Seq2Seq : Modelos de redes recurrentes para transformar secuencias a secuencias
Mariano Rivera
Mayo 2020
Este tutorial usa el ejemplo de Keras ltsm-seq2seq. Código original del ejemplo disponible en git.
Recoratorio de Redes Neuronales Recurrentes (Recurrent Neural Networks, RNN)
A diferencia de las redes secuenciales donde cada entrada es procesada en forma independioente, sin tomar en cuenta la histora de datos procesados, una red recurrente utiliza información del procesamiento de datos pasados para calcular su respuesta a un nuevo dato.
Gráficamente, una red recurrente (RNN) se esquematiza por una retroalimentación de estados internos, ver la siguiente figura.
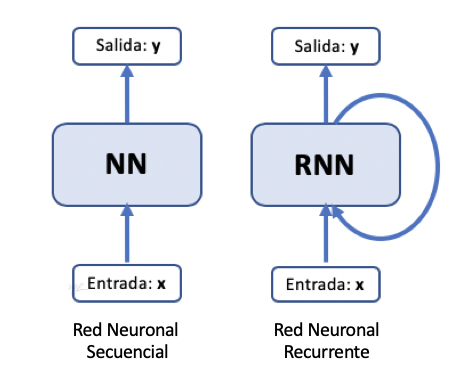
Podemos considera el modelo de red recurrente mas simple, donde la salida es el estado retroalimentado, esto se ve en el esquema de la figura siguiente.
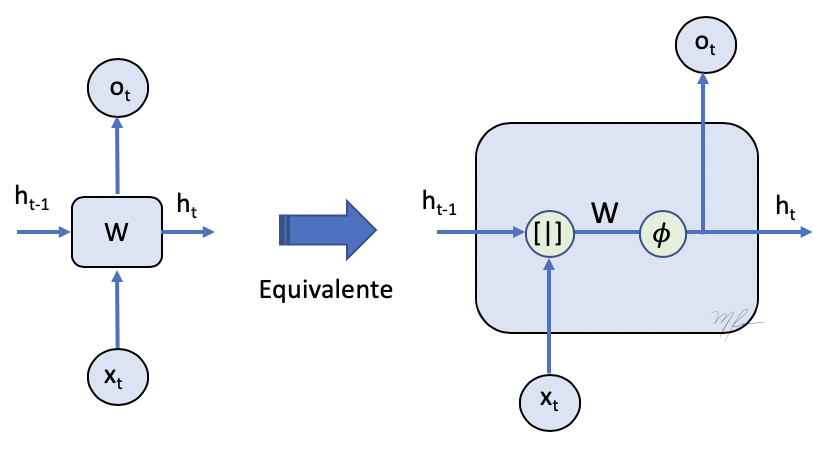
En este esquema, es una secuencia de entrada. Donde cada elemento de la secuencia es a la vez tensor. Además notemos que $o \equiv h $.
Entonces tenemos que el procesamiento hacia adelante de la secuencia estará dado por
(1)
donde debe ser inicalizado de alguna manera, tal vez con ceros. Luego
(2)
siguiendo con
(3)
Esto nos lleva a que podemos representar el procesamiento de la RNN eliminando las recurrencias por un esquema de procesamiento secuencial como el mostrado en la siguiente figura.
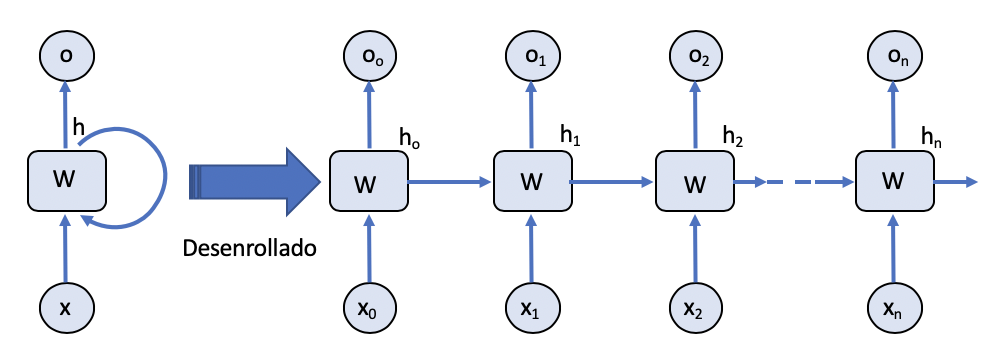
Esta forma desenrrollada de las redes recurrentes nos será útil para esquematizar y comprender el procesamiento que se realiza en el modelo Seq2Seq.
