Incruste de Palabras (Word Embedding)
Mariano Rivera
version 1.1
marzo 2020
import keras
keras.__version__
Using TensorFlow backend.
'2.1.4'
En este tutorial usamos como ejemplo el código de la sección 1 del Capítulo 6 en Deep Learning with Python, Chollet.
Incruste
Un incruste, o encaje, es en términos matemáticos una instancia de estructura matemáticas contenida en otra instancia.
Esto es, es puede ser una variedad, campo, grafo, etc y se mapea a otro espacio donde la estructura se preserva. ¿Cuál estructura? ¿Se requerirá a la distancia? ¿La conectividad topológica? ¿orden? En realidad, la que sea de nuestro interés.
Si la instancia original esta dada por , entonces la incrustación esta dada por
(1)
tal que es una función que preserva la estructura de conectividad o algebraica.
En nuestro caso usaremos un incruste para transformar las palabras a vectores tal que una medida de distancia (o similaridad) se preserve.
Por ejemplo, sea la transformación que representa el incruste,
(2)
Entonces, si es un incruste que preserva distancias de significado, esperaríamos que
(3)
Pero definir lo que es un incruste es mas fácil que calcularlo. Afortunadamente, las NN nos permiten calcular incruste de palabras muy eficientemente.
En el contexto de redes neuronales la incrustación pueden aprenderse a la par que se realiza la tarea (clasificación, predicción, etc.).
Incruste mediante una NN:
-
Mapea objetos con significado similar a puntos cercanos, con ello se pueden hacer buscas en vecindades.
-
Transforma los objetos a un espacio donde sean comparables, con ello se les puede procesar en un sistema de aprendizaje de máquina
-
Como consecuencia de los anterior, es posible analizar relaciones y conceptos.
Incruste Uno-Activo (one-hot)
El incruste one-hot es el más básico de todos, consiste en mapear cada palabra a un vector indicador (donde son la base canónica).
Para implementar esta esta incrustación, generalmente, se procede como sigue:
-
Elegir un lexicón (lista ordenada por frecuencia de uso de las palabras del lenguaje elegido).
-
Definir el tamaño del diccionario a utilizar (
max_features). De todas la palabras en el lexicón, sólo se consideran lasmax_featurespalabras mas frecuentes, a cualquier otra paabra se le asigna un vector único, digamos el . -
Asuma que regresa el índice, válido, de la palabra en el lexicón. Realizar el la incrustación:
En la parte superior de la siguiente figura se ilustra como queda transformada una palabra en este esquema (one-hot).
La parte inferior ilustra un incruste aprendido de los datos del problema (lo veremos mas delante) con una NN.
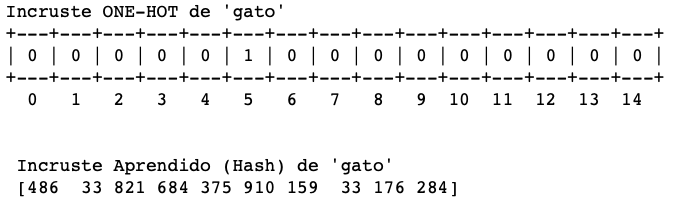
Características de uno y otro:
ONE-HOT
-
Es muy simple de calcular
-
tienen muy alta dimensión
-
Es ralo: solo una entrada es diferente de cero, esta caliente).
Aprendido por NN
-
Aprendido de los datos
-
Baja dimensión
-
Es denso: todas las entradas tienen valores.
Es importante que al calcular el incruste, las relaciones semánticas entre las palabras sean presevadas como relaciones geométricas en el nuevo espacio. Por ejemplo, que la distancia coseno entre dos incrustes tenga sentido:
(4)
o que
(5)
Es decir, esperamos que las palabras relacionadas en nuestro problema sean transformadas a puntos cercanos y que las palabras poco relacionadas correspondan a puntos distantes.
Más aun, esperamos que vectores obtenidos mediante operaciones con ‘palabras’ (en realidad con sus incrustes) tengan significado. Por ejemplo si calculamos
(6)
y luego hacemos
resulte que
Esto es, el vector se pueda interpretar como ‘coronación de un principe/princesa’
Lo que esperamos del incruste es que represente lo mas fielmente la relación semántica entre las palabras del lenguaje natural. Como dicha relación es dependiente del contexto en que se usan las palabras, la mejor práctica sería aprender el incruste a la vez que resolvemos la tarea de análisis de texto.
Incruste Aprendido de los Datos
Para usar un incruste mediante NN, tenemos dos opciones: usar un preentrenado o entrenar un incruste para nuestro problema. La capa embedding es una capa mas. Veamos primero como se implementa una red con incruste aprendido de los datos.
Primero es importante que el incruste es realizado en dos partes:
-
Las palabras son mapeadas a enteros (índices de un vocabulario).
-
Dichos índies son transformados en un vector de flotantes que perservan afinidad semántica.
