%matplotlib inline
from sympy import*
init_printing()
x = Symbol('x')
y = Symbol('y')
z = Symbol('z')
Gradiente, Jacobiano y Hessiano
Derivada parcial
Calcular la derivada parcial de una función que depende de varias variables c.r.a (con respecto a) una variable, corresponde a calcular la derivada de la función respecto a esa variable asuminedo las demás constante. Esto es: ∂xi∂f(x1,x2,…,xi,…,xn)=defh→0limhf(x1,x2,…,xi+h,…,xn)−f(x1,x2,…,xi,…,xn).
O mas compacto ∂xi∂f(x)=defh→0limhf(x+hei)−f(x)
donde x=⎣⎢⎢⎢⎢⎡x1x2x3⋮xn⎦⎥⎥⎥⎥⎤
f = x**2+2*y**2+3*z**2-6*x**2*z +4*y*x +5*y*z**2-3*x*y*z
f
−6x2z+x2−3xyz+4xy+2y2+5yz2+3z2
diff(f,x)
−12xz+2x−3yz+4y
diff(f,z)
−6x2−3xy+10yz+6z
f = x**2+2*y**2+3*z**2
f
x2+2y2+3z2
El operador Gradiente ∇: ∇f(x)=def⎣⎢⎢⎢⎢⎢⎡∂x1∂f(x)∂x2∂f(x)∂x3∂f(x)⋮∂xn∂f(x)⎦⎥⎥⎥⎥⎥⎤
Podemos ver al gradiente, intuitivamente, que al operar sobre una función y la “expande” en un vector columna que contienen sus derivadas parciales.
Podemos ver intuitivamente el Jacobiano como un operador que “expande” cada renglón de la función vectorial f en sus derivadas parciales.
Luego si f≡f1: ∇f=Jf⊤
sbl = Matrix([x,y,z])
sbl
⎣⎡xyz⎦⎤
f = Matrix([f])
f
[x2+2y2+3z2]
G=f.jacobian(sbl).T
G
⎣⎡2x4y6z⎦⎤
Recordando la definición de Gradiente de f ∇f(x)=⎣⎢⎢⎢⎢⎢⎡∂x1∂f(x)∂x2∂f(x)∂x3∂f(x)⋮∂xn∂f(x)⎦⎥⎥⎥⎥⎥⎤
Matrix Hessiana o Hessiano de f:
El Hessiano es una matriz de segundas derivadas
Es simétrico si ∂xixj∂2f=∂xjxi∂2f,
esto es f es 2 veces continuamente diferenciable f∈C2.
Note que el Hessiano, se puede ver como aplicar el operador Jacobiano al Gradiente: Hf=defJ{∇f}=J{Jf⊤}
Sobre la Notación:
J{⋅} se refiere al operador
Jf se refiere a la Matrix
H = G.jacobian(sbl)
H
⎣⎡200040006⎦⎤
det(H)
48
Probablemente, nos sintamos mas cómodos calculando el gradiente con un operador especifico de Gradiente que con el de Jacobiano. Para tal caso, definimos lo siguiente
Hessiano se define como: ∇2f=def∇⊤∇f
Como en python no podemos indicarle al operador matrix.jacobian como haga la expansion. Nuestro Grad, siempre calculará derivadas por columnas asi que jugamos un poco con el orden de los operadores para implementrar el Hessiano.
Si f es dos veces continua y diferenciable, entonces tenemos ∇2f=(∇2f)⊤=(∇⊤∇f)⊤=∇∇f⊤
defHessian(f, variables):
g = Grad(f,variables)return Grad(g.T, variables)
Probemos nuestras implementaciones
from sympy import*
init_printing()
x1 = Symbol('x1')
x2 = Symbol('x2')
f =(x1 - x2)**2+ x1**3
f
x13+(x1−x2)2
Grad(f,'x1, x2')
[3x12+2x1−2x2−2x1+2x2]
Div(f,'x1 x2')
3x12
Hessian(f,'x1 x2')
[6x1+2−2−22]
Revisando propiedades de las derivadas que involucran Algebra Lineal
∇xy⊤x
from sympy import*
init_printing()from sympy import Matrix, latex, symbols
A = Matrix(symbols('a_1:4\,1:4')).reshape(3,3)
x = Matrix(symbols('x_1:4')).reshape(3,1)
y = Matrix(symbols('y_1:4')).reshape(3,1)(y.T*x).jacobian(x).T
Conjunto Convexo. Ω⊆Rn es un conjunto convexo si αx+(1−α)y∈Ω,∀x,y∈Ωy∀α∈[0,1]
Función Convexa. f:Ω→R es una función convexa si αf(x)+(1−α)f(y)≥f(αx+(1−α)y),,∀x,y∈Ω
y el dominio Ω es un conjunto convexo
f(x)=∣x∣
Función Estrictamente Convexa. f:Ω→R es una función convexa si αf(x)+(1−α)f(y)>f(αx+(1−α)y),,∀x,y∈Ω
y el dominio Ω es un conjunto convexo
f(x)=x2
Función que es una aproximación diferenciable al valor absoluto. Esta función aproxima al valor absoluto para x>>β f(x)=x2+β2
Optimalidad
Sea el problema de optimización xminf(x)
con x∈Rn y f∈C2.