Seq2Seq a nivel caracter
Usaremos la base de datos de sentencias cortas en Inglés y Español que se puede descargar de manythings.org/anki.
Referencias
- Sequence to Sequence Learning with Neural Networks
- Learning Phrase Representations using
RNN Encoder-Decoder for Statistical Machine Translation
from __future__ import print_function
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Dense
import numpy as np
batch_size = 64
epochs = 20
latent_dim = 1024 # Dimension del espacio latente
num_samples = 120000 #20000 # número de muestran con las cuales entrenar
Lectura de los datos
# archivo con sentencias inglés-español
data_path = 'spa-eng/spa.txt'
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.read().split('\n')
print(60*'- ', f'\nTotal de pares de sentencias en el archivo: {len(lines)} \n', 60*'- ')
lines[4000:4020]
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Total de pares de sentencias en el archivo: 123771
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
['Are you angry?\t¿Estás enojada?\tCC-BY 2.0 (France) Attribution: tatoeba.org #476326 (FeuDRenais) & #4484505 (cueyayotl)',
'Are you awake?\t¿Estás despierta?\tCC-BY 2.0 (France) Attribution: tatoeba.org #1067015 (dominiko) & #1581045 (nancy)',
'Are you blind?\t¿Es usted ciego?\tCC-BY 2.0 (France) Attribution: tatoeba.org #2306578 (Hybrid) & #5099809 (don_ramon)',
'Are you blind?\t¿Está usted ciego?\tCC-BY 2.0 (France) Attribution: tatoeba.org #2306578 (Hybrid) & #5099811 (don_ramon)',
'Are you bored?\t¿Estás aburrido?\tCC-BY 2.0 (France) Attribution: tatoeba.org #1219521 (wallebot) & #1216443 (wallebot)',
'Are you bored?\t¿Te aburres?\tCC-BY 2.0 (France) Attribution: tatoeba.org #1219521 (wallebot) & #1216444 (wallebot)',
'Are you bored?\t¿Te estás aburriendo?\tCC-BY 2.0 (France) Attribution: tatoeba.org #1219521 (wallebot) & #1216447 (wallebot)',
'Are you crazy?\t¿Te has vuelto loco?\tCC-BY 2.0 (France) Attribution: tatoeba.org #20379 (CK) & #505856 (Shishir)',
'Are you crazy?\t¿Estás loco?\tCC-BY 2.0 (France) Attribution: tatoeba.org #20379 (CK) & #635932 (Leono)',
'Are you drunk?\t¿Estás borracho?\tCC-BY 2.0 (France) Attribution: tatoeba.org #1294262 (CK) & #1294329 (marcelostockle)',
'Are you drunk?\t¿Estás ebrio?\tCC-BY 2.0 (France) Attribution: tatoeba.org #1294262 (CK) & #3531100 (Aether)',
'Are you drunk?\t¿Estás embriagado?\tCC-BY 2.0 (France) Attribution: tatoeba.org #1294262 (CK) & #4371711 (pchamorro)',
'Are you funny?\t¿Eres gracioso?\tCC-BY 2.0 (France) Attribution: tatoeba.org #3172374 (CK) & #5544831 (Aruzen)',
'Are you going?\t¿Vas a ir?\tCC-BY 2.0 (France) Attribution: tatoeba.org #2244947 (CK) & #6600120 (arh)',
'Are you going?\t¿Va a ir usted?\tCC-BY 2.0 (France) Attribution: tatoeba.org #2244947 (CK) & #6600122 (arh)',
'Are you happy?\t¿Estás contento?\tCC-BY 2.0 (France) Attribution: tatoeba.org #16164 (CK) & #685492 (MondCivitano)',
'Are you happy?\t¿Eres feliz?\tCC-BY 2.0 (France) Attribution: tatoeba.org #16164 (CK) & #849798 (Shishir)',
'Are you happy?\t¿Sos feliz?\tCC-BY 2.0 (France) Attribution: tatoeba.org #16164 (CK) & #1061100 (hayastan)',
'Are you happy?\t¿Contento?\tCC-BY 2.0 (France) Attribution: tatoeba.org #16164 (CK) & #5046014 (don_ramon)',
'Are you happy?\t¿Es usted feliz?\tCC-BY 2.0 (France) Attribution: tatoeba.org #16164 (CK) & #5250824 (cueyayotl)']
El contenido del archivo spa.txt es como sigue
You're not sick. No estás enfermo. CC-BY 2.0 (France) Attribution: tatoeba.org #1841497 (CK) & #2019449 (Shishir)
You're not sick. No estás enferma. CC-BY 2.0 (France) Attribution: tatoeba.org #1841497 (CK) & #2019450 (Shishir)
You're prepared. Está preparado. CC-BY 2.0 (France) Attribution: tatoeba.org #2203221 (CK) & #7758316 (arh)
You're reliable. Usted es de fiar. CC-BY 2.0 (France) Attribution: tatoeba.org #1691831 (CK) & #1695297 (marcelostockle)
Es decir, sige el formato:
Sentencia en Inglés + TAB + Sentencia en Español + TAB + Crédito
Vectorización de los datos
Obtenemos de cada línea las sentencias y construimos dos conjuntos de caractéres. Uno para lso que conforman las sentencias de entrada y otras las objetivo.