Estos pasos se representan gráficamente en la siguiente figura
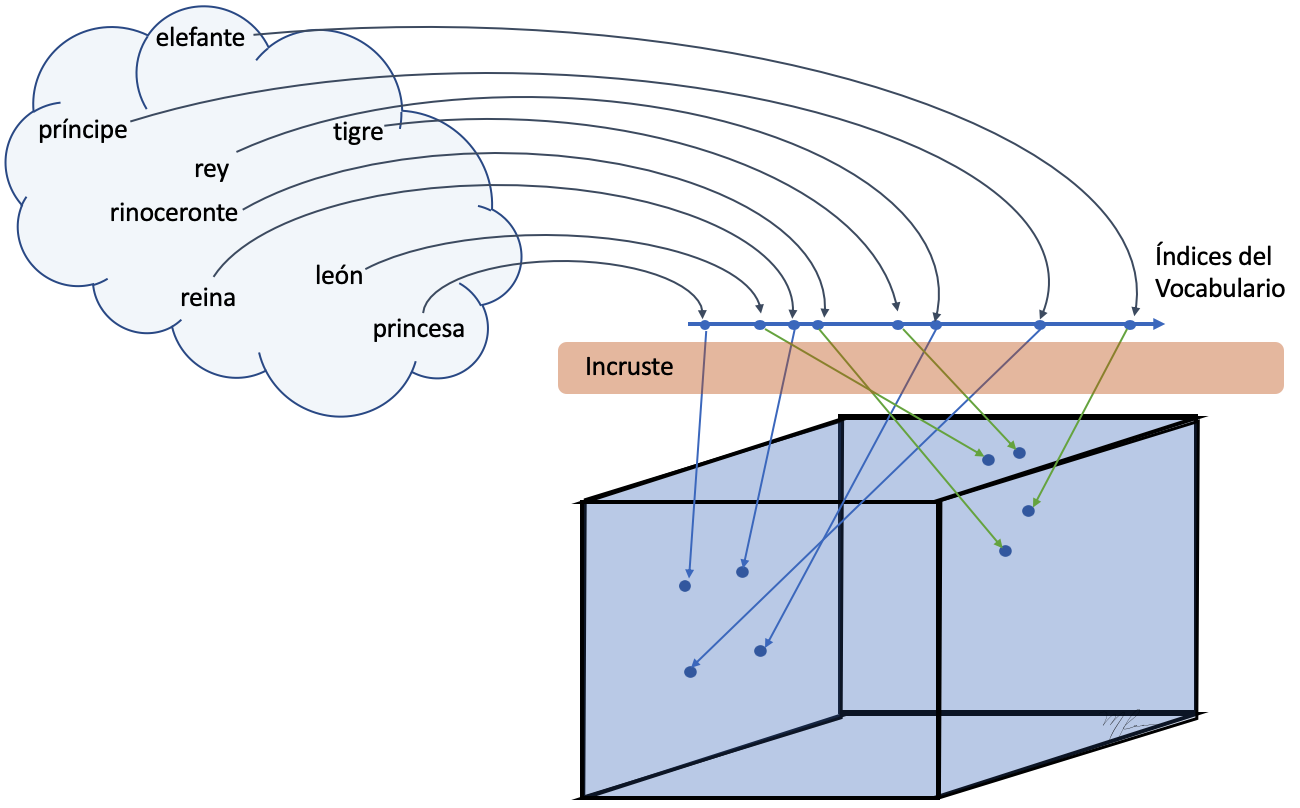
El incruste pueded entenderse como un diccionario, con palabras como llaves y von vectores como valores.
En Keras, la capa embedding esta definida por
keras.layers.Embedding(input_dim,
output_dim,
embeddings_initializer='uniform',
embeddings_regularizer=None,
activity_regularizer=None,
embeddings_constraint=None,
mask_zero=False,
input_length=None)
donde
input_dim: Tamaño del vocabulario
output_dim: Dimensión del incruste
embedding_initializer: inicializador
input_length: Longitud del párrafo
embedding_regularizer: Función de regularización de los pesos
activity_regularizer: Función de regularización a la activación de la capa
embedding_constraint: Retricción sobre los a los pesos
mask_zero: Si el valor 0 se usa para relleno del párrafo (padding).
Ya no se soportan los parámetros
weights: Pesos iniciales
dropout: fracción de incruste a desechar (dropout)
from keras.layers import Embedding
# número máximo de palabars del lexicón que usaremos
max_features = 10000
# longitud máxima del parrafo
maxlen = 20
# dimension del espacio que se transforma cada palabra
embedLen = 8
embedding_layer = Embedding(input_dim=max_features,
output_dim=embeddLen,
input_length=maxlen)
Es es sólo una instacia de capa, no forma parte de ninguna red, mas delante mostramos el código que incluye la capa de incrustación en una red secuencial.
Preparación de los datos
Usamos como ejemplo el problema de predicción del sentimiento de revisión de películas de IMDB.
Restringiendo el vocabulario a las 10,000 palabras más comunes
y las truncando cada comentario a sólo maxlen palabras.
from keras.datasets import imdb
from keras import preprocessing
# número máximo de palabars del lexicón que usaremos
max_features = 10000
# Longitud del párrafo
maxlen = 40
# Lectura de IMDB
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
# Recorte cada revisión (párrafo) a `maxlen`
# y convertido en un arreglo de indices
x_train = preprocessing.sequence.pad_sequences(sequences=x_train,
maxlen=maxlen)
x_test = preprocessing.sequence.pad_sequences(sequences=x_test,
maxlen=maxlen)
Ejemplo de párrafo codificado el vector de enteros (índices). Aun no estan incrustados.
print("Ejemplo una revisión de película (índices da las primeras 'maxlen' palabras): \n",x_train[0])
print('Etiqueta:',y_train[0])
Ejemplo una revisión de película (índices da las primeras 'maxlen' palabras):
[ 22 21 134 476 26 480 5 144 30 5535 18 51 36 28
224 92 25 104 4 226 65 16 38 1334 88 12 16 283
5 16 4472 113 103 32 15 16 5345 19 178 32]
Etiqueta: 1
Definir el incruste de cada palabra a un espacio de dimensión embedLen a donde se mapean cada una de las 10,000 palabras.
