Probabilistic Denoising Diffusion Models in PyTorch
Implementation of the PDDM in PyTorch
Mariano Rivera
version 1.2
sept 2025
import math
import os
import argparse
from dataclasses import dataclass
from typing import Tuple
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, ConcatDataset
import torchvision
from torchvision import transforms
from torchvision.utils import make_grid, save_image
# ------------------------------------------------------------
# Utilities
# ------------------------------------------------------------
def exists(x):
return x is not None
def default(val, d):
return val if exists(val) else d
def to_device(batch, device):
if isinstance(batch, (list, tuple)):
return [to_device(b, device) for b in batch]
return batch.to(device, non_blocking=True)
UNet
# ------------------------------------------------------------
# Sinusoidal positional (time) embeddings
# ------------------------------------------------------------
class SinusoidalPosEmb(nn.Module):
def __init__(self, dim: int):
super().__init__()
self.dim = dim
def forward(self, t):
"""
t: (B,)
returns: (B, dim)
"""
device = t.device
half = self.dim // 2
freqs = torch.exp(
torch.linspace(math.log(1.0), math.log(10000.0), steps=half, device=device)
)
args = t[:, None] * freqs[None, :]
emb = torch.cat([torch.sin(args), torch.cos(args)], dim=-1)
if self.dim % 2 == 1: # odd dim
emb = torch.cat([emb, torch.zeros_like(emb[:, :1])], dim=-1)
return emb
# ------------------------------------------------------------
# Building blocks for UNet
# ------------------------------------------------------------
class ResidualBlock(nn.Module):
def __init__(self, in_ch, out_ch, time_dim=None, groups=8):
super().__init__()
self.mlp = None
if exists(time_dim):
self.mlp = nn.Sequential(nn.SiLU(),
nn.Linear(time_dim, out_ch)
)
self.block1 = nn.Sequential(nn.GroupNorm(groups, in_ch),
nn.SiLU(),
nn.Conv2d(in_ch, out_ch, 3, padding=1)
)
self.block2 = nn.Sequential(nn.GroupNorm(groups, out_ch),
nn.SiLU(),
nn.Conv2d(out_ch, out_ch, 3, padding=1)
)
self.res_conv = nn.Conv2d(in_ch, out_ch, 1) if in_ch != out_ch else nn.Identity()
def forward(self, x, t_emb=None):
h = self.block1(x)
if exists(self.mlp) and exists(t_emb):
h = h + self.mlp(t_emb)[:, :, None, None]
h = self.block2(h)
return h + self.res_conv(x)
class AttentionBlock(nn.Module):
"""
Simple self-attention over spatial dims.
"""
def __init__(self, channels, num_heads=4):
super().__init__()
self.num_heads = num_heads
self.norm = nn.GroupNorm(8, channels)
self.qkv = nn.Conv2d(channels, channels * 3, 1, bias=False)
self.proj = nn.Conv2d(channels, channels, 1)
def forward(self, x):
b, c, h, w = x.shape
x_norm = self.norm(x)
qkv = self.qkv(x_norm).reshape(b, 3, self.num_heads, c // self.num_heads, h * w)
q, k, v = qkv[:,0], qkv[:,1], qkv[:,2] # (b, heads, ch', hw)
attn = torch.softmax((q.transpose(-2, -1) @ k) / math.sqrt(k.shape[-2]), dim=-1) # (b, heads, hw, hw)
out = (attn @ v.transpose(-2, -1)).transpose(-2, -1) # (b, heads, ch', hw)
out = out.reshape(b, c, h, w)
return x + self.proj(out)
class Downsample(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.conv = nn.Conv2d(in_ch, out_ch, 4, stride=2, padding=1)
def forward(self, x):
return self.conv(x)
class Upsample(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.conv = nn.ConvTranspose2d(in_ch, out_ch, 4, stride=2, padding=1)
def forward(self, x):
return self.conv(x)