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()
for line in lines[: min(num_samples, len(lines) - 1)]:
input_text, target_text, _ = line.split('\t') # cada elemento de la línea es separado por '\t'
target_text = '\t' + target_text + '\n' # agregamos inicio ('\t') y fin ('\n') de secuencia
input_texts.append(input_text)
target_texts.append(target_text)
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
print(f'Conjunto (Set) de caracteres que conforman las sentencias de entrada: \n{input_characters} \n')
print(f'Conjunto (Set) de caracteres que conforman las sentencias objetivo: \n{target_characters}')
Conjunto (Set) de caracteres que conforman las sentencias de entrada:
{'g', '!', '%', ',', 'L', 'e', '?', 't', 'j', 'b', 'Z', 'o', '0', 'ü', 'h', 'S', 'D', '₂', 'y', 'G', 'c', '/', 'm', '9', '‘', '3', 'P', 'w', 'U', 'ö', ';', 'K', 'F', 'X', 'B', 'M', 'Y', 'd', 'H', 's', 'ã', '8', "'", 'f', '$', '"', 'a', '4', 'T', 'V', '\xa0', 'N', 'x', 'Q', 'l', '-', 'J', '6', 'z', 'è', '.', 'k', 'ê', 'I', 'r', 'n', 'q', 'C', 'á', '7', ' ', 'v', 'u', '2', ':', 'O', 'é', 'W', 'p', 'i', 'A', 'E', '1', '5', '°', 'R', '’', '€'}
Conjunto (Set) de caracteres que conforman las sentencias objetivo:
{'g', '!', '%', 'Á', '—', '\t', 'ñ', 'í', ',', 'L', 'e', '?', 't', 'É', 'j', 'b', 'Z', 'o', 'с', '0', 'ü', 'h', '(', 'S', 'D', '₂', 'y', 'G', 'c', '/', 'm', '9', '3', 'P', 'w', 'U', 'º', 'ö', '´', '¡', ';', 'K', 'F', 'X', 'B', 'M', 'Y', 'd', 'H', 's', '»', 'ś', '8', '¨', '«', "'", 'f', '$', '"', 'a', '4', 'T', 'V', 'N', 'x', '+', 'Q', '-', 'l', 'J', '6', 'z', 'è', '.', 'ú', 'k', 'ê', 'I', 'r', 'n', 'q', '¿', 'C', 'á', '7', ')', ' ', 'v', 'u', '2', ':', 'O', 'ó', 'é', '\n', 'Ó', 'W', 'p', 'Ú', 'i', 'A', 'E', '1', '5', '\u200b', '°', 'R', '€'}
Lo desplegamos ordenado para mejor visualización
print(sorted(list(target_characters)))
['\t', '\n', ' ', '!', '"', '$', '%', "'", '(', ')', '+', ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '¡', '¨', '«', '°', '´', 'º', '»', '¿', 'Á', 'É', 'Ó', 'Ú', 'á', 'è', 'é', 'ê', 'í', 'ñ', 'ó', 'ö', 'ú', 'ü', 'ś', 'с', '\u200b', '—', '₂', '€']
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
print(f'Número de caractéres en el idioma fuente: {num_encoder_tokens}')
print(f'Número de caractéres en el idioma objetivo: {num_decoder_tokens}')
Número de caractéres en el idioma fuente: 88
Número de caractéres en el idioma objetivo: 108
max_encoder_seq_length = max([len(txt) for txt in input_texts])