Los datos son arreglos de párrafos (secuencia de secuencias de enteros) representados por un tensor de entero 2D. Cada entero (palabra) se incrustará en una secuencia de flotantes (tensor 3D de floats). Cada párrafo (2D, es este momento) se reformaterá a para alimentar un clasificador definido por una capa Dense
from keras.models import Sequential
from keras.layers import Flatten, Dense
from keras.layers import Embedding
# número máximo de palabars del lexicón que usaremos
max_features = 10000
# longitud máxima del parrafo
maxlen = 40
# dimension del espacio que se transforma cada palabra
embedLen = 8
# modelo secuencial
model = Sequential()
# capa de incruste
model.add(Embedding(input_dim=max_features,
output_dim=embedLen,
input_length=maxlen))
# aplanado de cada párrafo
model.add(Flatten())
# capa clasificadora binaria
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 40, 8) 80000
_________________________________________________________________
flatten_1 (Flatten) (None, 320) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 321
=================================================================
Total params: 80,321
Trainable params: 80,321
Non-trainable params: 0
_________________________________________________________________
Como notamos, todos los parámetros son entrenables, incluyendo los correspondientes a la capa de incruste. Entonces entrenamos la simultáneamente el incruste y el clasificador.
history = model.fit(x_train,
y_train,
epochs =10,
batch_size =32,
validation_split=0.2,
verbose =2)
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
- 1s - loss: 0.6596 - acc: 0.6402 - val_loss: 0.5837 - val_acc: 0.7364
Epoch 2/10
- 1s - loss: 0.4864 - acc: 0.7910 - val_loss: 0.4648 - val_acc: 0.7782
Epoch 3/10
- 1s - loss: 0.3929 - acc: 0.8305 - val_loss: 0.4333 - val_acc: 0.7932
Epoch 4/10
- 1s - loss: 0.3497 - acc: 0.8489 - val_loss: 0.4251 - val_acc: 0.7970
Epoch 5/10
- 1s - loss: 0.3204 - acc: 0.8639 - val_loss: 0.4244 - val_acc: 0.7984
Epoch 6/10
- 1s - loss: 0.2972 - acc: 0.8763 - val_loss: 0.4286 - val_acc: 0.7976
Epoch 7/10
- 1s - loss: 0.2769 - acc: 0.8869 - val_loss: 0.4341 - val_acc: 0.7976
Epoch 8/10
- 1s - loss: 0.2580 - acc: 0.8961 - val_loss: 0.4419 - val_acc: 0.7948
Epoch 9/10
- 1s - loss: 0.2406 - acc: 0.9048 - val_loss: 0.4505 - val_acc: 0.7984
Epoch 10/10
- 1s - loss: 0.2240 - acc: 0.9131 - val_loss: 0.4598 - val_acc: 0.7962
Logramos una precisión en los datos de validación cercana al 80%
Si incrementamos el tamaño del párrafo (20 son realmente muy pocas palabras) y usamos un espacio mayor de incruste.
from keras.datasets import imdb
from keras import preprocessing
from keras.models import Sequential
from keras.layers import Flatten, Dense
from keras.layers import Embedding
# Tamaño del vocabulario : número máximo de palabras del lexicón que usaremos
max_features = 10000
# longitud máxima del párrafo
maxlen = 100
# dimension del espacio que se transforma cada palabra
embedLen = 20
# Lectura de IMDB
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
# Recorte cada revisión (párrafo) a `maxlen`
# y convertido en un arreglo de indices
x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen)
# modelo secuencial
model = Sequential()
# capa de incruste
model.add(Embedding(input_dim = max_features,
output_dim = embedLen,
input_length = maxlen))
# aplanado de cada párrafo
model.add(Flatten())
# capa clasificadora binaria
model.add(Dense(1, activation='sigmoid'))
# definimos los parámetros de entrenamiento
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
model.summary()
# entrenamos
history = model.fit(x_train, y_train,
epochs = 10,
batch_size = 32,
validation_split = 0.2,
verbose = 2)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, 100, 20) 200000
_________________________________________________________________
flatten_2 (Flatten) (None, 2000) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 2001
=================================================================
Total params: 202,001
Trainable params: 202,001
Non-trainable params: 0
_________________________________________________________________
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
- 1s - loss: 0.5559 - acc: 0.7288 - val_loss: 0.3876 - val_acc: 0.8322
Epoch 2/10
- 1s - loss: 0.3154 - acc: 0.8676 - val_loss: 0.3298 - val_acc: 0.8538
Epoch 3/10
- 1s - loss: 0.2527 - acc: 0.8975 - val_loss: 0.3230 - val_acc: 0.8578
Epoch 4/10
- 1s - loss: 0.2148 - acc: 0.9162 - val_loss: 0.3303 - val_acc: 0.8596
Epoch 5/10
- 1s - loss: 0.1818 - acc: 0.9306 - val_loss: 0.3345 - val_acc: 0.8614
Epoch 6/10
- 1s - loss: 0.1503 - acc: 0.9457 - val_loss: 0.3472 - val_acc: 0.8574
Epoch 7/10
- 1s - loss: 0.1181 - acc: 0.9598 - val_loss: 0.3579 - val_acc: 0.8580
Epoch 8/10
- 1s - loss: 0.0890 - acc: 0.9733 - val_loss: 0.3750 - val_acc: 0.8546
Epoch 9/10
- 1s - loss: 0.0634 - acc: 0.9830 - val_loss: 0.3955 - val_acc: 0.8490
Epoch 10/10
- 1s - loss: 0.0429 - acc: 0.9912 - val_loss: 0.4227 - val_acc: 0.8462
Mejoramos con una precisión en conjunto de validación alrededor del 86%
Explorando el incruste para datos
Si una vez entrenada la red que incluye un incruste requerimos revisar el incruste de un párrafo en particular, lo que hacemos es crear un segundo modelo a partir del primero que regrese las salidas de todos las capas.
