Sea xi∈Rn un vector que corresponde al i-ésimo dato tal que la j-ésima entrada xij corresponde a la j-ésima característica. Luego arreglamos los datos de la forma
(1) X=⎣⎢⎢⎢⎡x1⊤x2⊤⋮xm⊤⎦⎥⎥⎥⎤,
de tal que cada dato correponde a un renglón de la matrix X∈Rm×n.
Luego tenemos una observacion yi∈Rk (generalmente k=1) asociada a cada dato, variable dependiente. Y denotamos por
(2) Y=⎣⎢⎢⎢⎡y1⊤y2⊤⋮ym⊤⎦⎥⎥⎥⎤,
la matriz de variables dependientes, cadad renglón en una variable dependiente.
Regresión lineal multivariada
Ahora que asumimos que existencia de una función desconocida
(3) yi=f(xi)+ηi
donde f es “suave” y ηi es ruido. El problema de regresión es estimar f a partir de una serie de datos X,Y.
Existen muchas maneras de proponer la función f. Por ejemplo, usando polinomios:
(4) yil=θ0l+θ1lxi1+θ2lxi2+…+θnlxin+ηli
La función (4) se pueded escribir como:
En cuyo caso, lo que cambia es el cálculo de la matriz de diseño X.
Mínimos Cuadrados Lineales
Una forma de resolver el problema de estimar los parámetros Θ de la función f es mediante mínimos cuadrados lineales, capítulo 3 en [3]: Θ∗=ΘargminF(Θ)=21∥Y−XΘ∥F2(9)
donde la norma de Frobenius esta definida por ∥A∥F2=i∑j∑aij2.
En este contexto X es llamada la “matriz de diseño”.
La función F puede también ser escrita como
(10) F(Θ)=l∑i∑[Yil−j∑XijΘjl]2=l∑i∑[Yil−xi⊤θl]2=i∑[Yi1−xi⊤θ1]2+i∑[Yi2−xi⊤θ2]2+…+i∑[Yik−xi⊤θk]2
Es decir, el problema de estimación de mínimos cuadrados vector-valuado (la variable dependiente es un vector), se puede descomponer como múltiples problemas independientes de mínimos cuadrados univaluados (la variable dependiente es un escalar).
Solución Exacta al Problema de Mínimos Cuadrados Lineales
Como ya vimos, sin pérdida de generalidad, podemos concentrarnos solo en el caso univariado:
Donde hemos incluido el factor 1/2 por conveniencia en el algebra que desarrollaremos y dado que no afecta el problema: θargminF(θ)=ΘargmincF(θ)
para cualquier constante c∈R.
Dado que (11) es convexa, el mínimo se encuetra resolviendo la condición de primer orden:
(12) ∇θF(θ)=0,
esto es:
(13) XT(Xθ−Y)=0
Luego, θ se puede calcular resolviendo
(14) X⊤Xθ=X⊤Y
o directamente:
(15) θ=(X⊤X)−1X⊤Y.
Recordemos que en general X es singular dado que tenemos mas datos que parámetros a estimar m>n+1. Luego definimos la matriz M=(X⊤X)−1X⊤
que es llamada la pseudo-inversa de Moore-Penrose de X dado que satisface MX=I.
Si el problema es multivaluado, entonces:
(16) θl=MYl;l=1,2,…,k
Es decir, todo se reduce a calular M.
Usando el modelo, podemos obtener la predicción de los valores de Yl:
Y^l=Xθl=PYl
donde
P=X(X⊤X)−1X⊤
es la “Matriz de Proyección” porque lleva los datos Yl al espacio generado (spanned) por el regresor. Lo que implica en si mismo un residual de modelado.
Solución iterativa al problema de mínimos cuadrados
Otra forma de resolver el problema de mínimos cuadrados es usando algorirmos iterativos, algo comun en problemas de optimización.
Esta estrategia de solución es preferida para problemas de gran escala: m's o n's grandes
Para ello usamos la formula de recurrencia
(17) θ(t+1)=θ(t)+α(t)p(t)
donde
θ(t) es en valor de los parámetros en la iteración actual
θ(t+1) es en valor de los parámetros actualizados
p(t) es una dirección de descenso. Garantiza que F(θ(t)+ϵp(t))≤F(θ(t)) para una ϵ suficientemente pequeña.
α(t) es el tamaño de paso
Nota: p es una dirección de descenso ssi p⊤∇F<0; la elección obvia es la denominada “dirección de máximo descenso”: p=−∇F, ¡Que no es necesariamente la mejor!
