD')
ax.plot(ThetaMGD[:Tmax,0], ThetaMGD[:Tmax,1], nIter[:Tmax,0], label='MGD')
ax.plot(ThetaNAG[:Tmax,0], ThetaNAG[:Tmax,1], nIter[:Tmax,0], label='NAG')
ax.plot(ThetaADADELTA[:Tmax,0], ThetaADADELTA[:Tmax,1], nIter[:Tmax,0], label='ADADELTA')
ax.plot(ThetaADAM[:Tmax,0], ThetaADAM[:Tmax,1], nIter[:Tmax,0], label='ADAM')
ax.legend()
ax.set_title(r'Trayectorias los parámetros calculados con distintos algoritmos')
ax.set_xlabel(r'$\theta_1$')
ax.set_ylabel(r'$\theta_0$')
ax.set_zlabel('Iteración')
plt.show()