CNN con Aumentación de datos
Conjunto de datos de imágenes pequeñas CIFAR10
CNN tomada de los ejemplos de KERAS para explicar el Modelo CNN-Secuencial
Mariano Rivera,
18 Noviembre 2017
El propósito es
-
Introducir la Aumentación de Datos. Este consiste en modificar ligera y aleatoriamente cada imagen del conjunto de entrenamiento con el fin de incrementar la variación de el mismo,
-
Funciones para salvar modelos y pesos
-
Visualización de redes
Según una nota en el ejemplo original
- 75% accuracy en 25 épocas
- 79% accuracy en 50 épocas
Y probablemente aun esta subajustada
La base de datos CIFAR-10 1 consiste
de:
-
60000 imágenes de color de 32x32 pixeles con 10 clases,
-
6000 imágenes por clase.
-
Repartidas en 50,000 imágenes de entrenamiento y 10,000 de prueba.
[1] Alex Krizhevsky, Learning Multiple Layers of Features from Tiny Images, Chpt 3, Tech Rep, 2009.
from __future__ import print_function
import keras
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.utils import plot_model
import numpy as np
import os
Using TensorFlow backend.
Se usará entrenamiento por lotes (batch) que consiste actualizar mediante Backpropagation el gradiente promedio del lote.
La épocas (epoch) son el número de iteraciones totales sobre todos los datos.
Los datos pueden ser aumentados (data_augmentation = True) mediante desplazamientos (shift) de las imagenes, rotaciones, reflexiones. Ver parámetros en ImageDataGenerator
Lectura de imágenes de la base de datos CIFER-10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
(trainimages, numrows, numcols, numcolors) = x_train.shape
# normalización
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
print('x_train shape:', trainimages, numrows, numcols, numcolors)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
x_train shape: 50000 32 32 3
50000 train samples
10000 test samples
Ejemplos de imágenes de CIFER-10
Las categorias son
- airplane
- automobile
- bird
- cat
- deer
- dog
- frog
- horse
- ship
- truck
import matplotlib.pyplot as plt
%matplotlib inline
names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
num_classes=len(names)
fig, ax = plt.subplots(figsize=(13,5), nrows=2, ncols=5, sharex=True, sharey=True,)
fig.suptitle('Casos de cada clase')
ax = ax.flatten()
for i in range(10):
ax[i].imshow(x_train[list(y_train).index(i),:,:,:], interpolation='nearest')
ax[i].set_xlabel(str(i) + ': '+ names[i])
ax[0].set_xticks([])
ax[0].set_yticks([])
#plt.savefig('cimfar-10.png')
plt.show()

Primeras imágenes
import matplotlib.pyplot as plt
%matplotlib inline
rows_imgs=10
cols_imgs=16
fig, ax = plt.subplots(figsize=(16,10), nrows=rows_imgs, ncols=cols_imgs, sharex=True, sharey=True,)
fig.suptitle('Primeras Imágenes')
ax = ax.flatten()
for i in range(rows_imgs*cols_imgs):
ax[i].imshow(x_train[i], interpolation='nearest')
