[1] T. Hastie, R. Tibshirani and J Friedman, The elements of Statistical Learning, 2nd Ed. Springer, 2009.
import numpy as np
import sklearn as skl
import matplotlib.pyplot as plt
from PIL import Image
Regresión Ridge
El propósito es mantener el menor número de perdictores descartando el resto. Con ello se gana interpretabilidad y mejora el error de generalización
Asumamos una muestra aleatoria x de tamaño m:
(1) X=⎣⎢⎢⎢⎡x1⊤,x2⊤,⋮xm⊤⎦⎥⎥⎥⎤
con xi∈Rn.
Donde denotamos xi la i-ésima observación. Luego X denota la variable de entrada genérica, Xj su j-ésimo componente; como xij el j-ésimo componente de la i-ésima observación.
En estas notas usemos la regresión lineal como ilustración:
(2) yi=b+xi⊤θ+ηi
donde θ∈Rn, b∈R1 el interceptor.
Luego la regresion Ridge esta dada por:
(3) bridge,θridge=b,θargmin∥y−b−Xθ1…n∥2+λ∥θ∥22
con el parámetro de complejidad λ≥0 que controla el grado de encogimiento.
Forma centrada de Ridge
Note que la penalización no se hace sobre el interceptor b.
De hecho es fácil notar que si se usan datos centrados: xij←xij−xˉj
Entonces en toma una forma mas simple, el iterceptor estará dado por
(4) bridge≡yˉ=m1i∑yj
luego hacemos:
yi←yi−yˉ
Lo que nos lleva a la forma centrada Ridge:
(5) θridge=θargmin∥y−Xθ∥2+λ∥θ∥2
Consideremos la versión simplificada (centrada) en (5), luego resolviendo para el gradiente:
θridge=(X⊤X+λI)−1X⊤Y
Es decir, le esta sumando λ a la diagonal de la matriz Hessiana X⊤X, lo que ayuda a mejorar su condición
Forma de Mínimos cuadrados de Ridge
Proposición.
La Regularización Lineal Ridge (5) es equivalente al problema de mínimos cuadrados:
(6) θridge=θargmin∥b−Aλθ∥22
Donde
Aλ=def[XλI],
b=def[y0]
Proof.
Es fácil demostrar que
∥y−Xθ∥22+λ∥θ∥22=∥b−Aλθ∥22
Aquí esta el álgebra ∥y−Xθ∥2+λ∥θ∥2=(y−Xθ)⊤(y−Xθ)+λθ⊤θ=[y−Xθ0−λIθ]⊤[y−Xθ0−λIθ]=[b−Aλθ]⊤[b−Aλθ]=∥b−Aλθ∥22.
Forma restringida de Ridge
El potencial (3) puede escrito en forma equivalente como un problema con restricciones:
(7) bridge,θridge=b,θargmin∥y−b−Xθ∥2sujeto a ∥θ∥2≤t
para algun valor de t en correspondencia a λ. El programa (7) explícitamente impone una restricción en el tamaño de los parámetros.
Dado que se penaliza el cuadrado del la magnitud, el inconveniente principal de la regresión Ridge es que se promoverá que aparezcan varios valores pequeños en vez de uno grande (no promueve ralez).
# Modelo Cuadrático: y = x'Ax+ x'b = x'(Ax+b)# matriz de rotacion (eigen vectores)
alpha=np.pi/12
R = np.matrix([[np.cos(alpha),np.sin(alpha)],[-np.sin(alpha),np.cos(alpha)]])# eigenvalores
D = np.matrix([[1,0],[0,0.2]])# Hessiano
A =3*np.dot(R,np.dot(D,R.T))# translacion
b = np.matrix([[-1],[-2]])#Region a "plotear"
delta =0.05
x1 = np.arange(-0.5,2.0, delta)
x2 = np.arange(-0.5,2.0, delta)
X1, X2 = np.meshgrid(x1, x2)# calculo del modelo cuadratico
rows, cols = X1.shape
Y = np.zeros((rows,cols))for i inrange(rows):for j inrange(cols):
x = np.matrix([X1[i,j],X2[i,j]]).T
Y[i,j]= np.dot(x.T, np.dot(A,x)+ b)
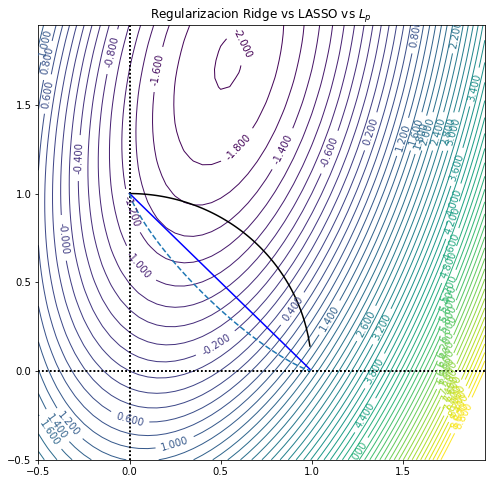
Para la norma Lp:
Lp(x)=def[i∑∣xi∣p]p1
y toma valores interesantes para 0<p≤1.
