[1] R. Pascanu et al., On the difficulty of training recurrent neural networks. In Proc. ICML’13, vol 28, pp III–1310–III–1318, (2013)
En problema conocido del entrenamiento de las redes recurrentes en el llamado Gradiente Evanescete (vanish gradient). [1]
Para analizar dicho problema, primero usaremos un ejemplo con la finalidad de motivar el problema.
Suponga que hemos entrenado una red para completar oraciones y la entrenamos con oraciones como la siguiente:
Al gato la gusta jugar con los niños, …, descansar en su cojín y comer pescado
Donde ‘…’ significan que hay varias palabras mas.
Luego le pedimos a la red predecir la siguiente palabra en la siguiente oración:
*Al perro la gusta jugar con los niños, …, descansar en su cojín y comer ________ *
Y la red predice pescado, cuando esperabamos huesos.
¿Que fué lo que pasó? ¿En que falló el entrenamiento? Bueno, pues la palabra que define de quién estamos hablando (gato o perro) está al inicio de la oración, y la red tiene memoria corta. Esto es, nuestra red no es muy buena para recordar datos importantes por mucho tiempo.
La razón es que en las redes recurrentes el efecto en la salida de los palaras se desvanece rápidamente. Es decir, modificar las palabras iniciales de la oración tienen muy poco efecto (si no es que nulo) en la última salida de la RNN.
Esto implica que el el cambio en el costo de la última predicción se desvanece conforme los términos son más tempranos: el gradiente se desvanece rápidamente en el tiempo. Matemáticamente, esto se escribe como
(1) ∂xk∂E(ot,Ot)⏐⏐⏐↑t−k≈0
Donde ot es la salida de la RNN para el tiempo t y Ot es la salida esperada (usada en el entrenamiento supervisado) y xk es una entrada muy distante en el tiempo.
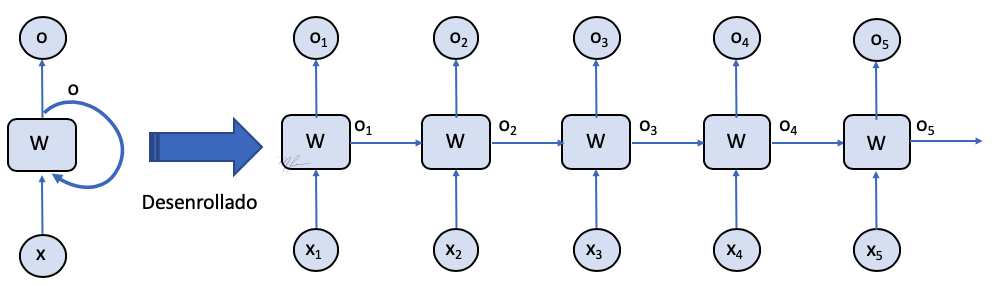
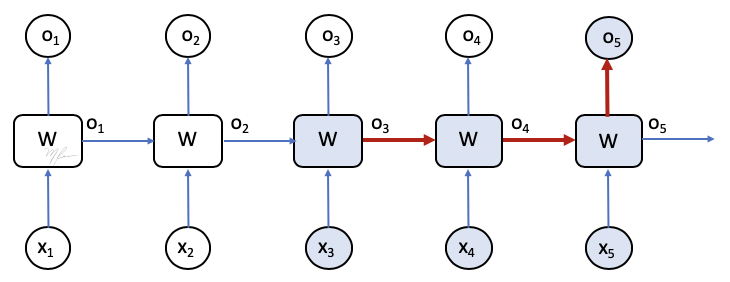
Para analizar esto, asumamos una RNN muy simple, como la de la siguiente figura.