max_decoder_seq_length = max([len(txt) for txt in target_texts])
print('Longitud máxima de sentencia en el idioma fuente:', max_encoder_seq_length)
print('Longitud máxima de sentencia en el idioma destino:', max_decoder_seq_length)
Longitud máxima de sentencia en el idioma fuente: 61
Longitud máxima de sentencia en el idioma destino: 103
Creación de diccionarios con los caractéres de ambos idiomas
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])
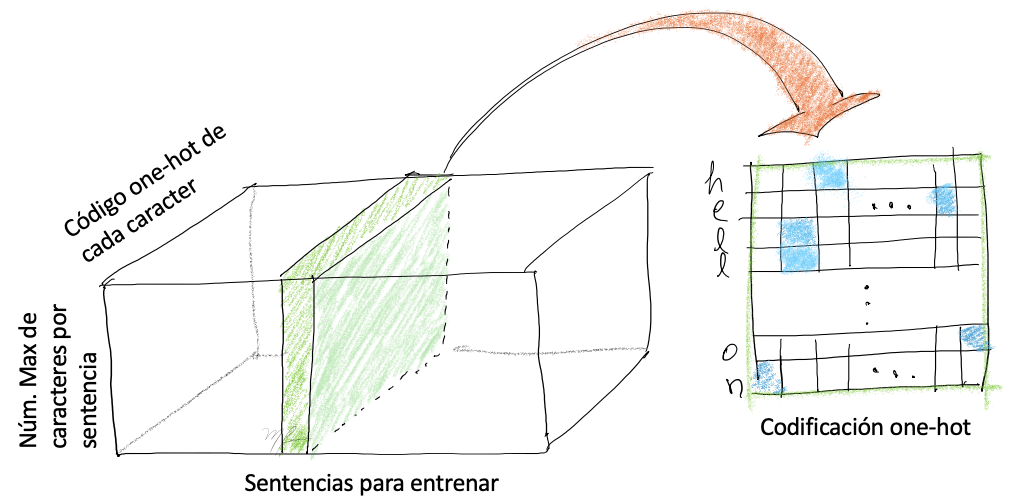
Cada sentencia en la la base de datos se transforma en tres arreglos:
-
encoder_input_data. Arreglo tridimensional para entrada de(num_pairs, max_english_sentence_length, num_english_characters)que contienen la codificación one-hot de cada caracter. -
decoder_input_dataArreglo tridimensional para salida de(num_pairs, max_spanish_sentence_length, num_spanish_characters)que contienen la codificación one-hot de cada caracter. -
decoder_target_dataigual adecoder_input_datapero recorrido un paso; sidecoder_target_data[:, t, :]entoncesdecoder_input_data[:, t + 1, :].
encoder_input_data = np.zeros((len(input_texts),
max_encoder_seq_length,
num_encoder_tokens), dtype='float32')
decoder_input_data = np.zeros((len(input_texts),
max_decoder_seq_length,
num_decoder_tokens), dtype='float32')
decoder_target_data = np.zeros((len(input_texts),
max_decoder_seq_length,
num_decoder_tokens), dtype='float32')
Codificación de cada sentecia de entrada y destino.
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
# codificación de la secuencia de entrada
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.
encoder_input_data[i, t + 1:, input_token_index[' ']] = 1.
# codificación de la secuencia de salida
for t, char in enumerate(target_text):
# esta secuencia tienen un caracter antes, el tab
decoder_input_data[i, t, target_token_index[char]] = 1.
if t > 0:
# El target quitando el caracter de inicial (tab)
# con ello se "adelanta", un paso en el tiempo a `decoder_input_data`
decoder_target_data[i, t - 1, target_token_index[char]] = 1.
decoder_input_data[i, t + 1:, target_token_index[' ']] = 1.
decoder_target_data[i, t:, target_token_index[' ']] = 1.
Sentencia codificada: cada renglón corresponde a un caractér codificado en one-hot
import matplotlib.pyplot as plt
print(f'Última secuencia leida en el idioma fuente: {input_text}')
Última secuencia leida en el idioma fuente: I figured you wouldn't want to drink coffee so late at night.