Primero, construimos un lote de procesamiento con un solo dato. Esto es, al párrafo a evaluar en su formato codificado en enteros. Se añade una dimensión que indica que es un lote de tamaño 1.
import numpy as np
x = np.expand_dims(x_train[0], axis=0)
print('Tamaño del párrafo: ', x[0].shape)
print('Párrafo: ', x[0])
Tamaño del párrafo: (100,)
Párrafo: [1415 33 6 22 12 215 28 77 52 5 14 407 16 82
2 8 4 107 117 5952 15 256 4 2 7 3766 5 723
36 71 43 530 476 26 400 317 46 7 4 2 1029 13
104 88 4 381 15 297 98 32 2071 56 26 141 6 194
7486 18 4 226 22 21 134 476 26 480 5 144 30 5535
18 51 36 28 224 92 25 104 4 226 65 16 38 1334
88 12 16 283 5 16 4472 113 103 32 15 16 5345 19
178 32]
from keras import models
layer_name = 'embedding_4'
# lista con las salidas de cada capa de la red
layer_outputs = [layer.output for layer in model.layers[0:2]]
# nuevo modelo indicando la entrada y como salida la lista de salidas de cada capa
activation_model = models.Model(inputs=model.input, outputs=layer_outputs)
# predicción del parrafo
embedding_output = activation_model.predict(x)
print('Predición \n (num párrafos, \n num palabras por párrafo, \n espacio',
' del incruste de cada palabra): \n', embedding_output[0].shape)
print('Incruste de la primera palabra :', embedding_output[0][0,0])
Predición
(num párrafos, num palabras por párrafo, espacio del incruste de cada palabra):
(1, 100, 20)
Incruste de la primera palabra :
[-0.172075 0.29454172 -0.3621311 0.26919472 0.10045812 -0.00694068
-0.21155499 0.1943314 -0.3473015 -0.24448407 0.30402848 -0.23334044
0.17695229 0.29036915 -0.09335899 0.24959917 0.24581131 -0.19502054
0.16736498 -0.22955172]
Alternativamente, se puede crear una función que evalúa únicamente una capa
Del módulo ‘backend’ usamos el método ‘function’ que instacía un función Keras
keras.backend.function(inputs, outputs, updates=None)
Parámetros
inputs: Lista de tensores de entrada
outputs: Lista de tensores de salida
updates: Lista de operaciones a actualizar
Luego, podemos llamar a la función creada con la lista de tensores parámetros de entrada y sin conexión a otras capas
layer0_output = get_layer0_output([x])[0]
from keras import backend as K
# función que evalua una capa de 'model'
get_layer0_output = K.function([model.layers[0].input],
[model.layers[0].output])
# un solo párrafo como datos de entrada al lote
layer0_output = get_layer0_output([x])[0]
print('Incruste de la primera palabra :', layer0_output[0][0])
Incruste de la primera palabra :
[-0.172075 0.29454172 -0.3621311 0.26919472 0.10045812 -0.00694068
-0.21155499 0.1943314 -0.3473015 -0.24448407 0.30402848 -0.23334044
0.17695229 0.29036915 -0.09335899 0.24959917 0.24581131 -0.19502054
0.16736498 -0.22955172]
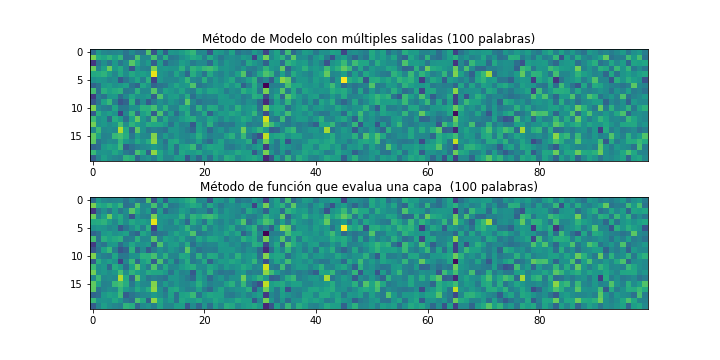
import matplotlib.pyplot as plt
plt.figure(figsize=(20,10))
plt.subplot(211)
plt.imshow(embedding_output[0][0].T)
plt.title('Método de Modelo con múltiples salidas (100 palabras)')
plt.subplot(212)
plt.imshow(layer0_output[0].T)
plt.title('Método de función que evalua una capa (100 palabras)')
plt.show()
Incruste Preentrenado
Si no contamos con datos suficientes, una opción es usar un incruste previamente calculado para un conjunto de datos suficientemente general. Entonces, el incruste preentrenado se usa como capa predefinida en nuestra NN.