Donde la celda esta definida por la simple función de transformación:
(2) ot=ϕ(Wxxt+Woot−1+b)
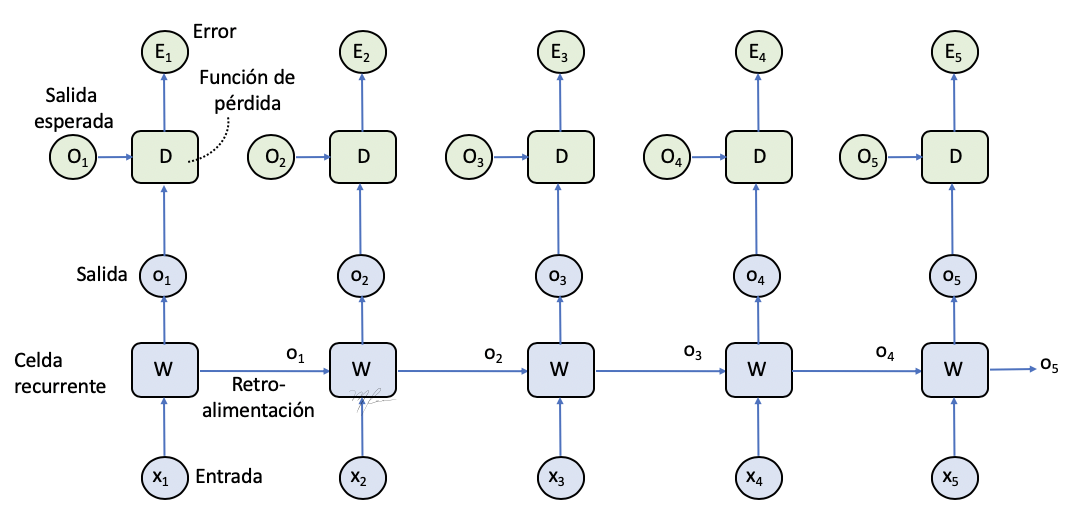
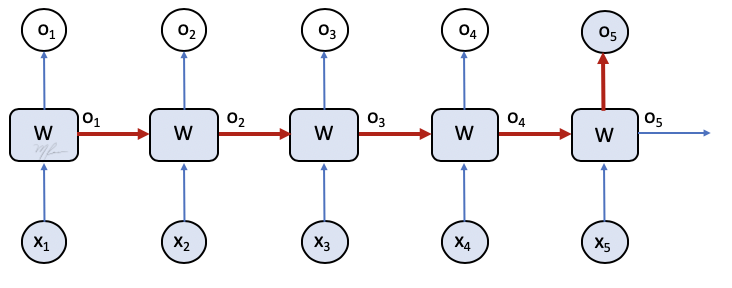
Donde ϕ es una función de activación y definimos W=[Wx,Wo,b]. Luego agregamos, gráficamente, la etapa de cálculo del error. Entonces la RNN se ve como
Donde, Et es el error entre la predicción ot y la salida esperada Ot considerando la t-ésima entrada xt y la retroalimentación ot−1.
Luego, el error total cometido esta dado por
(3) E=t=0∑TEt
y el gradiente de la función de error respecto a los parámetros W es
(4) ∇WE=def∂W∂E=t=0∑T∂W∂Et
que es la suma de las contribuciones de cada salida al gradiente.