Por ejemplo, para el caso ilustrado en dos dimensiones:
Lp([x,y]T)=[xp+yp]p1=1
luego
y=[1−xp]p1
plt.figure(figsize=(8,8))# El potencial Quadrático
levels = np.arange(-2.0,9,0.2)
CS = plt.contour(X1, X2, Y, levels,
linewidths=1,
extent=(-3,3,-2,2))#CS = plt.contour(X1, X2, Y)
plt.clabel(CS, inline=1, fontsize=10)
plt.title('Regularizacion Ridge vs LASSO vs $L_p$ ')#-------------------------------------#Penalizacion L_2
x = np.arange(0,1,0.01)
y = np.sqrt(1-np.power(x,2))
plt.axvline(0.0,ls='dotted', color='k')
plt.axhline(0.0,ls='dotted', color='k')
plt.plot(x,y,'k')#-------------------------------------#Penalizacion L_1
x = np.arange(0,1,0.01)
y =1-x
plt.axvline(0.0,ls='dotted', color='k')
plt.axhline(0.0,ls='dotted', color='k')
plt.plot(x,y,'b')#-------------------------------------#Penalizacion L_p, con p=0.4
x = np.arange(0,1,0.01)
p =.8
y = np.power(1-np.power(x,p),1/p)
plt.axvline(0.0,ls='dotted', color='k')
plt.axhline(0.0,ls='dotted', color='k')
plt.plot(x,y,'--')#-------------------------------------
plt.show()
Notemos que conforme p↓0, el punto en que la fontera (lineas mostradas) de la región factible y las curvas de nivel de la función objetivo son tangentes se acerca al eje, lo que resulta en una solución mas informativa (que tienen menor entropía o se aaproxima más aser una variable indicadora).
Equivalencia en Minimización L1 y Programación Lineal
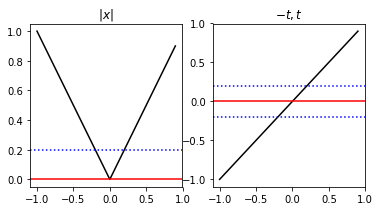
En una dimensión es fácil observar la equivalencia entre el problema de optimización de valor absoluto
xmin∣x∣
y el LP
θminθs.a.−θ≤x≤θθ≥0
Esto se puede generalizar a n dimensiones como el problema de optimización L1
xmin∥Ax−b∥1
Con su equivalente LP
θ∈Rnmin1⊤θs.a.−θ⪯Ax−b⪯θθ⪰0
plt.figure(figsize=(6,3))#-------------------------------------
plt.subplot(121)
plt.title('$|x|$')
x = np.arange(-1,1,0.1)
y = np.abs(x)
plt.plot(x,y,'k')
plt.axhline(0.2,ls='dotted', color='b')
plt.axhline(0.0, color='r')#-------------------------------------
plt.subplot(122)
plt.title('$-t, t$')
x = np.arange(-1,1,0.1)
y = np.abs(x)
plt.plot(x,x,'k')
plt.axhline(0.2,ls='dotted', color='b')
plt.axhline(-0.2,ls='dotted', color='b')
plt.axhline(0.0, color='r')#-------------------------------------
plt.show()
Los pasos son iterados hasta convergencia. El punto es ¿como se resuelve el paso 3?
Forma Restingida de la Regresión LASSO
Similarmente a la regresión Ridge, se puede demostrar que (9) tienen una forma equivalente con restricciones:
(10) θlasso=θ∈Rnargmin∥y−Xθ∥2+λtsujeto a t−θ≥0t+θ≥0t≥0
para algún valor de t en correspondencia a λ. El programa (10) explícitamente impone una restricción en el tamaño de los parámetros.
Regresión LASSO Algoritmo Shooting
Propuesto para LASSO por W. J. Fu [2], el asesor de Tibsharini. Pero en su momento no valorado por Tibsharini.
Tibsharini & Hastie lo prueban, concluyen que falla en base a que la Implementación (equivocada) de Hastie no funciona (segun sus propias palabra en Tutoriales).
Hasta que es usado por Friedman en Elastic Net y funciona, Lo usan T-H-F en LASSO, 2006!
Ahora, Tibsharini & Hastie son unos de sus mayores difusores.
[2] W. J. Fu. Penalized Regressions: The Bridge Versus the Lasso. Journal of Computational and Graphical Statistics, 7:397-416, 1998.