# ------------------------------------------------------------
# UNet backbone
# ------------------------------------------------------------
class UNet(nn.Module):
def __init__(self,
img_channels = 3,
base_ch = 64,
ch_mults = (1, 2, 2, 2),
time_dim = 256,
with_attn=(False, True, True, False),
):
super().__init__()
self.time_mlp = nn.Sequential(SinusoidalPosEmb(time_dim),
nn.Linear(time_dim, time_dim*4),
nn.SiLU(),
nn.Linear(time_dim*4, time_dim),
)
chs = [base_ch*m for m in ch_mults]
self.num_levels = len(chs)
# Input conv
self.init_conv = nn.Conv2d(img_channels, base_ch, 3, padding=1)
# Down path
self.downs = nn.ModuleList()
in_ch = base_ch
self.skips = []
for i, out_ch in enumerate(chs):
self.downs.append(nn.ModuleList([ResidualBlock (in_ch, out_ch, time_dim=time_dim),
ResidualBlock (out_ch, out_ch, time_dim=time_dim),
AttentionBlock(out_ch) if with_attn[i] else nn.Identity(),
Downsample (out_ch, out_ch) if i < len(chs) - 1 else nn.Identity()
]))
in_ch = out_ch
# Middle
self.mid1 = ResidualBlock(in_ch, in_ch, time_dim=time_dim)
self.mid_attn = AttentionBlock(in_ch)
self.mid2 = ResidualBlock(in_ch, in_ch, time_dim=time_dim)
# Up path
self.ups = nn.ModuleList()
for i, out_ch in reversed(list(enumerate(chs))):
self.ups.append(nn.ModuleList([ResidualBlock (in_ch + out_ch, out_ch, time_dim=time_dim),
ResidualBlock (out_ch, out_ch, time_dim=time_dim),
AttentionBlock(out_ch) if with_attn[i] else nn.Identity(),
Upsample (out_ch, out_ch) if i > 0 else nn.Identity()
]))
in_ch = out_ch
# Output
self.out_norm = nn.GroupNorm(8, base_ch)
self.out_act = nn.SiLU()
self.out_conv = nn.Conv2d(base_ch, img_channels, 3, padding=1)
def forward(self, x, t):
t_emb = self.time_mlp(t)
x = self.init_conv(x)
skip_connections = []
h = x
# Down
for level,(res1, res2, attn, down) in enumerate(self.downs):
h = res1(h, t_emb) if level in [0,1] else res1(h)
#h = res2(h, t_emb)
h = res2(h)
h = attn(h)
skip_connections.append(h)
h = down(h)
# Mid
h = self.mid1(h, t_emb)
h = self.mid_attn(h)
h = self.mid2(h, t_emb)
# Up
for level,(res1, res2, attn, up) in enumerate(self.ups):
skip = skip_connections.pop()
h = torch.cat([h, skip], dim=1)
h = res1(h, t_emb) if level in [ self.num_levels-1, self.num_levels-2] else res1(h)
#h = res2(h, t_emb)
h = res2(h)
h = attn(h)
h = up(h)
h = self.out_norm(h)
#h = self.out_act(h)
return self.out_conv(h)
Schedule Diffusion utilities (cosine schedule)
@dataclass
class DiffusionSchedule:
timesteps: int
betas: torch.Tensor
alphas: torch.Tensor
alphas_cumprod: torch.Tensor
alphas_cumprod_prev: torch.Tensor
sqrt_alphas_cumprod: torch.Tensor
sqrt_one_minus_alphas_cumprod: torch.Tensor
sqrt_recip_alphas: torch.Tensor
posterior_variance: torch.Tensor
def cosine_beta_schedule(timesteps, s=0.008, eps=1e-5):
"""
https://arxiv.org/abs/2102.09672
"""
steps = timesteps + 1
x = torch.linspace(0, timesteps, steps)
alphas_cumprod = torch.cos(((x / timesteps) + s) / (1 + s) * math.pi * 0.5) ** 2
alphas_cumprod = alphas_cumprod / alphas_cumprod[0]
betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1])
return torch.clip(betas, eps, 0.999)
def linear_beta_scheduler(timesteps, beta_start=0.0001, beta_end=0.02, eps=1e-5):
"""
Linear scheduler
"""
betas = torch.linspace(beta_start, beta_end, timesteps+1)
return torch.clip(betas, eps, 0.999)
def make_schedule(T, device, cosine=False):
"""
Compute beta_t and all the derived constant vectors:
alpha, alpha_cum_prod, the sqrts, etc.