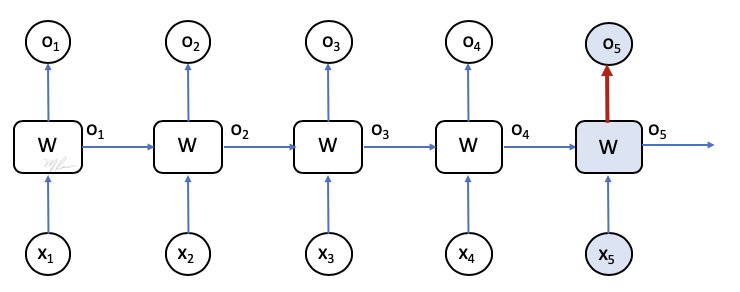
Por lo pronto, consideremos sólo la salida final,
1 Notamos que un cambio en W afectará directamente a o5. Gráficamente: se ilustra en la figura siguiente.
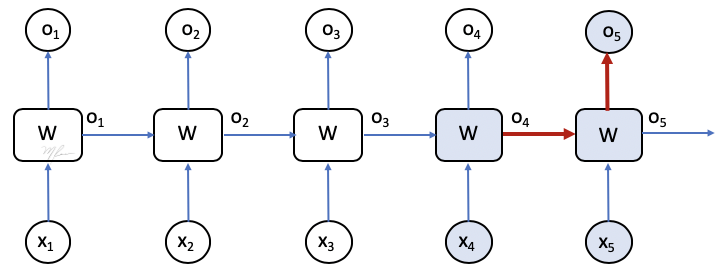
2 Sin ambargo, la entrada o4 a la última celda también se ve afectada por un cambio en W.
3 Que a su vez se ve afectada por un cambio en o3 inducido por el cambio en W.
De hecho, por la naturaleza recursiva de nuestra red, un cambio en W afecta directamente todas las salidas de la red, y este cambio se propaga a través del canal de memoria.
Entonces el gradiente en la salida t-ésima esta dado por
(5) ∂W∂Et=∂ot∂Et∂W∂ot+∂ot∂Et∂ot−1∂ot∂W∂ot−1+∂ot∂Et∂ot−1∂ot∂ot−2∂ot−1∂W∂ot−2+∂ot∂Et∂ot−1∂ot∂ot−2∂ot−1∂ot−3∂ot−2∂W∂ot−3+∂ot∂Et∂ot−1∂ot∂ot−2∂ot−1∂ot−3∂ot−2∂ot−4∂ot−3∂W∂ot−4+…Cambio directamente en la celda final tCambio inducido por la celda previa t−1Cambio inducido por la celda ante-previa t−2Cambio inducido por la celda t−3Cambio inducido por la celda t−4Cambio inducido por el resto de las celdas
que podemos reescribirlo como
(6) ∂W∂Et=k=1∑t∂ot∂Et∂ok∂ot∂W∂ok
Donde hemos definido
(7) ∂ok∂ot=defi=k∏t−1∂oi−1∂oi
(Wo)t−k−1, que consiste en elevar a una potencia la matriz Wo. Si la matriz Wo contienen únicamente términos ∣[Wo]ij∣<1, al elevarlos a potencias grandes (para k<<t), se harán mas pequeños y la contribución de la entrada [xk,ok−1,1] en ot se desvanecerá.
Podemos factorizar W=UDV⊤ usando descomposición en valores singulares (Singular Value Decompossition, SVD). Donde D es una matriz diagonal con los valores singulares y U, V som matrices unitarias (U⊤U=UU⊤=I y V⊤V=VV⊤V=I). Luego Wn=Wn−2W⊤W=Wn−2VD2V⊤. Note que este producto pueded cambiar si elegimos multiplicar por la izquierda y si n es par o impar; pero lo escencial es que el producto es de la forma Wn=ADnB (con A,B∈{U,U⊤,V,V⊤}. Donde Dn significa que cada valor singular es elevado a la potencia n. Si n>>0 y Dii<0, entonces Diin≈0. y Wn≈0.
∏i=kt−1ϕ′, si asumimos que ϕ(z)=tanh(z), entonces ϕ∈(−1,1). Luego ϕ′=1−ϕ2 con ϕ′∈(0,1). Consecuentemente, ∏i=kt−1ϕ′≈0 para k<<t.
Por ello, las RNN no pueden usar términos tempranos k para construir respuestas a tiempos muy distantes t (con k<<t).
El Problema de la Explosión del Gradiente
En redes profundas no recurrentes se ha visto otro problema asociado con el producto de gradientes.
Si la matriz Wo contienen únicamente términos ∣[Wo]ij∣>1 y el producto (potencia)de matrices crece más rapidamente que el producto de las parciales. Entonces, el gradiente explotará hacendose extremadamente grande y provocando el llamado problema de Explosión del Gradiente [2], que es el opuesto al de Gradiente Evanescente y generalmente se resuelve mediante:
Regularizando (penalizando) los pesos W con norma L1 o L2.
Recortando gradientes excesivamente grandes.
Truncando backpropagation cundo hay gradientes grandes.
[2] Y. Bengio et al., The Problem of Learning Long-Term Dependencies in Recurrent Networks, Neural Networks for Computing Conference, 1993.