idx = y_train[i][0]
#ax[i].set_xlabel(str(idx)+': '+ names[idx])
ax[0].set_xticks([])
ax[0].set_yticks([])
#plt.savefig('cimfar-10-a.png')
plt.subplots_adjust(wspace=0.01, hspace=0.01)
plt.show()

Histograma de ocurrencia de las clases
Exactamente el mismo número de casos para cada clase de imágen (diferecia de MNIST, que es casi uniforme)
plt.hist(y_test)
num_classes
10

Conversión de etiquetas a vectores indicadores
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
plt.subplots(figsize=(5,5))
plt.imshow(y_train[0:15,:], cmap='gray', interpolation='nearest')
plt.ylabel('Etiqueta')
plt.xlabel('Clases')
#plt.savefig('vectores_infocadores.png')
plt.show()

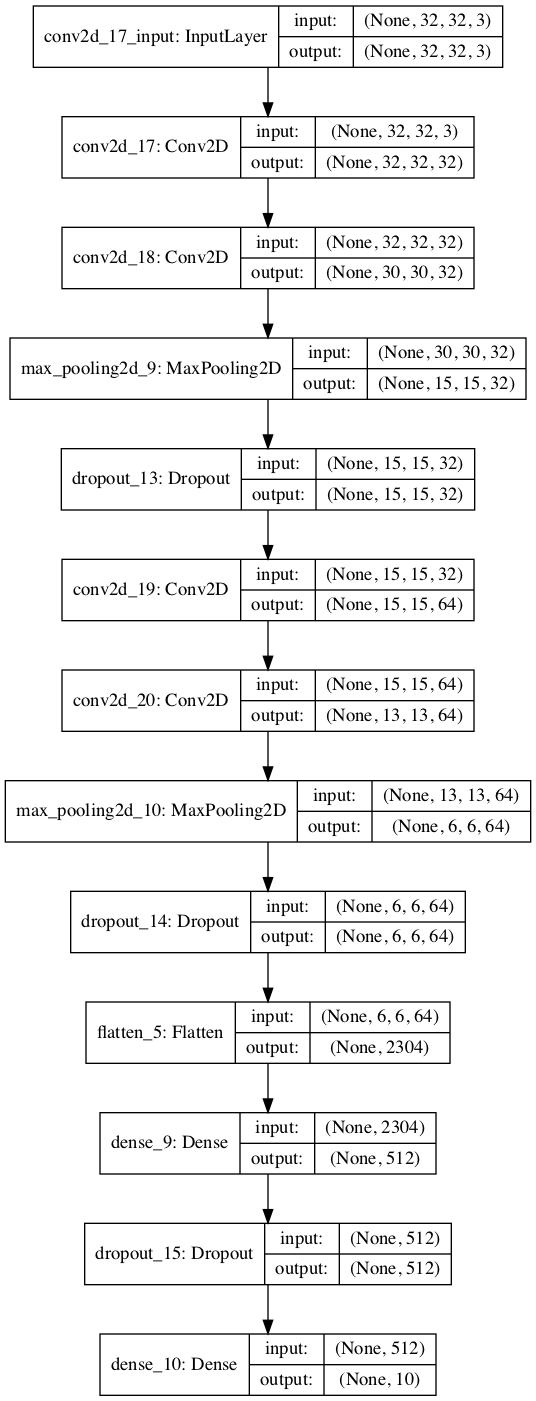
Definición del Modelo CNN-Sequencial
Se observan una arquitectura de dos etapas
1 Etapa tipo CNN:
-
Se incrementa el número de filtros (en 2D: 32->32->64->64)
-
Se reducen las dimensiones de las salidas (Maxpooling)
-
Se controla la complejidad del modelo (Dropout)
2 Etapa de decisión tipop MLP
-
Capa Oculta Plana (de 2D a Plana con capa oculta Flatten)
-
Capa de salida de numClases
model = Sequential()
model.add(Conv2D(filters = 32,
kernel_size = (3, 3),
padding = 'same',
activation = 'relu',
input_shape = x_train.shape[1:]))
model.add(Conv2D(filters = 32,
kernel_size = (3, 3),
activation = 'relu'))
model.add(MaxPooling2D(pool_size= (2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters = 64,
kernel_size = (3, 3),
padding = 'same',
activation = 'relu'))
model.add(Conv2D(filters = 64,
kernel_size = (3, 3),
activation = 'relu'))
model.add(MaxPooling2D(pool_size= (2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(units=512, activation= 'relu'))
model.add(Dropout(0.25))
model.add(Dense(units=num_classes, activation= 'softmax'))
model.summary()
plot_model(model, to_file='cnn_aumenta.png', show_shapes=True)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
conv2d_2 (Conv2D) (None, 30, 30, 32) 9248
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 15, 15, 32) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 15, 15, 64) 18496
_________________________________________________________________
conv2d_4 (Conv2D) (None, 13, 13, 64) 36928
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 6, 6, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 1180160
_________________________________________________________________
dropout_3 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 5130
=================================================================
Total params: 1,250,858
Trainable params: 1,250,858
Non-trainable params: 0
_________________________________________________________________
Inicializando el optimizador
Usaremos el algoritmo de optimización 'rmsprop', y definimos una razón de prendizaje (lr) y un decaimimento de la misma (decay).