Análisis en Mínimos cuadrados 1D
Primero haremos una reflexion para el caso del problema de mínimos cuadrados unidimensional:
(11) θ∈R1argmin21∥yi−xiθ∥2
que tiene como solución:
θ∗=xi⊤xixi⊤yi
asumiendo xi,yi=0, lo cual hace que nuestro problema tenga sentido. Entonces θ∗=0 ssi xi⊤yi=0.
Bueno, los métodos que penalizan la norma incluyen a 0 en la región factible, de hecho es a donde tiende a encoger la solución. Por lo que, no importa que penalización de norma se adicione a (11), la solución seguira siendo θ∗=0.
Esto es:
La solución a
(12) θ∈R1argmin21∥yi−xiθ∥2+λ∥θ∥V
es θ∗=0 si xi⊤yi=0 dado que ∥0∥V=0.
Algoritmo Shooting
Consideremos el caso (12) para LASSO en caso que xi⊤yi=0
(13) θ∈R1argmin21∥yi−xiθ∥2+λ∣θ∣
que podemos escribir en forma restringida
(14) θ∈R1argmin21∥yi−xiθ∥2+λtsujeto a t−θ≥0t+θ≥0t≥0
Para resolver el problema, escribimos el Lagrangiano
con el parámetro λ1>0 que promueve ralez y el parámetro λ2>0 que controla el grado de encogimiento.
Es posible introducir, el Término de Ridge en el términos de datos (prímer potencial) mediante la transformación vista de Ridge a mínimos cuadrados y usar el solucionador de LASSO.
Método de los Multiplicadores con Direcciones Alternadas para LASSO
[2] Boyd, notes on ADMM [online], Alternating Direction Multipliyig Method (ADMM) for LASSO
El problema LASSO se puede reescribir como
x,zmin21∥Ax−b∥22+λ∥z∥1s.a.x−z=0
Luego el Lagrangiano Aumentado se puede escribir como
LA(x,z,u)=21∥Ax−b∥22+λ∥z∥1+2ρ∥x−z−u∥22
Y su solución se obtiene altenando:
Resolver para x ∇xLA=0, esto es, resolver (A⊤A+ρI)x=A⊤b+ρz−u
Resolver para z ∇zLA=0, esto es z=Sρλ(x+u/ρ)
Actualizar u con asceso de gradiente: u=u+ρ(x−z)
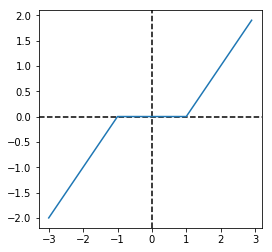
Donde Sθ(x) es la función soft-threshold definida como
Sθ(x)=⎩⎨⎧x−θ0x+θx>θ−θ≤x≤θx<θ
import matplotlib.pyplot as plt
import numpy as np
#-------------------------------------# Soft Treshold functiondefsoftTreshold(x, theshold=1):
s = np.zeros(x.shape)
idx = x <-theshold
s[idx]= x[idx]+theshold
idx = x > theshold
s[idx]= x[idx]-theshold
return s
#-------------------------------------
x = np.arange(-3.0,3.0,0.1)
plt.figure(figsize=(4,4))
plt.axvline(0.0, ls='dashed', color='k')
plt.axhline(0.0, ls='dashed', color='k')
plt.plot(x,softTreshold(x, theshold=1))
plt.show()
Ejemplo de Regresión LASSO
import numpy as np
import scipy.linalg as spla
m=1000
n=2
theta = np.random.rand(3)print(theta)# Matriz de diseño real
x = np.random.rand(m,n)
X = np.concatenate((np.ones((m,1)),x), axis=1)
n =0.1*np.random.randn(m)# variable dependiente
y = X@theta + n
# Matriz de diseño extendida
Xn = np.concatenate((X, x**2), axis=1)
[ 0.01945935 0.57451632 0.28247946]
Solución mediante AMDD
x=(A⊤A+ρI)−1A⊤b+ρz−u
z=Sρλ(x+u/ρ)
u=u+ρ(x−z)
#-------------------------------------defls_AMDD_LASSO(X, y, Lambda=.1, rho=.1, niter =10, epsilon =1e-2):(m,n)= X.shape
theta = np.zeros(n)
u = np.zeros(n)
z = np.zeros(n)
M = spla.inv(X.T@X + rho*np.eye(n)) @ X.T
for t inrange(niter):
theta = M@y + rho*z - u
z = softTreshold (theta+u/rho, theshold=Lambda/rho)
delta=theta-z
if spla.norm(delta)< epsilon:break
u += rho*delta
return(theta, z, u, delta, t)#-------------------------------------
thetaLasso, z, u, delta, t = ls_AMDD_LASSO(Xn, y, Lambda=.05, rho=.1, niter=1000, epsilon =1e-5)print(z,t)print(thetaLasso)