import matplotlib.pyplot as plt
print(f'Última secuencia leida en el idioma fuente: {target_text}')
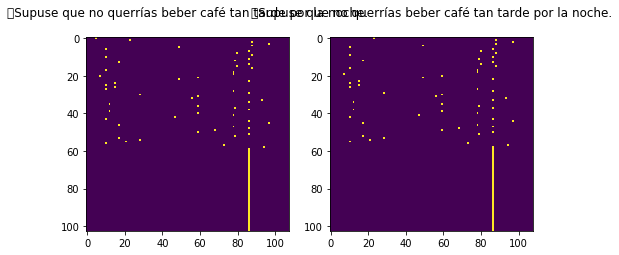
plt.figure(figsize=(8,4))
plt.subplot(121)
plt.imshow(decoder_input_data[-1])
plt.title(target_text)
plt.subplot(122)
plt.imshow(decoder_target_data[-1])
plt.title(target_text)
plt.show()
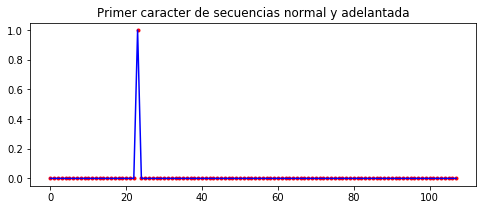
plt.figure(figsize=(8,3))
plt.plot(decoder_input_data[-1][1], '.r')
plt.plot(decoder_target_data[-1][0], 'b')
plt.title('Primer caracter de secuencias normal y adelantada')
plt.show()
Última secuencia leida en el idioma fuente: Supuse que no querrías beber café tan tarde por la noche.
import matplotlib.pyplot as plt
plt.imshow(decoder_target_data[-1])
plt.title(target_text)
plt.show()
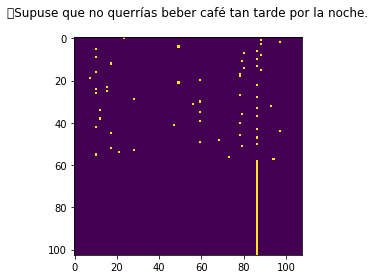
Si quisieramos ver en que posiciones se encuentra un caracter particular (digamos ‘a’) en la última secuencia, hacemos:
print(encoder_input_data[-1,:,input_token_index['a']])
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
1. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
Que implica que esta en los índices 1 y 9.
Modelo seq2seq con LSTM. Modo Entrenamiento
Codificador (encoder)
LSTM con latent_dim variables latentes, abajo los parametros por omisión (default) más relevantes de la una LSTM.
tf.keras.layers.LSTM(
units,
activation = 'tanh',
recurrent_activation = 'sigmoid',
use_bias = True,
dropout = 0.0,
return_sequences = False,
return_state = False,
unroll = False
)
Donde
-
units: dimensión del espacio de salida -
return_state: indica si se regresa o no estado interno junto con la salida. Sireturn_state=Truese regresa una lista de tensores, el primer tensor es la salida y los restantes son lós últimos estados.
En la figura siguiente se muestra el esquema de una unidad LSTM, en ella se observan que de una unidad a otra se pasa la información correspondiente a la salida y al estado interno.
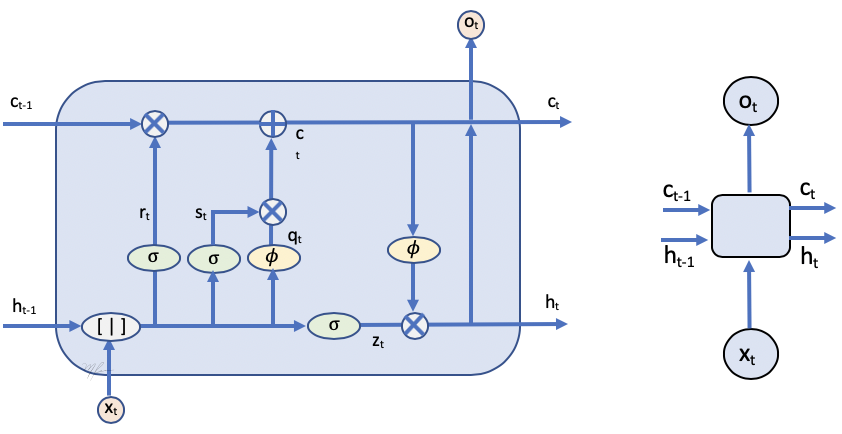
La salida de una unidad es . Con return_state=True, se estarán devolviendo también los estado ocultos internos: la salida de la última unidad y el canal de memoria . Note que la salida será dada por y es igual al estado oculto .
Si además eligieramos return_sequences=True, entonces la salida serán el vector de todas las salidas y los estados ocultos de salida sequiran siendo y .
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder_o, encoder_h, encoder_c = LSTM(units = latent_dim,
return_state = True)(encoder_inputs)
# Descartamos la salida y conservamos los estados internos
encoder_states = [encoder_h, encoder_c]
print(encoder_inputs.shape)
print(encoder_o.shape, encoder_h.shape, encoder_c.shape)
(None, None, 88)
(None, 1024) (None, 1024) (None, 1024)
Gráficamente, el codificador se representa por la siguiente figura.