opt = keras.optimizers.rmsprop(lr=0.0001, decay=1e-6)
Se compila el modelo, definiendo la función de pérdida, el optimizador y la métrica
model.compile(loss = 'categorical_crossentropy',
optimizer = opt,
metrics = ['accuracy'])
Dos opciones para ajustar el modelo
-
con los datos directamente (sin aumentación de datos)
-
con datos aumentados: usando transformaciones de los datos para aumentar la variabilidad de los ejemplos disponibles
batch_size = 32 # tamaño del lote (batch), originalmente 32
num_classes = 10
epochs = 50 # originalmente 100
data_augmentation = True
# num_predictions = 20
El modelo entrenado (arquitectura y pesos) es almacenado en un archivo para su posterior uso.
Archivo con los resultados: modelo y pesos
save_dir = os.path.join(os.getcwd(), 'saved_models')
model_name = 'keras_cifar10_trained_model.h5'
# This will do preprocessing and realtime data augmentation:
datagen = ImageDataGenerator(
featurewise_center = False, # pone la media de los rasgos a cero el conjunto de datos
samplewise_center = False, # pone cada dato a media cero
featurewise_std_normalization= False, # divide cada razgo entre su desv estandard
samplewise_std_normalization = False, # divide cada dato entre su desv estandard
zca_whitening = False, # aplica blanqueo ZCA
rotation_range = 0, # rota aleatoriamente la imagens estos grados (0 a +-180)
width_shift_range = 0.1, # recorre la imagen horizontalmente una razon alaatoria [0, r]
height_shift_range = 0.1, # recorre la imagen verticalmente una razon alaatoria [0, r]
horizontal_flip = True, # refleja aleatoriamente la imagen en forma horizontal
vertical_flip = False) # refleja aleatoriamente la imagen en forma vertical
# Calcula parametros internos necesario (medias, dev-std, PCA, etc).
datagen.fit(x_train)
# Ajusta el modelo en lotes generados
model.fit_generator(datagen.flow(
x = x_train,
y = y_train,
batch_size = batch_size
),
steps_per_epoch = int(np.ceil(x_train.shape[0] / float(batch_size))),
epochs = epochs,
validation_data = (x_test, y_test),
verbose=1
)
if not data_augmentation:
print('SIN Aumentación de datos.')
model.fit(x = x_train,
y = y_train,
batch_size= batch_size,
epochs = epochs,
validation_split=.2,
shuffle=True)
else:
print('CON Aumentación de datos en tiempo real.')
# This will do preprocessing and realtime data augmentation:
datagen = ImageDataGenerator(
featurewise_center = False, # pone la media de los rasgos a cero el conjunto de datos
samplewise_center = False, # pone cada dato a media cero
featurewise_std_normalization= False, # divide cada razgo entre su desv estandard
samplewise_std_normalization = False, # divide cada dato entre su desv estandard
zca_whitening = False, # aplica blanqueo ZCA
rotation_range = 0, # rota aleatoriamente la imagens estos grados (0 a +-180)
width_shift_range = 0.1, # recorre la imagen horizontalmente una razon alaatoria [0, r]
height_shift_range = 0.1, # recorre la imagen verticalmente una razon alaatoria [0, r]
horizontal_flip = True, # refleja aleatoriamente la imagen en forma horizontal
vertical_flip = False) # refleja aleatoriamente la imagen en forma vertical
# Calcula parametros internos necesario (medias, dev-std, PCA, etc).
datagen.fit(x_train)
# Ajusta el modelo en lotes generados
model.fit_generator(datagen.flow(
x = x_train,
y = y_train,
batch_size = batch_size
),
steps_per_epoch = int(np.ceil(x_train.shape[0] / float(batch_size))),
epochs = epochs,
validation_data = (x_test, y_test),
verbose=1
)
CON Aumentación de datos en tiempo real.