Como en el caso de redes convolucionales preentrenadas, un incruste preentrenado no permite reusar características aprendidas en un problema mas general.
Entre los algoritmos mas existosos de cálculo de incrustes estan
Word2Vec [1, 2, 3]: Word to Vectors, basado en una NN que predice palabras a partir de otras en el contexto.
GloVe [4]: Global Vectors for Word Representation, basadio en factorización de matrices de coocurencias estadísticas. Keras trae entre sus bases de datos el encaje preentrenado GloVe para el ingés.
[1] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient es- timation of word representations in vector space. CoRR, abs/1301.3781, 2013.
[2] Tomas Mikolov, Ilya Sutskever, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States, pages 3111–3119, 2013.
[3] Yoav Goldberg and Omer Levy, Word2vec Explained: deriving Mikolov et al.'s negative-sampling word-embedding method, ArXiv preprint, 1402.3722 (2014).
[4] J. Pennington, et al., Glove: Global Vectors for Word Representation, Proc. Conference on Empirical Methods in Natural Language Processing (EMNLP), 1532-1543, 2014
El incruste puede ser pensado como un diccionario en el cual las palabras, representadas como enteros, son la llave y el valor son el vector de alta dimensión incrustado. Su implementación práctica es mediate una matriz, donde cada palabra con índice se asocia con un vector renglón.
Descargar la BD IMDB data
De http://ai.stanford.edu/~amaas/data/sentiment/ descargar la BD “cruda” IMDB dataset: texto y etiquetas (positivo o negativo)
import os
imdb_dir = '/Users/marianoriverameraz/Data/kaggle/aclImdb'
train_dir = os.path.join(imdb_dir, 'train')
labels = []
texts = []
for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type)
for fname in os.listdir(dir_name):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname))
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
Ejemplo del un comentario
idx=20000
texts[idx]
'Give this movie a break! Its worth at least a "7"! That little girl is a good actor and she\'s cute, too. Jim Belushi is a comic genius. You can\'t help but feel good at the end! I wish there were more wholesome shows like this, that you can enjoy with your kids!'
print('negativo' if labels[idx]==0 else 'positivo')
positivo
Tokenización de los datos
Tokenizer es una clase que permite construir un diccionario de palabras a partir de textos y para su tokenización
Let’s vectorize the texts we collected, and prepare a training and validation split.
We will merely be using the concepts we introduced earlier in this section.
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np
maxlen = 100 # Longitud maxima del la revisión, solo 100 palabras
training_samples = 200 # Entrenar con 200 muestras
validation_samples = 10000 # Validar con 10,000 muestras
max_words = 10000 # Diccionario de las 10,000 palabras mas frecuantes
tokenizer = Tokenizer(num_words=max_words) # initialización del tokenizador
tokenizer.fit_on_texts(texts) # ajusta el tokenizador a los textos de entrenamiento
sequences = tokenizer.texts_to_sequences(texts) # texto a secuencias de índices de palabras
word_index = tokenizer.word_index # Diccionario {word : idx, ...}
print('{} tokens únicos encontrados.'.format(len(word_index)))
data = pad_sequences(sequences, maxlen=maxlen)
labels = np.asarray(labels)
print('Forma del tensor de datos:', data.shape)
print('Forma del tensor de etiquetas:', labels.shape)
88582 tokens únicos encontrados.
Forma del tensor de datos: (25000, 100)
Forma del tensor de etiquetas: (25000,)
Pares { Key : Value } del diccionario
def first_kpairs(mydict, k ):
return list(mydict.items())[:k]
first_kpairs(word_index, k=20)
[('the', 1),
('and', 2),
('a', 3),
('of', 4),
('to', 5),
('is', 6),
('br', 7),
('in', 8),
('it', 9),
('i', 10),
('this', 11),
('that', 12),
('was', 13),
('as', 14),
('for', 15),
('with', 16),
('movie', 17),
('but', 18),
('film', 19),
('on', 20)]
print(texts[0], '\n')
print(sequences[0][-maxlen:], '\n')
print(data[0])
Working with one of the best Shakespeare sources, this film manages to be creditable to it's source, whilst still appealing to a wider audience.<br /><br />Branagh steals the film from under Fishburne's nose, and there's a talented cast on good form.
[777, 16, 28, 4, 1, 115, 2278, 6887, 11, 19, 1025, 5, 27, 5, 42, 2425, 1861, 128, 2270, 5, 3, 6985, 308, 7, 7, 3383, 2373, 1, 19, 36, 463, 3169, 2, 222, 3, 1016, 174, 20, 49, 808]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 777 16 28 4 1 115 2278 6887 11 19
1025 5 27 5 42 2425 1861 128 2270 5 3 6985 308 7
7 3383 2373 1 19 36 463 3169 2 222 3 1016 174 20
49 808]
Las muestras estan ordenadas: primero todas las negativas y luego todas las positiva. Por lo que remezclamos los datos.