Óptimo Global Estricto. x∗∈Rn es el óptimo global estricto si f(x∗)<f(y),∀y∈Rn.
Óptimo Global. x∗∈Rn es el óptimo global si f(x∗)≤f(y),∀y∈Rn.
Óptimo Local Estricto. x∗∈Rn es el óptimo local estricto si f(x∗)<f(y),∀y∈Nx∗; donde Nx∗ es una vecindad abierta que contine a x∗.
Óptimo Local o mínimo local (m.l). x∗∈Rn es el óptimo local si f(x∗)≤f(y),∀y∈Nx∗; donde Nx∗ es una vecindad abierta que contine a x∗.
Cuando implementamos algoritmos de optimización generalmente nos conformamos con encontrar un óptimo local como solución .
Dirección de Descenso
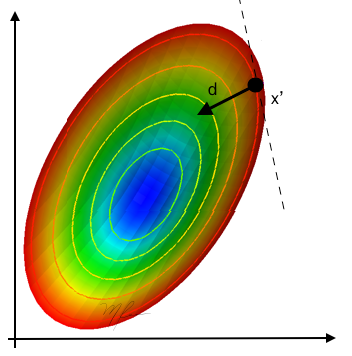
Dirección de descenso. d es una dirección de descenso en el punto x′ para el problema propuestonde optimización si partiendo de x’ en la dirección d podemos mejorar el valor de la función objetivo, esto es: f(x′+ϵd)<f(x′)
para una ϵ suficientemente pequeña (sfmp).
Para encontrar que condición cumple d, usamos expansión en serie de Taylor: f(x′)>f(x′+ϵd)=f(x′)+ϵ∇f(x′)⊤d+ϵ2d⊤∇2fd+…≈f(x′)+ϵ∇f(x′)⊤d.
Dado que ϵ es pequeño: ∣ϵ∣<∣ϵn∣ para n>1.
Luego restamos a ambos lados f(x′) y tenemos que:
La dirección de descenso d debe cumplir con ∇f(x′)⊤d<0
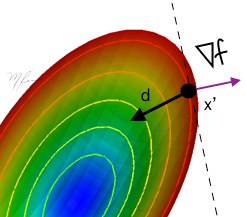
La línea punteada es tangente a la curva de nivel correspondiente a f en x′
El gradiente ∇f(x′) es normal a la curva de nivel y apunta en la dirección en que la función f crece.
Gráficamente, d debe estar en semiespacio opuesto a ∇f que es delimitado por la tangente a la curva de nivel de f en x′.
Condición de Optimalidad de Primer Orden
Asumimos el problema de optimización sin restricciones de una función suave.
Una solución (m.l.) x∗ al problema de optimización es un punto en el cual no existe una dirección de descenso. Esto es: ∄d:∇f(x∗)⊤d<0
Esto solo ocurre si: ∇f(x∗)=0
Condicion de optimalidad de primer orden. Si x∗ es un m.l. entonces ∇f(x∗)=0.
Si la funciónfes convexa, entonces el m.l. es mínimo global y el punto x∗ que satisfaga ∇f(x∗)=0 es solución global al problema de optimización
En los máximos también el gradiente se hace cero
Pensemos que queremos encontrar una dirección de ascenso b a partir del punto actual x′. Entonces b debe cumplit con: f(x′+ϵb)>f(x′)
para una ϵ suficientemente pequeña (sfmp).
Usamos expanción en serie de Taylor de 1er orden: f(x′)<f(x′+ϵd)≈f(x′)+ϵ∇f(x′)⊤d.