Epoch 1/50
1563/1563 [==============================] - 16s 10ms/step - loss: 0.7176 - acc: 0.7566 - val_loss: 0.6798 - val_acc: 0.7725
Epoch 2/50
1563/1563 [==============================] - 15s 10ms/step - loss: 0.7207 - acc: 0.7568 - val_loss: 0.6627 - val_acc: 0.7742
...
Epoch 50/50
1563/1563 [==============================] - 16s 10ms/step - loss: 0.6975 - acc: 0.7666 - val_loss: 0.6822 - val_acc: 0.7723
Salvar el modelo y los pesos
Primero probamos si existe el diectorio en que pretendemos crear el archivo con el modelo. Si no extste el directorio, creamos el directorio. Luego savamos el modelo y los pesos para su uso posterior.
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
model_path = os.path.join(save_dir, model_name)
model.save(model_path)
print('Saved trained model at %s ' % model_path)
Saved trained model at /home/mariano/Work/deep/03 Aumentacion/saved_models/keras_cifar10_trained_model.h5
Evaluación
scores = model.evaluate(x_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
10000/10000 [==============================] - 1s 60us/step
Test loss: 0.6822211956977844
Test accuracy: 0.7723
Visualizando la calidad de los resultados
import numpy as np
y_pred = model.predict(x_test).squeeze()
y_test_label = np.argmax(y_test,1)
y_pred_label = np.argmax(y_pred,1)
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score, cohen_kappa_score
C=confusion_matrix(y_pred_label, y_test_label)
C
array([[757, 1, 45, 14, 12, 5, 3, 5, 56, 4],
[ 61, 967, 27, 34, 7, 15, 9, 21, 89, 107],
[ 44, 0, 661, 52, 33, 36, 17, 23, 8, 3],
[ 13, 0, 30, 545, 30, 111, 11, 23, 1, 5],
[ 14, 1, 47, 41, 723, 22, 7, 42, 4, 0],
[ 2, 0, 36, 101, 13, 676, 3, 30, 2, 0],
[ 11, 3, 122, 151, 147, 79, 945, 29, 8, 2],
[ 8, 0, 10, 23, 27, 34, 2, 798, 0, 3],
[ 40, 2, 0, 10, 4, 5, 1, 1, 781, 6],
[ 50, 26, 22, 29, 4, 17, 2, 28, 51, 870]])
import seaborn as sns
# En escala logaritmica !
#plt.title('Confusion Matrix')
sns.heatmap(C, xticklabels=np.arange(10), yticklabels=np.arange(10))
<matplotlib.axes._subplots.AxesSubplot at 0x7f2ba2c76cc0>

Precisión
Precisión es la probabilidad de que un dato selecionado aleatoriamente sea relevante
precision_score(y_pred_label, y_test_label, average='macro')
0.7722999999999999
Recall
Recall es la probabilidad de que un dato relevante sea selecionado aleatoriamente.