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
Descargar el incruste (embedding) de palabras GloVe
De https://nlp.stanford.edu/projects/glove/ descargar el incruste preentrenado a partir del texto en inglés de Wikipedia 123014.
Son aproximadamente 822MB en el archivo ZIP glove.6B.zip con una incruste de 400,000 palabras (y no-palabras) a vectores de dimensión 100.
Construyamos el diccionario con entradas de la forma { 'palabra', incruste }, donde incruste es el vector de flotantes de dimensión 100.
El archivo ‘glove.6B.100d.txt’ tienen el incruste GloVe, cada línea del archivo tienen el formato
palabra val_1 val_2 ... val_100
glovePath = '/Users/marianoriverameraz/Data/kaggle/glove'
# diccionario
embeddingsDir = {}
f = open(os.path.join(glovePath, 'glove.6B.100d.txt'))
for line in f:
# línea completa
values = line.split()
# primer elemento: palabra
word = values[0]
# 100 coeficientes
coefs = np.asarray(values[1:], dtype='float32')
embeddingsDir[word] = coefs
f.close()
print('Se encontraron {} pares palabra-vector.'.format(len(embeddingsDir)))
Se encontraron 400000 pares palabra-vector.
Analicemos unas palabras para ver como se ve su incruste.
plt.figure(figsize=(8,6))
plt.subplot(311)
plt.plot(embeddingsDir['love'])
plt.plot(embeddingsDir['like'])
plt.title('love - like')
plt.subplot(312)
plt.plot(embeddingsDir['king'])
plt.plot(embeddingsDir['prince'])
plt.title('king - prince')
plt.subplot(313)
plt.plot(embeddingsDir['lion'])
plt.plot(embeddingsDir['tiger'])
plt.title('lion - tiger')
plt.show()
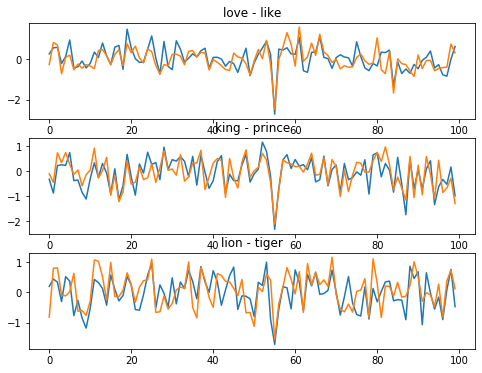
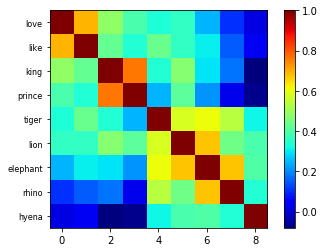
Es difícil a primera vista distinguir que tan distintas son, por ejemplo, palabras como ‘lion’ y ‘love’. Es mas informativo si calculamos la correlación entre los vectores.
def showCorr(Corr, labels, cmap='jet'):
plt.figure(figsize=(15,15))
fig, ax1 = plt.subplots()
cax=plt.imshow(Corr, cmap=cmap)
ax1.set_yticklabels(['']+labels,fontsize=8)
fig.colorbar(cax)
plt.show()
names=['love', 'like', 'king', 'prince', 'tiger', 'lion', 'elephant','rhino','hyena']
embdd = np.array([embeddingsDir[name] for name in names])
Corr= np.corrcoef(embdd)
showCorr(Corr=Corr, labels=names, cmap='jet')
<Figure size 1080x1080 with 0 Axes>
Construcción de la matriz de incruste embedding-matriz con forma (max_words, embedding_dim)
El renglón contienen el vector de incruste, el es el índice de la palabra resultante de la tokenización
El índice 0 no corresponde a una palabra, sino a un marcador de inicio de párrafo.
embedding_dim = 100
# inicialización de matriz de incruste, palabras no encontradas serán zeros
embedding_matrix = np.zeros((max_words, embedding_dim))
for word, idx in word_index.items():
embedding_vector = embeddingsDir.get(word)
# embedding_vector = embeddingsDir[word] # Falla si 'word' tienen un apostrofe, como it's
# hacer el mapeo si está en las primeras `max_words` palabras
if idx < max_words:
if embedding_vector is not None:
embedding_matrix[idx] = embedding_vector
Hemos almacenado en embdedding_matrix el mapeo de la palabra correspondiente al índice del renglón con el vector de incruste almacenado como el vector renglon -ésimo.
Usando el Incruste en una NN
Con la misma arquitectura de red que probamos anteriormente
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense, Dropout
model = Sequential()
model.add(Embedding(input_dim = max_words,
output_dim = embedding_dim,
input_length = maxlen))
model.add(Flatten())
model.add(Dense(units=32, activation='relu' ))
model.add(Dense(units=1, activation='sigmoid'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, 100, 100) 1000000
_________________________________________________________________
flatten_3 (Flatten) (None, 10000) 0
_________________________________________________________________
dense_3 (Dense) (None, 32) 320032
_________________________________________________________________
dense_4 (Dense) (None, 1) 33
=================================================================
Total params: 1,320,065
Trainable params: 1,320,065
Non-trainable params: 0
_________________________________________________________________
Carga la matriz de GloVe en la capa de Incruste
En el código anterior, usamos la capa Embedding que transforma cada palabra (con índice máximo de max_words), en un párrafo de longitud maxlen, a un arreglos de flotantes de tamaño enbedding_dim
Si es el código entero de una palabra, podriamos considerar el incruste como una función que regresa -ésimo renglón de una matriz, donde cada renglón es el incruste de la palabra .