Decodificador (Decoder)
Puntos a considerar para implementar el decodificador:
-
Para el decodificador usaremos de nuevo una LSTM.
-
La entrada del decodificador es la salida del decodificador.
-
El estado inicial (de la primera etapa) del decodificador estará dado por los estados internos del decodificador
-
El decodificador debe regresar la secuencia completa.
-
Usaremos el estado interno del la última etapa del decodificador para la inferencia.
-
Se agrega una capa densa a la salida para obtener la secuencia codificada (relajación de hot-dense en forma de probabilidad).
El decodificador se puede representar gráficamente por la siguiente figura.

# la entrada son secuencias de caracteres del idioma destino, codificados en one-hot
decoder_inputs = Input(shape=(None, num_decoder_tokens))
layer_lstm = LSTM(units = latent_dim,
return_sequences = True,
return_state = True)
decoder_O, _, _ = layer_lstm (decoder_inputs,
initial_state=encoder_states)
layer_dense = Dense(units = num_decoder_tokens,
activation = 'softmax')
decoder_outputs = layer_dense(decoder_O)
Note que hemos cambiado la notación del API de keras de lo acostrumbrado:
X2 = Dense(units=32)(X1)
a la forma
F = Dense(units=32)
X2 = F(X1)
Esto es porque construiremos un modelo de decodificador para entrenamiento y luego haremos modelo con modificaciones para inferencia. Pero queremos reusar los pesos ya entrenados y no complicarlos con hacer la translación de los mismos al modelo para inferencia.
print(decoder_inputs.shape, decoder_O.shape, encoder_states[0].shape, encoder_states[1].shape)
print(decoder_outputs.shape)
(None, None, 108) (None, None, 1024) (None, 1024) (None, 1024)
(None, None, 108)
modelo seq2seq
Combina el desde la entrada del codificador y hasta la salida del decodificador.
model = Model(inputs = [encoder_inputs, # secuencia en idioma fuente
decoder_inputs], # secuencia en idioma destino
outputs = decoder_outputs) # predicción adelantada en idioma
model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, None, 88)] 0
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, None, 108)] 0
__________________________________________________________________________________________________
lstm (LSTM) [(None, 1024), (None 4558848 input_1[0][0]
__________________________________________________________________________________________________
lstm_1 (LSTM) [(None, None, 1024), 4640768 input_2[0][0]
lstm[0][1]
lstm[0][2]
__________________________________________________________________________________________________
dense (Dense) (None, None, 108) 110700 lstm_1[0][0]
==================================================================================================
Total params: 9,310,316
Trainable params: 9,310,316
Non-trainable params: 0
__________________________________________________________________________________________________
Entrenamiento (training)
model.compile(optimizer = 'rmsprop',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard
my_callbacks = [EarlyStopping(patience=2),
ModelCheckpoint(filepath='seq2seq_en2sp.{epoch:04d}-{val_loss:.2f}.h5'),
TensorBoard(log_dir='./logs'),]
model.fit(x = [encoder_input_data, # secuencia en idioma fuente
decoder_input_data], # sec. en idioma destino
y = decoder_target_data, # sec. en idioma destino adelantada 1 caracter
batch_size = batch_size,
epochs = epochs,
shuffle = True,
validation_split=0.2,
callbacks = my_callbacks)
model.save('seq2seq_en_es.h5')
Train on 96000 samples, validate on 24000 samples
Epoch 1/20
96000/96000 [==============================] - 100s 1ms/sample - loss: 0.5530 - accuracy: 0.8404 - val_loss: 0.6922 - val_accuracy: 0.7888
Epoch 2/20
96000/96000 [==============================] - 104s 1ms/sample - loss: 0.3145 - accuracy: 0.9037 - val_loss: 0.5633 - val_accuracy: 0.8282
Epoch 3/20
96000/96000 [==============================] - 106s 1ms/sample - loss: 0.2623 - accuracy: 0.9190 - val_loss: 0.5311 - val_accuracy: 0.8380
Epoch 4/20
96000/96000 [==============================] - 106s 1ms/sample - loss: 0.2335 - accuracy: 0.9276 - val_loss: 0.5006 - val_accuracy: 0.8488
Epoch 5/20
96000/96000 [==============================] - 108s 1ms/sample - loss: 0.2105 - accuracy: 0.9347 - val_loss: 0.4958 - val_accuracy: 0.8517
Epoch 6/20
96000/96000 [==============================] - 108s 1ms/sample - loss: 0.1929 - accuracy: 0.9401 - val_loss: 0.5056 - val_accuracy: 0.8517
Epoch 7/20
96000/96000 [==============================] - 109s 1ms/sample - loss: 0.1781 - accuracy: 0.9447 - val_loss: 0.5110 - val_accuracy: 0.8527
Inferencia en Seq2Seq
Hemos entrenado el modelo Seq2seq, sin embargo no pueed cser usado directamente para hacer inferencia. Para empezar, usamos como datos de entrada (decoder_input_data) la secuencia en el idioma destino, está no estará diponible en la inferencia.