"""
if cosine :
betas = cosine_beta_schedule(T).to(device)
else :
betas = linear_beta_scheduler(T).to(device)
alphas = 1.0 - betas
alphas_cumprod = torch.cumprod(alphas, dim=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1,0), value=1.0)
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
sqrt_one_minus_alphas_cumprod = torch.sqrt(1.0 - alphas_cumprod)
sqrt_recip_alphas = torch.sqrt(1.0 / alphas)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)
return DiffusionSchedule(timesteps = T,
betas = betas,
alphas = alphas,
alphas_cumprod = alphas_cumprod,
alphas_cumprod_prev = alphas_cumprod_prev,
sqrt_alphas_cumprod = sqrt_alphas_cumprod,
sqrt_one_minus_alphas_cumprod = sqrt_one_minus_alphas_cumprod,
sqrt_recip_alphas = sqrt_recip_alphas,
posterior_variance = posterior_variance
)
Sampling utilities
# ------------------------------------------------------------
# q(x_t | x_0)
# ------------------------------------------------------------
def q_sample(x0, t, schedule: DiffusionSchedule, noise=None):
"""
x0: (B, C, H, W), t: (B,)
"""
if noise is None:
noise = torch.randn_like(x0)
sqrt_alphas = schedule.sqrt_alphas_cumprod[t].view(-1, 1, 1, 1)
sqrt_one_minus = schedule.sqrt_one_minus_alphas_cumprod[t].view(-1, 1, 1, 1)
return sqrt_alphas * x0 + sqrt_one_minus * noise, noise
# ------------------------------------------------------------
# p(x_{t-1} | x_t, x_0) using epsilon-prediction model
# ------------------------------------------------------------
@torch.no_grad()
def p_sample(model, x, t, schedule: DiffusionSchedule, clip_denoised=True):
betas_t = schedule.betas[t].view(-1, 1, 1, 1)
sqrt_one_minus = schedule.sqrt_one_minus_alphas_cumprod[t].view(-1, 1, 1, 1)
sqrt_recip_alpha = schedule.sqrt_recip_alphas[t].view(-1, 1, 1, 1)
model_mean = sqrt_recip_alpha * (x - betas_t / sqrt_one_minus * model(x, t))
if t.min() == 0:
return model_mean
noise = torch.randn_like(x)
posterior_var_t = schedule.posterior_variance[t].view(-1, 1, 1, 1)
return model_mean + torch.sqrt(posterior_var_t) * noise
@torch.no_grad()
def sample(model, schedule: DiffusionSchedule, shape, device, ddim_steps=None):
model.eval()
x = torch.randn(shape, device=device)
T = schedule.timesteps
steps = list(range(T-1, -1, -1))
# Optional: faster sampling by skipping (simple uniform skip)
if ddim_steps is not None and 0 < ddim_steps < T:
idxs = torch.linspace(0, T-1, ddim_steps, dtype=torch.long)
steps = idxs.flip(0).tolist()
for i, t in enumerate(steps):
t_batch = torch.full((shape[0],), int(t), device=device, dtype=torch.long)
x = p_sample(model, x, t_batch, schedule)
return x
Data loader
# ------------------------------------------------------------
# Dataset & DataLoader
# ------------------------------------------------------------
mean = [0.485, 0.456, 0.406] # Example ImageNet means
std = [0.229, 0.224, 0.225]
def build_flowers102(root, img_size=64, batch_size=64, num_workers=4):
tfm = transforms.Compose([transforms.Resize(img_size,
interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize(mean,std) # map to [-1, 1]
])
# Flowers102 has 'train', 'val', 'test' splits; we’ll train on train+val
train_set = torchvision.datasets.Flowers102(root = root,
