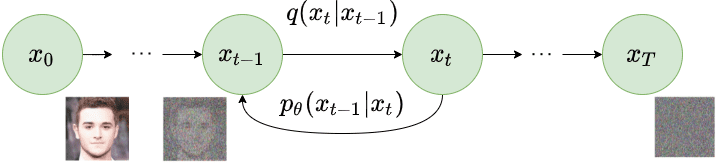Probabilistic Denosing Diffusion Models imagined by Dall-e 2
Modelos Probabilísticos de Difusión para Eliminación de Ruido
Probabilistic Denoising Diffusion Models
M Rivera
Septiembre 2025
version 1.1.0
En estas notas presentamos la derivación del Modelo de Difusión de Eliminación de Ruido para generar imágenes. Esta derivación corresponde a la presentada en el artículo original.
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised
learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, pages
2256–2265, 2015. ArXiv
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems, 33, 6840-6851. ArXiv
import numpy as np
import matplotlib.pyplot as plt
import PIL.Image as Image
import imageio as io
Definimos el proceso de difusión dado por la fórmula de evolución
(1) xt=1−βtxt−1+βtηt
donde
(2) η∼N(0,I),
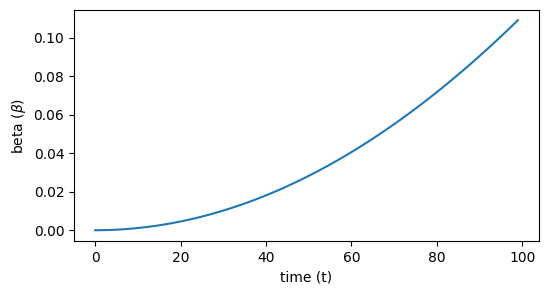
βt no es constante en el tiempo y satisface
(3) β0<β1<…βT
Interpretando a xt como la muestra obtenida de nuestro proceso de difusión en tiempo t, tenemos
(4) xt∼q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
Esto es, xt resulta de muestrear una distribución Gaussiana con media 1−βtxt−1 y varianza βtI. El primer xt antes del ‘;’ indica que los parámetros de la distribución estan asociados a xt.
Otros esquemas de calendarización para α se pueden revisar en
Nichol, Alexander Quinn, and Prafulla Dhariwal. “Improved denoising diffusion probabilistic models.” International Conference on Machine Learning. PMLR, 2021. PDF.
Difusión hacia adelante q(xt∣xt−1)
X =[]
X.append(x0)
Imgs=[]
im =(np.clip(x0,0,1)*255).astype('uint8')
Imgs.append(im)for t,beta inenumerate(betas):
x_tp1 = np.sqrt(1-beta)*X[t]+ np.sqrt(beta)* np.random.normal(0,1, size=x0.shape)
X.append(x_tp1)
im =(np.clip(x_tp1,0,1)*255).astype('uint8')
Imgs.append(im)print(t, end=', ')
io.mimsave('diffusion.gif', Imgs, duration =0.2)
Cálculo de una imagen xt+1 evitando los pasos previos de difusión
De acuerdo con la fórmula (1), para obtener la muestra xt es necesario haber generado la secuencia {xk}k=0:t. Sin embargo, veremos una simplificación al proceso. Consideramos dos pasos de difusión, digamos
(5) xtxt−1=αtxt−1+1−αtηt−1=αt−1xt−2+1−αt−1ηt−2
donde hemos definido
Dado que ηk∼N(0,I), tenemos que a∼N(0,αt(1−αt−1)I) y b∼N(0,(1−αt)I). Luego, la suma de dos variabes aleatorias Gaussianas, independientes, con media cero resulta en una variable aleatoria con media cero y cuya varianza es la suma de la varianza de los sumandos:
(8) xt=αtαt−1xt−2+(1−αtαt−1)η
Procediendo hasta que encontramos xt a partir de x0 (ver Anexo A):
(9) xt=αˉtx0+1−αˉtη.
Donde hemos definido
(10) αˉt=k=1:t∏αk
A (9) le denominan los autores “la propiedad bonita” (the nice property). La ecuación (9) es muy importante porque permite obtener la muestra en tiempo t sin necesidad de realizar todo el proceso de difusión para {0:t−1}. Lo que nos lleva a la condicional:
Notamos que la media y varianza se estiman para cada paso y dependen únicamente de xt y t:
(19) μ(xt,t)=αt1(xt−1−αˉtβtηt)
y
(20) Σ(xt,t)=[1−αˉt1−αˉt−1βt]I
donde I denota la matriz identidad.
III. Aproximamos la verdadera distribución q(xt−1∣xt,x0) por una aproximación paramétrica:
(21) pθ(xt−1∣xt,x0)≃q(xt−1∣xt,x0);
donde θ son los parámetros de la aproximación.
La distribución de la trayectoria inversa {T:0} resulta de aplicar sucesivamente q(xt−1∣xt,x0), o su aproximación pθ(xt−1∣xt,x0), desde xT hasta obtener x0:
(22) pθ(x0:T)=pθ(x0)t=1∏Tpθ(xt−1∣xt)
Siguiendo a (18), (19) y (20); la aproximación paramétrica que se propone es de la forma:
(23) pθ(xt−1∣xt,x0)=N(xt−1;μθ(xtt),Σθ(xt,t));
donde la media la expresamos de forma similar a (19):
(24) μθ(xt,t)=αt1(xt−1−αˉtβtηθ(xt,t).)