Los puntos a considerar son:
- El Codificador permanece sin cambios
encoder_model = Model(encoder_inputs, encoder_states)
- El Decodificador
La forma de transformar una secuencia es codificando la información semántica en forma completa por el codificador y luego pasar los estados ocultos de salida al decodificador para que los decodifique caracter por caracter generando asi la nueva secuencia.
-
Ahora si usamos los estados que resultan de la red LSTM (decoder_H, decoder_C ), pues se usarán para pasar de un caracter al siguiente.
-
El decodificador tienen como estado inicial los estados de salida del codificador.
-
La entrada al decodificador será el anterior caracter predicho por el mismo, inicializando con el caracter de inicio de secuencia
'\t'.
Entradas al decodificador
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
Note que usaremos la capa layer_lstm que ha sido entrenada previamente.
decoder_O, state_H, state_C = layer_lstm(decoder_inputs,
initial_state=decoder_states_inputs)
Igual pasa con la densa de decodificación.
decoder_outputs = layer_dense(decoder_O)
Este nuevo modelo lo usaremos para traducir secuencias, no para entrenar. Es necesario que definamos en inputs y en outputs la forma correcta en que el decodificador recibirá las entradas.
-
Como entrada una tensor para cuyo modelo (tamaño) nos sirve de entrada
decoder_inputsy los estados de salida del encoder. -
Como salida produce una secuencia predicha adelantada y sus estados de salida.
decoder_model = Model(inputs = [decoder_inputs] + decoder_states_inputs, # concatenación de listas
outputs = [decoder_outputs] + [state_H, state_C])
# Crea los diccionario invertidos de {caracter : idx} a {idx : caracter} para decodificar
reverse_input_char_index = dict((i,char) for char, i in input_token_index.items())
reverse_target_char_index = dict((i,char) for char, i in target_token_index.items())
def decode_sequence(input_seq):
# -------------------------------------------------------------------------------
# Codifica toda la secuencia de entrada en vectores de estados [state_c, state_h]
# -------------------------------------------------------------------------------
states_value = encoder_model.predict(input_seq)
# -------------------------------------------------------------------------------
# Decodificamos `state_values` caracter por caracter a la secuencia de salida
# -------------------------------------------------------------------------------
# Genera una secuencia resultante vacia de longitud 1 (adelantada)
target_seq = np.zeros((1, 1, num_decoder_tokens))
# Llena la primera secuencia con el caracter de inicio de secuencia
target_seq[0, 0, target_token_index['\t']] = 1.
stop_condition = False
decoded_sentence = ''
while not stop_condition:
# Predice un caracter a la vez para la secuencia de salida (en one-hot)
output_token, state_H, state_C = decoder_model.predict([target_seq]+ states_value)
# Decodifica de one-hot a caracter
sampled_token_index = np.argmax(output_token[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# Fin de procesamiento de secuencia ('\n' o se alcanzó la longitud máxima)
if (sampled_char == '\n' or len(decoded_sentence) > max_decoder_seq_length):
stop_condition = True
# Actualiza la entrada al decodificador para la siguiente prediccion
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# actualiza estados
states_value = [state_H, state_C]
return decoded_sentence
print('Sentencia en Inglés --> Traducción por la red Seq2Seq al Español')
# Decodifica una por una de secuencias del conjunto de entrenamiento
for seq_index in range(100):
# secuencia codificada en one-hot
input_seq = encoder_input_data[seq_index: seq_index + 1]
# transformada por el modelo y decodificada caracter a caracter.
decoded_sentence = decode_sequence(input_seq)
# despliega resultados
print(input_texts[seq_index], ' --> ', decoded_sentence)
Sentencia en Inglés --> Traducción por la red Seq2Seq al Español
Go. --> Ve a casa.
Go. --> Ve a casa.
Go. --> Ve a casa.
Go. --> Ve a casa.
Hi. --> Su casa es como un animal.
Run! --> Correg, tengo caro.
Run! --> Correg, tengo caro.
Run! --> Correg, tengo caro.
Run! --> Correg, tengo caro.