split = 'train',
transform= tfm,
download = True
)
val_set = torchvision.datasets.Flowers102(root = root,
split = 'val',
transform= tfm,
download = True
)
dataset = ConcatDataset([train_set, val_set])
loader = DataLoader(dataset,
batch_size = batch_size,
shuffle = True,
num_workers = num_workers,
pin_memory = True,
drop_last = True
)
return loader
Training
# ------------------------------------------------------------
# Training step
# ------------------------------------------------------------
def train_step(model, loader, optimizer, schedule, args, device, scaler, epoch):
"""
Use globals: model, loader, optimizer
"""
for step, batch in enumerate(loader):
x0, _ = batch
x0 = to_device(x0, device) # (B, 3, H, W)
bsz = x0.size(0)
t = torch.randint(0, schedule.timesteps, (bsz,), device=device, dtype=torch.long)
optimizer.zero_grad(set_to_none=True)
# forward in float16
with torch.amp.autocast(device_type='cuda', dtype=torch.float16):
x_t, noise = q_sample(x0, t, schedule)
pred_noise = model(x_t, t)
loss = F.mse_loss(pred_noise, noise)
# backwards in float32
scaler.scale(loss).backward()
nn.utils.clip_grad_norm_(model.parameters(), 1.0)
scaler.step(optimizer)
scaler.update()
if step % args.log_every_step == 0:
print(f"[epoch {epoch:04d}] step {step:06d} | loss {loss.item():.4f}")
return loss
def save_checkpoint(model, schedule, epoch, optimizer, loss, args):
model.eval()
ckpt_path = os.path.join(args.out_dir, f"ckpt_epoch{epoch:04d}.pt")
torch.save({'epoch': epoch,
'model': model.state_dict(),
'opt': optimizer.state_dict(),
'args': vars(args),
'loss': loss,
'schedule': schedule,
}, ckpt_path)
print(f"Saved checkpoint: {ckpt_path}")
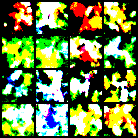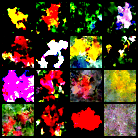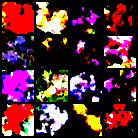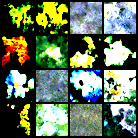
def save_sample(model, schedule, epoch, device, final=False):
model.eval()
filename = "samples_final.png" if final else f"samples_step{epoch:04d}.png"
save_path = os.path.join(args.out_dir, filename)
msg = f"Saved final samples to {save_path}" if final else f"Saved samples to {save_path}"
with torch.no_grad():
imgs = sample(model,
schedule,
shape = (args.n_samples, 3, args.img_size, args.img_size),
device = device,
ddim_steps = args.ddim_steps
)
imgs = (imgs.clamp(-1, 1) + 1) * 0.5 # back to [0,1]
grid = make_grid(imgs, nrow=int(math.sqrt(args.n_samples)))
save_image(grid, save_path)
print(msg)
model.train()
# ------------------------------------------------------------
# Training loop
# ------------------------------------------------------------
def train(args):
device = torch.device('cuda' if torch.cuda.is_available() and not args.cpu else 'cpu')
os.makedirs(args.out_dir, exist_ok=True)
# Data
loader = build_flowers102(root =args.data_dir,
img_size =args.img_size,
batch_size =args.batch_size,
num_workers=args.workers)
# Model, schedule and optimizer
model = UNet(img_channels = 3,
base_ch = args.base_ch,
ch_mults = (1, 2, 4, 4) if args.img_size >= 64 else (1, 2, 2, 2),
time_dim = 256,
with_attn = (False, True, True, False)
).to(device)
schedule = make_schedule(args.timesteps, device)