Para cargar el incruste GloVe en el modelo se sustituyen los pesos de la capa (matriz de pesos) embedding y se define como capa no entrenable; ver capas no entrenables. Esto es
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, 100, 100) 1000000
_________________________________________________________________
flatten_3 (Flatten) (None, 10000) 0
_________________________________________________________________
dense_3 (Dense) (None, 32) 320032
_________________________________________________________________
dense_4 (Dense) (None, 1) 33
=================================================================
Total params: 1,320,065
Trainable params: 320,065
Non-trainable params: 1,000,000
_________________________________________________________________
Note que, ahora se tienen 1,000,000 de pesos no entrenables en el modelo: max_words embedding_dim= .
Entrenamiento y Evaluación
Compilamos,
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
entrenamos
history = model.fit(data, labels,
epochs = 20,
batch_size = 32,
validation_split= 0.2,
shuffle = True,
verbose =2)
Train on 20000 samples, validate on 5000 samples
Epoch 1/20
- 3s - loss: 0.6216 - acc: 0.6596 - val_loss: 0.5528 - val_acc: 0.7272
Epoch 2/20
- 3s - loss: 0.5033 - acc: 0.7571 - val_loss: 0.5726 - val_acc: 0.7114
Epoch 3/20
- 3s - loss: 0.4587 - acc: 0.7845 - val_loss: 0.5714 - val_acc: 0.7212
Epoch 4/20
- 3s - loss: 0.4205 - acc: 0.8053 - val_loss: 0.6278 - val_acc: 0.6816
Epoch 5/20
- 3s - loss: 0.3833 - acc: 0.8265 - val_loss: 0.6080 - val_acc: 0.7206
Epoch 6/20
- 3s - loss: 0.3464 - acc: 0.8461 - val_loss: 0.7402 - val_acc: 0.7034
Epoch 7/20
- 3s - loss: 0.3044 - acc: 0.8669 - val_loss: 0.6859 - val_acc: 0.7116
Epoch 8/20
- 3s - loss: 0.2666 - acc: 0.8866 - val_loss: 0.7415 - val_acc: 0.7076
Epoch 9/20
- 3s - loss: 0.2296 - acc: 0.9062 - val_loss: 0.7882 - val_acc: 0.7050
Epoch 10/20
- 3s - loss: 0.1923 - acc: 0.9224 - val_loss: 0.9420 - val_acc: 0.7008
Epoch 11/20
- 3s - loss: 0.1578 - acc: 0.9371 - val_loss: 1.1277 - val_acc: 0.6988
Epoch 12/20
- 3s - loss: 0.1261 - acc: 0.9507 - val_loss: 1.1031 - val_acc: 0.6932
Epoch 13/20
- 3s - loss: 0.1003 - acc: 0.9627 - val_loss: 1.7230 - val_acc: 0.6732
Epoch 14/20
- 3s - loss: 0.0759 - acc: 0.9724 - val_loss: 1.4262 - val_acc: 0.6930
Epoch 15/20
- 3s - loss: 0.0614 - acc: 0.9784 - val_loss: 1.3891 - val_acc: 0.6946
Epoch 16/20
- 3s - loss: 0.0491 - acc: 0.9831 - val_loss: 1.5687 - val_acc: 0.6948
Epoch 17/20
- 3s - loss: 0.0365 - acc: 0.9878 - val_loss: 1.6783 - val_acc: 0.6920
Epoch 18/20
- 3s - loss: 0.0319 - acc: 0.9897 - val_loss: 1.7182 - val_acc: 0.6946
Epoch 19/20
- 3s - loss: 0.0263 - acc: 0.9926 - val_loss: 1.7902 - val_acc: 0.6846
Epoch 20/20
- 3s - loss: 0.0220 - acc: 0.9929 - val_loss: 1.9266 - val_acc: 0.6992
y salvamos el modelo.
model.save_weights('pre_trained_glove_model.h5')
Gráficas de desempeño
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.figure(figsize=(15,7))
plt.subplot(121)
plt.plot(epochs, acc, 'bo', label='Entrenamiento')
plt.plot(epochs, val_acc, 'g', label='Validacion')
plt.title('Precisión (accuracy) de Entrenamiento y Validación')
plt.legend()
plt.subplot(122)
plt.plot(epochs, loss, 'bo', label='Entrenamiento')
plt.plot(epochs, val_loss, 'g', label='Validación')
plt.title('Pérdida de Entrenamiento y Validación')
plt.legend()
plt.show()
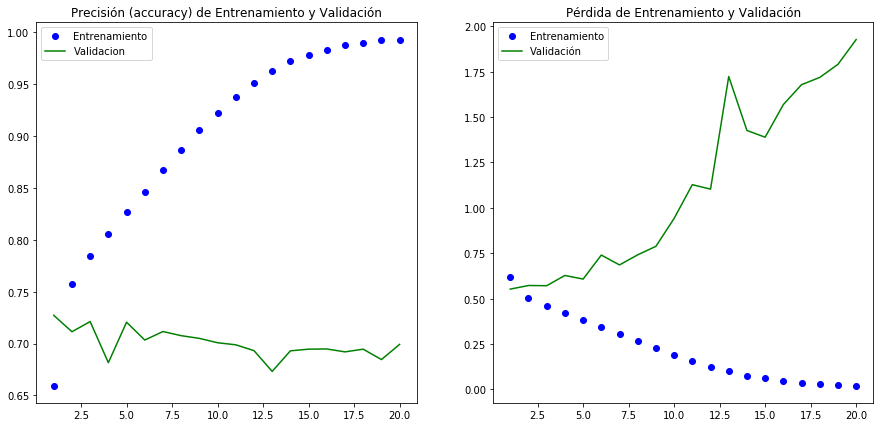
Tenemos problemas de sobreajuste (overfitting) del modelo en épocas muy tempranas. La la exectitud de la validación alcanza apenas el en tanto sobre el entrenamiento se logra una clasificación prácticamente perfecta en épocas muy posteriores. Aún agregando Dropout el comportamiento no mejora.