Run. --> Correg, tengo caro.
Who? --> ¿Quién te ha dicho?
Wow! --> ¡Que algo!
Fire! --> Los niños no pueden ver.
Fire! --> Los niños no pueden ver.
Fire! --> Los niños no pueden ver.
Help! --> Ayúdame a escribir.
Help! --> Ayúdame a escribir.
Help! --> Ayúdame a escribir.
Jump! --> Los hombres son iguales.
Jump. --> Los hombres son amigos.
Stop! --> Deja de molestarme.
Stop! --> Deja de molestarme.
Stop! --> Deja de molestarme.
Wait! --> Espera un momento.
Wait. --> Espera un momento.
Go on. --> Ve a casa.
Go on. --> Ve a casa.
Hello! --> Ayúdame a escuchar.
I hid. --> Ojalá el plan.
I hid. --> Ojalá el plan.
I hid. --> Ojalá el plan.
I hid. --> Ojalá el plan.
I ran. --> Yo lo amo.
I ran. --> Yo lo amo.
I try. --> Intenté hacerlo.
I won! --> Me pregunto por qué.
Oh no! --> ¡Oh, no!
Relax. --> Lea el presupuesto.
Shoot! --> ¿Debería ser famoso?
Shoot! --> ¿Debería ser famoso?
Shoot! --> ¿Debería ser famoso?
Shoot! --> ¿Debería ser famoso?
Shoot! --> ¿Debería ser famoso?
Shoot! --> ¿Debería ser famoso?
Smile. --> Se acabó el dinero.
Attack! --> Al final, Tom no se lo contó.
Attack! --> Al final, Tom no se lo contó.
Attack! --> Al final, Tom no se lo contó.
Attack! --> Al final, Tom no se lo contó.
Attack! --> Al final, Tom no se lo contó.
Get up. --> Aléjate de eso.
Go now. --> Ve a casa.
Go now. --> Ve a casa.
Go now. --> Ve a casa.
Go now. --> Ve a casa.
Go now. --> Ve a casa.
Go now. --> Ve a casa.
Go now. --> Ve a casa.
Go now. --> Ve a casa.
Got it! --> Ve a casa.
Got it? --> Ve a casa.
Got it? --> Ve a casa.
He ran. --> Él se casó con un estudiante.
Hop in. --> Los conocidos de la lista de la pistalla.
Hug me. --> Abre la ventana.
I care. --> Le pregunté a Tom.
I fell. --> Me sentía como un edefecio.
I fled. --> Me encanta el café.
I fled. --> Me encanta el café.
I fled. --> Me encanta el café.
I fled. --> Me encanta el café.
I know. --> Sé que estoy aquí.
I left. --> Dejé la puerta.
I lied. --> Le mandaré.
I lost. --> Perdí mi reloj.
I quit. --> Yo confío en él.
I quit. --> Yo confío en él.
I quit. --> Yo confío en él.
I sang. --> Le vi hacerlo.
I wept. --> Perdí el tren.
I wept. --> Perdí el tren.
I work. --> Trabajo en casa.
I'm 19. --> Estoy a su lado.
I'm up. --> Estoy a su lado.
Listen. --> Escucha.
Listen. --> Escucha.
Listen. --> Escucha.
No way! --> Ahora es hora de comer.
No way! --> Ahora es hora de comer.
No way! --> Ahora es hora de comer.
No way! --> Ahora es hora de comer.
No way! --> Ahora es hora de comer.
No way! --> Ahora es hora de comer.
No way! --> Ahora es hora de comer.
No way! --> Ahora es hora de comer.
No way! --> Ahora es hora de comer.
No way! --> Ahora es hora de comer.
Really? --> Lea el presupuesto.
Really? --> Lea el presupuesto.
Thanks. --> Gracias.
Como podemos notar, muc has de las frases cortas son equivocadamente traducidas. Esto se debe a que nuestra base de datos es muy limitada, como estamos generando caracter por caracter, la información que es codificada en los estados de salida del codificador, no contiene el suficiente contexto para reconstruir la el sentido de la frase original.
A pesar de la evidente limitación del traductor, es realmente muy interesante el que las palabras generadas caracter por caracter sean, en su gran mayoría, del español; y las que no son similares: Correg, Pistalla,…
Un mejor resultado, aunque seguirá siendo limitado, es hacer generación de la traducción palabra x palabra. Para ello debemos, codificar cada palabra como token. Aunque este enfoque mejora la traducción, seguirá limitado a sentencias cortas, por ello es recomendable implementar un esquema de atención.