optimizer = torch.optim.AdamW(model.parameters(), lr=args.lr, weight_decay=1e-4)
# Scaler
scaler = torch.amp.GradScaler(enabled=(device.type == 'cuda'))
# train loop
loss_history=[]
for epoch in range(1, args.epochs+1):
# Train step
model.train()
loss = train_step(model, loader, optimizer, schedule, args, device, scaler, epoch)
# checkpoint each N epochs
if epoch % args.save_every_epochs == 0:
save_checkpoint(model, schedule, epoch, optimizer, loss, args)
# sample model each N epochs
if epoch % args.sample_every_epochs == 0:
save_sample(model, schedule, epoch, device)
loss_history.append(loss)
# final checkpoint and sample
save_checkpoint(model, schedule, args.epochs, optimizer, loss, args)
save_sample (model, schedule, args.epochs, device, final=True)
return loss_history
# ------------------------------------------------------------
# CLI : Command Line Interface
# ------------------------------------------------------------
def parse_args():
p = argparse.ArgumentParser(description="Train a DDPM on Flowers102")
p.add_argument("--data_dir", type=str, default = "./data")
p.add_argument("--out_dir", type=str, default = "./runs/flowers102_ddpm_test")
p.add_argument("--img_size", type=int, default = 64, help="e.g., 64 or 128")
p.add_argument("--batch_size", type=int, default = 64)
p.add_argument("--workers", type=int, default = 4)
p.add_argument("--epochs", type=int, default = 50, help="Number of training epochs")
p.add_argument("--start_epochs", type=int, default = 0)
p.add_argument("--timesteps", type=int, default = 1000, help="diffusion steps T sz:T = (32:60, 64:80)")
p.add_argument("--base_ch", type=int, default = 64, help="UNet base channels")
p.add_argument("--lr", type=float, default = 2e-4, help="Larning rate of the AdamW optimizer")
p.add_argument("--log_every_step", type=int, default = 10, help="show advance each N batches per epoch")
p.add_argument("--save_every_epochs", type=int, default = 100, help="check point frequency")
p.add_argument("--sample_every_epochs",type=int, default = 100, help="sampling progress frequency")
p.add_argument("--n_samples", type=int, default = 16, help="number of images to sample for progress showing")
p.add_argument("--ddim_steps", type=int, default = 0, help="0 to disable; else number of steps to skip to")
p.add_argument("--cpu", action="store_true", help="force CPU")
return p
# Simulated command-line arguments (list)
args_list = ["--data_dir", "./data",
"--out_dir", "./runs/flowers102_ddpm_test",
"--img_size", "32",
"--epochs", "1000",
"--save_every_epochs", "50",
"--sample_every_epochs", "50",
"--workers", "48",
]
# Create an argument parser object
parser = parse_args()
# Parse the "simulated" arguments
args = parser.parse_args(args_list)
# Call the train function with the parsed arguments
print("Training...")
loss_history=train(args)
Training...
[epoch 0001] step 000000 | loss 1.3072
[epoch 0001] step 000010 | loss 0.6416
[epoch 0001] step 000020 | loss 0.3285
[epoch 0001] step 000030 | loss 0.2355
[epoch 0002] step 000000 | loss 0.2888
[epoch 0002] step 000010 | loss 0.2087
[epoch 0002] step 000020 | loss 0.1685
[epoch 0002] step 000030 | loss 0.2046
[epoch 0003] step 000000 | loss 0.2544
...