Como antes, restamos a ambos lados f(x′) y tenemos que una dirección de ascenso b debe cumplir con ∇f(x′)⊤b>0
Si x’ es un maximo local, entonces si existe una dirección de ascenso posible. La única forma de no entrar en contradicción con condición anterior, es que ∇f(x′)=0.
Condiciones de Optimalidad de Segundo Orden
En general (funciones no-convexas), la condición de optimalidad 1er orden es necesaria, pero no es suficiente para encontrar una solución.
Es decir, en un m.l. el gradiente se desvanece; pero también el gradiente se desvanece en otros puntos (máximos) que no son m.l.'s.
Para distinguir estos casos necesitamos la condiciones de segundo orden.
Condiciones de segundo orden sin restricciones
Sea el problema de optimización SIN restricciones
xminf(x)
La solución x∗ satisface la condición de optimalidad primer orden ∇xf(x∗)=0
Esto evita que un método de descenso actualice el punto óptimo: x∗←x∗−α∇xf(x∗)
Sin embargo, usiando la approximación de series de Taylor de segundo orden notamos que para ϵ suficientemente pequeña (sfmp): f(x∗+ϵp)=f(x∗)+ϵp⊤∇f(x∗)+21ϵ2p⊤∇2f(x∗)p=f(x∗)+21ϵ2p⊤∇2f(x∗)p
luego, dado que x∗ es óptimo: p⊤∇2f(x∗)p=ϵ22[f(x∗+ϵp)−f(x∗)]≥0,∀p.
Condición necesaria de segundo orden
TMA.
Si x∗ es solución del problema xminf(x)
Entonces, ∇f(x∗)=0 y el Hessiano ∇2f(x∗) en dicho óptimo es semidefinido positivo.
Proof.
De lo anteriormente visto tenemos p⊤∇2f(x∗)p≥0,∀p.
Condición suficiente de segundo orden
TMA. Sea el problema xminf(x)
con f suave (dos veces continuamente diferenciable)y x′ un punto en el cual
el gradiente ∇f(x′)=0 y
el Hessiano ∇2f(x′) es definido positivo;
entonces, x′ es un m.l. del problema de optimización.
Proof. Sea el punto x′ tal que ∇f(x′)=0 y p⊤∇2f(x′)p>0. Luego elegimos una bola abierta de radio r al rededor de x′ D={z:∥x′−z∥<r},
tal que ∇2f(x′) se mantenga definido positivo. Tomado un vector cualquier vector p tal que x′+ϵp∈D
Luego, para ϵ sfmp: f(x′+ϵp)=f(x′)+ϵp⊤∇f(x′)+2ϵ2p⊤∇2f(x′)p
Entonces, dado que:
∇f(x′)=0, y
ϵ2p⊤∇2f(x′)p>0;
tenemos que f(x′+ϵp)>f(x′),
por lo que x′ es un m.l.
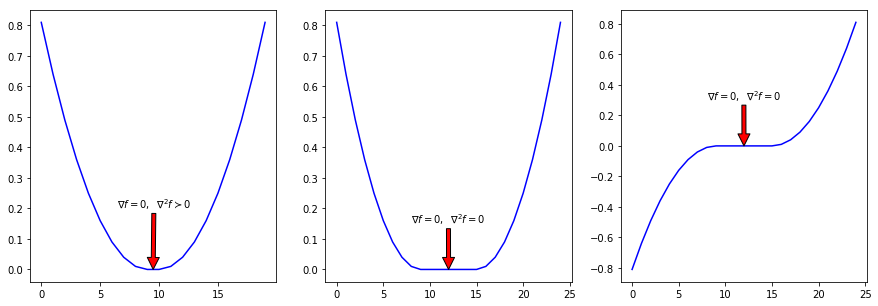
De los tres casos mostrados en la figura anterior, los dos promeros (de la izquierda) corresponden a mínimos locales (soluciones) y el tercero a un punto de mesa (no-solución).
La tercera gráfica (a la derecha) ilustra el porqué para evitar esta caso, en la condición suficiente de segundo orden tuvimos que asumir de inicio que el Hessiano era definido positivo en x′.
Lo que concluimos que:
si x∗ es óptimo, entonces cumple ∇f∗=0,∇2f∗⪰0 (condiciones necesarias)
si se cumple ∇f∗=0,∇2f∗≻0, entonces x∗ es óptimo (condiciones suficientes)