Tratemos de usar un incruste no-preentrenado y que sea particular de nuestro problema.
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense
# El mismo modelo que usamos antes con incruste preentrenado
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(data, labels,
epochs =10,
batch_size =32,
validation_split=0.2,
shuffle =True,
verbose =2)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_5 (Embedding) (None, 100, 100) 1000000
_________________________________________________________________
flatten_5 (Flatten) (None, 10000) 0
_________________________________________________________________
dense_7 (Dense) (None, 32) 320032
_________________________________________________________________
dense_8 (Dense) (None, 1) 33
=================================================================
Total params: 1,320,065
Trainable params: 1,320,065
Non-trainable params: 0
_________________________________________________________________
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
- 8s - loss: 0.4300 - acc: 0.7899 - val_loss: 0.3343 - val_acc: 0.8568
Epoch 2/10
- 8s - loss: 0.1415 - acc: 0.9506 - val_loss: 0.4327 - val_acc: 0.8366
Epoch 3/10
- 7s - loss: 0.0152 - acc: 0.9961 - val_loss: 0.6567 - val_acc: 0.8274
Epoch 4/10
- 7s - loss: 9.9249e-04 - acc: 0.9997 - val_loss: 0.8587 - val_acc: 0.8248
Epoch 5/10
- 7s - loss: 9.7853e-06 - acc: 1.0000 - val_loss: 1.1031 - val_acc: 0.8236
Epoch 6/10
- 7s - loss: 7.5348e-07 - acc: 1.0000 - val_loss: 1.1531 - val_acc: 0.8238
Epoch 7/10
- 7s - loss: 1.2012e-07 - acc: 1.0000 - val_loss: 1.1780 - val_acc: 0.8236
Epoch 8/10
- 7s - loss: 1.0986e-07 - acc: 1.0000 - val_loss: 1.1818 - val_acc: 0.8250
Epoch 9/10
- 6s - loss: 1.0972e-07 - acc: 1.0000 - val_loss: 1.1856 - val_acc: 0.8250
Epoch 10/10
- 6s - loss: 1.0968e-07 - acc: 1.0000 - val_loss: 1.1869 - val_acc: 0.8248
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.figure(figsize=(15,7))
plt.subplot(121)
plt.plot(epochs, acc, 'bo', label='Entrenamiento')
plt.plot(epochs, val_acc, 'g', label='Validación')
plt.title('Precisión (accuracy) de Entrenamiento y Validación')
plt.legend()
plt.subplot(122)
plt.plot(epochs, loss, 'bo', label='Entrenamiento')
plt.plot(epochs, val_loss, 'g', label='Validación')
plt.title('Pérdida de Entrenamiento y Validación')
plt.legend()
plt.show()
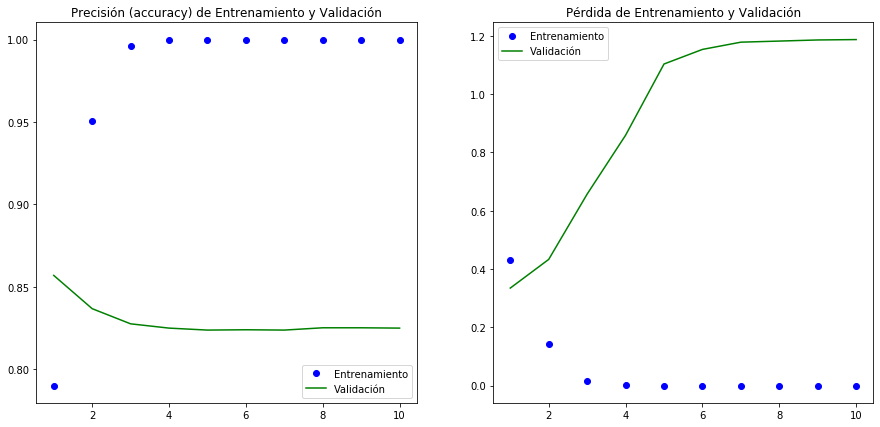
Si bien mejor a el desempeño del modelo en validación, desafortunadamente seguimos teniendo el problema de convergencia muy temprana
Para analizar secuencias de datos relacionados (como lo es el texto) es más conveniente usar redes recurrentes. Estos son redes que procesan palabra a palabra la entrada y tienen memoria de los datos que han procasado. Ver Redes Recurrentes.