[epoch 1000] step 000000 | loss 0.0713
[epoch 1000] step 000010 | loss 0.0723
[epoch 1000] step 000020 | loss 0.0962
[epoch 1000] step 000030 | loss 0.1009
Saved checkpoint: ./runs/flowers102_ddpm_test/ckpt_epoch1000.pt
Saved samples to ./runs/flowers102_ddpm_test/samples_step1000.png
Saved checkpoint: ./runs/flowers102_ddpm_test/ckpt_epoch1000.pt
Saved final samples to ./runs/flowers102_ddpm_test/samples_final.png
STOP
Creating a video from the evolution of the traimning process
import os
import glob
import imageio.v2 as io
# Directory containing the sampled images
image_dir = "./runs/flowers102_ddpm_test"
# Get a list of all PNG files in the directory
image_files = glob.glob(os.path.join(image_dir, "samples_step*.png"))
image_files.sort()
# Create a GIF
gif_path = os.path.join(image_dir, "sampling_progress.gif")
images = []
for filename in image_files:
images.append(io.imread(filename))
io.mimsave(gif_path, images, fps=2)
print(f"GIF saved to {gif_path}")
GIF saved to ./runs/flowers102_ddpm_test/sampling_progress.gif
Samplig the trained model
device='cuda'
model = UNet(img_channels = 3,
base_ch = args.base_ch,
ch_mults = (1, 2, 4, 4) if args.img_size >= 64 else (1, 2, 2, 2),
time_dim = 256,
with_attn = (False, True, True, False)
).to(device)
checkpoint = torch.load('./runs/flowers102_ddpm_test/ckpt_epoch1000.pt', weights_only=False)
model.load_state_dict(checkpoint['model'])
schedule = checkpoint['schedule']
model.eval()
imgs = sample(model,
schedule,
shape = (args.n_samples, 3, args.img_size, args.img_size),
device = device,
ddim_steps = args.ddim_steps
)
val=1
imgs = (imgs.clamp(-val, val) + val)/(2+val) # back to [0,1]
#mmin,mmax = imgs.min(), imgs.max()
#imgs = (imgs-mmin)/(mmax-mmin)
grid = make_grid(imgs, nrow=int(math.sqrt(args.n_samples)))
save_path = os.path.join(args.out_dir, f"samples.png")
save_image(grid, save_path)
print(f"Saved samples to {save_path}")
Continuing the training process
def load_model(file_dict_model):
model = UNet(img_channels = 3,
base_ch = args.base_ch,
ch_mults = (1, 2, 4, 4) if args.img_size >= 64 else (1, 2, 2, 2),
time_dim = 256,
with_attn = (False, True, True, False)
)
checkpoint = torch.load(file_dict_model, weights_only=False)
model.load_state_dict(checkpoint['model'])
opt_state = checkpoint['opt']
schedule = checkpoint['schedule']
epoch = checkpoint['epoch']
return model, opt_state, schedule, args, epoch
# ------------------------------------------------------------
# Continue training loop
# ------------------------------------------------------------
def continue_train(file_dict_model, epochs=None):
model, opt_state, schedule, args, start_epoch = load_model(file_dict_model)
os.makedirs(args.out_dir, exist_ok=True)
device = torch.device('cuda' if torch.cuda.is_available() and not args.cpu else 'cpu')
model = model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=args.lr, weight_decay=1e-4)
optimizer.load_state_dict(opt_state)
# Data
loader = build_flowers102(root =args.data_dir,
img_size =args.img_size,
batch_size =args.batch_size,
num_workers=args.workers)
# Scaler
scaler = torch.amp.GradScaler(enabled=(device.type == 'cuda'))
if epochs is None: epochs = args.epochs
# train loop
for epoch in range(start_epoch, epochs+start_epoch):
# Train step
model.train()
loss = train_step(model, loader, optimizer, schedule, args, device, scaler, epoch)
# checkpoint each N epochs
if epoch % args.save_every_epochs == 0:
save_checkpoint(model, schedule, epoch, optimizer, loss, args)
# sample model each N epochs
if epoch % args.sample_every_epochs == 0:
save_sample(model, schedule, epoch, device)
# final checkpoint and sample
save_checkpoint(model, schedule, epochs+start_epoch, optimizer, loss, args)
save_sample (model, schedule, epochs+start_epoch, device, final=True)
continue_train('./runs/flowers102_ddpm_test/ckpt_epoch2000.pt', epochs=1000)