Dado que Σ(xt,t) [ver (20)] la podemos calcular desde que definimos el calendario de difusión. Esto es, desde que establecimos la secuencia {βt}t=1:T. Por lo que hacemos
(25) Σθ(xt,t)=Σ(xt,t).
Estimación del modelo inverso
La varianza de la aproximación paramétrica se puede calcular con una fórmula cerrada, por lo que no necesitamos estimarla: solo debemos estimar la media (24) del modelo aproximado.
En la propuesta original de Ho et al. (2020) toman esta expresión para las entradas en la matriz diagonal de covarianza; por lo tanto, su propuesta no involucra aprender estos coeficientes. Sin embargo, es posible diseñar un modelo que involucre también aprender los coeficientes de la varianza.
Notemos la diferencia entre (19) y (24). La primera es la solución verdadera al problema de difusión inversa,requiere conocer el ruido ηt con que se realizó el paso hacia adelante en el tiempo. Por otro lado, la segunda emplea la estimación del ruido ηθ, estimación que se hace con una red neuronal.
Los parámetos θ se obtienen resolviendo el problema de optimización:
(18) θt∗=θargmin=∝∥μ(xt,t)−μθ(xt,t)∥2∥∥αt1xt−αt1−αˉtβtη−αt1xt+αt1−αˉtβtηθ(xt,t)∥∥2∥∥η−η^θ(xt,t)∥∥2
Donde hemos obviado el término de escala.
El algoritmo para entrenar el modelo que estima el ruido se resume a continuación.
Este algoritmo se puede entender como la iteración hasta convergencia de los siguientes pasos:
Obtenemos una imagen al azar (muestra) x0 de la base de datos, similar a la que queremos generar.
Seleccionamos al azar un paso de difusión t y una imagen de ruido Gaussiano η.
Construimos la imagen de difusión a nivel t a partir de x0.
Hacemos un paso de optimización para entrenar el modelo que reconstruye el ruido ηθ(xt,t) que define la difusión de xt−1 a xt.
Una vez entrenado el modelo (red neuronal del tipo UNet). Luego, para realizar la difusion inversa (denoising) en una imagen xt, es decir estimar x^t−1, es necesario estimamos el ruido ηθ(xt,t) mediante el modelo de red neuronal; luego
(20) xt−1=μθ(xt,t)+Σθ(xt,t)η,
con η∼N(0,I). Y así sucesivamente hasta calcular x^0.
El Algoritmo 2 (Samplig) presenta abajo los detalles de este proceso.
En Algoritmo 2: ϵθ(xt,t)≡η^θ(xt,t), el ruido estimado por la red neuronal.
Función de costo
La estrategia es aproximar el modelo real q por una estimación paramétrica pθ. Similar a como se realiza en los Autoencodificadores Variacionales (VAEs). En una VAE esta estimación se realiza mediante la minimización del Límite Inferior de Evidencia (Evidence Lower Bound, ELBO). En este caso el ELBO está dado por
Donde hemos definido las L que aparecen en los términos L0, LT y en la suma; estos corresponden término a término.
Analizando cada uno de los tres términos:
Primer término, L0=Eq(x1∣x0){logpθ(x1∣x0)}. Es un término de reconstrucción (datos) similar al del ELBO en VAEs.
Segundo término, DKL(q(xT∣x0)∥p(xT)). Fuerza a que p(xT) sea cercana a una Gaussiana; que no tiene parámetros, por lo que no es entrenable.
Tercer término, Lt=∑t=2TLt−1. Penaliza las diferencia entre la estimación pθ(xt−1∣xt) y q(xt−1∣xt,x0)
Modelo para estimar el Ruido
A continuación veremos cómo definir el modelo que extrae el ruido de la imagen xt.
Podemos notar que una red neuronal profunda del tipo UNet sería la más adecuada para representar la red que extrae el componente de ruido de la imagen contaminada xt a nivel t. Notemos que nuestro modelo de red profunda debe estar condicionado por t.
ANEXOS
Anexo A. Calcular xt directamente de x0
Si además sustituimos xt−2, y usando “la propiedad bonita”, tenemos
Para hacer el procedimiento tratable usaremos una imagen de referencia x0, esto nos permite tener una guía del tipo de imagen que queremos reconstruir. Partimos de (18) condicionandola también en x0:
Notamos que usando las medias y las varianzas a partir de (9) y (11)
(B.3-B.5) q(xt∣xt−1,x0)q(xt−1∣x0)q(xt∣x0)∝exp[−21(βt(xt−αtxt−1)2)],∝exp[−21(1−αˉt−1(xt−1−αˉt−1x0)2)],∝exp[−21(1−αˉt(xt−αˉtx0)2)].
Sustituyendo en (B.2):
(B.6) q(xt−1∣xt,x0)∝exp[−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2)].
Luego
Notamos que el témino que multiplica a xt se reduce de la siguiente manera:
(B.15) 1−αˉtαt(1−αˉt−1)+1−αˉtαˉt−1βtαˉt1=(1−αˉt)1[αt(1−αˉt−1)+αˉtαˉt−1(1−αt)]=(1−αˉt)1[αtαtαt(1−αˉt−1)+αt1(1−αt)]=(1−αˉt)αt1[αt(1−αˉt−1)+(1−αt)]=(1−αˉt)αt1[αt−αˉt+1−αt]=(1−αˉt)αt1(1−αˉt)=αt1;
y que