recall_score(y_pred_label, y_test_label, average='macro')
0.7834164096901158
F1-score
Media armónica de la presición y el recall. Penaliza el desvalance entre las métricas P y R
f1_score(y_pred_label, y_test_label, average='macro')
0.7698401196767117
Falta mas entrenamiento …
print('Clasificados correctamente =', np.sum(np.diag(C))/np.sum(C[:])*100, r'%')
Clasificados correctamente = 77.23 %
Modelo Final
from __future__ import print_function
import keras
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
import numpy as np
import os
# - - - - - - - - - - - - - - - - - - - - - - - - - - - -
# Lectura y preprocesamiento de los datos
# - - - - - - - - - - - - - - - - - - - - - - - - - - - -
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
(trainimages, numrows, numcols, numcolors) = x_train.shape
# normalización
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
print('x_train shape:', trainimages, numrows, numcols, numcolors)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# conversion de etiquetas a vectores indicadores
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# - - - - - - - - - - - - - - - - - - - - - - - - - - - -
# CCN
# - - - - - - - - - - - - - - - - - - - - - - - - - - - -
model = Sequential()
model.add(Conv2D(filters = 32,
kernel_size = (3, 3),
padding = 'same',
activation = 'relu',
input_shape = x_train.shape[1:]))
model.add(Conv2D(filters = 32,
kernel_size = (3, 3),
activation = 'relu'))
model.add(MaxPooling2D(pool_size= (2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters = 64,
kernel_size = (3, 3),
padding = 'same',
activation = 'relu'))
model.add(Conv2D(filters = 64,
kernel_size = (3, 3),
activation = 'relu'))
model.add(MaxPooling2D(pool_size= (2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(units=512, activation= 'relu'))
model.add(Dropout(0.25))
model.add(Dense(units=num_classes, activation= 'softmax'))
# definicion del optimizador
opt = keras.optimizers.rmsprop(lr=0.0001, decay=1e-6)
# compilacion del modelo
model.compile(loss = 'categorical_crossentropy',
optimizer = opt,
metrics = ['accuracy'])
# Parametros para Entrenamiento
batch_size = 32 # tamaño del lote (batch), originalmente 32
num_classes = 10
epochs = 50 # originalmente 100
data_augmentation = True
# num_predictions = 20
save_dir = os.path.join(os.getcwd(), 'saved_models')
model_name = 'keras_cifar10_trained_model.h5'
# - - - - - - - - - - - - - - - - - - - - - - - - - - - -
# Entrenamiento CON/SIN aumentación
# - - - - - - - - - - - - - - - - - - - - - - - - - - - -
if not data_augmentation:
print('SIN Aumentación de datos.')
model.fit(x = x_train,
y = y_train,
batch_size= batch_size,
epochs = epochs,
validation_split=.2,
shuffle=True)
else:
print('CON Aumentación de datos en tiempo real.')
# This will do preprocessing and realtime data augmentation:
datagen = ImageDataGenerator(
featurewise_center = False, # pone la media de los rasgos a cero el conjunto de datos
samplewise_center = False, # pone cada dato a media cero
featurewise_std_normalization= False, # divide cada razgo entre su desv estandard
samplewise_std_normalization = False, # divide cada dato entre su desv estandard
zca_whitening = False, # aplica blanqueo ZCA
rotation_range = 0, # rota aleatoriamente la imagens estos grados (0 a +-180)
width_shift_range = 0.1, # recorre la imagen horizontalmente una razon alaatoria [0, r]
height_shift_range = 0.1, # recorre la imagen verticalmente una razon alaatoria [0, r]
horizontal_flip = True, # refleja aleatoriamente la imagen en forma horizontal
vertical_flip = False) # refleja aleatoriamente la imagen en forma vertical
# Calcula parametros internos necesario (medias, dev-std, PCA, etc).
datagen.fit(x_train)
# Ajusta el modelo en lotes generados
model.fit_generator(datagen.flow(
x = x_train,
y = y_train,
batch_size = batch_size
),
steps_per_epoch = int(np.ceil(x_train.shape[0] / float(batch_size))),
epochs = epochs,
validation_data = (x_test, y_test)
)
# - - - - - - - - - - - - - - - - - - - - - - - - - - - -
# Salva el modelo entrenado
# - - - - - - - - - - - - - - - - - - - - - - - - - - - -
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
model_path = os.path.join(save_dir, model_name)
model.save(model_path)
print('Saved trained model at %s ' % model_path)
# - - - - - - - - - - - - - - - - - - - - - - - - - - - -
# Evalua el modelo entrenado
# - - - - - - - - - - - - - - - - - - - - - - - - - - - -
scores = model.evaluate(x_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])