Obtengamos el gradiente parcial de F respecto a un parámetro, digamos el θj^:
(18) ∂θj^∂F=i∑[Yi−xiTθ]∂θj^∂[Yi−j∑xijθj]=i∑[Yi−xiTθ](−xij^)
Luego el gradiente esta dado por
Podemos ver que en (19) se actualiza cada entrada de θ independientemente. Luego una entrada del vector de parámetros se actualiza con la regla
(20) θj(t+1)=θj(t)−αi∑(xiTθ−Yi)xij
donde hemos asumido que el tamaño de paso α, conocido como “razón de aprendizaje” en el contexto de aprendizaje de máquina, es pequeño e igual para todas las iteraciones.
El procedimiento (20) es conocido como algoritmo de descenso de gradiente.
Reducción del error respecto a una sola muestra xi
Solo por curiosidad, tomamos la muestra xi y ajustemos el θj. Ahora la regla de aprendizaje queda
(21) θj(t+1)=θj(t)−α(xi⊤θ−Yi)xij
que es es la regla de aprendizaje de Widrow-Hoff.
Se pueded observar que la magnitud de la actualización es proporcional al error (Yi−xi⊤θ): si hay una muestra donde el error es pequeño, el ajuste será pequeño; si por otro lado para una muestra el error es grande, se hará un ajuste grande.
Ejemplo de Mínimos Cuadrados
Dado el modelo lineal yi=θ0+xi1θ1+x2θi2+ni
Generaremos m=10 muestras y ajustamos los parámetros θ con:
Usando el solver en scipy.linalg.lsts
Pseudo-inversa de Moore-Penrose (numpy)
Descenso de gradiente
import numpy as np
import scipy.linalg as spla
m=100
n=2
theta = np.random.rand(3)print(theta)# Matriz de diseño
X = np.concatenate((np.ones((m,1)),np.random.rand(m,n)), axis=1)
n =0.01*np.random.randn(m)# variable dependiente# y = np.dot(X,theta)+n
y = X@theta + n
[ 0.62450876 0.04722106 0.98380124]
Solver en scipy.linalg.lstsq
theta_ls=spla.lstsq(X,y)
theta_ls[0]
array([ 0.62408591, 0.04626653, 0.98832767])
Pseudoinversa de Moore-Penrose
# M = np.dot(la.inv(np.dot(X.T,X)),X.T)# theta_mp=np.dot(M,y)# con el nuevo operador de multiplicacion de matrices @ en vez de np.dot
theta_mp =(spla.inv(X.T@X)@X.T)@y
theta_mp
array([ 0.62408591, 0.04626653, 0.98832767])
Solución mediante descenso de gradiente simple
Formula de actualización iterativa: θt+1=θt+αtpt
donde
θt es el valor actual de los parámetros
pt es la dirección de descenso: pt≡−∇f(θt) para el caso de descenso de gradiente.
αt es el tamaño de paso: αt≡constante pequeña para decenso de gradiente simple.
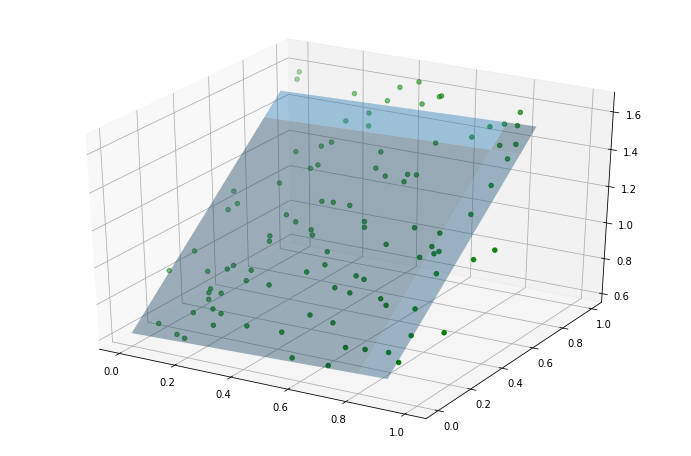
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
plt.figure(figsize=(12,8))
fig = plt.figure(figsize=(12,8))
ax = fig.gca(projection='3d')
v = np.arange(0,1,0.1)
w = np.arange(0,1,0.1)
x1, x2 = np.meshgrid(v, w, sparse=True)
haty = theta_dg[0]+ theta_dg[1]*x1+ theta_dg[2]*x2
ax.scatter(X[:,1], X[:,2], y, c='g')
ax.plot_surface(x1, x2, haty, rstride=8, cstride=8, alpha=0.4)
plt.show()
<Figure size 864x576 with 0 Axes>
Mínimos Cuadrados Lineales como un Problema de Estimación de Máxima Verosimilitud
Regresando al modelo mediante el cual asumimos se relacionan las variables dependientes y y las independientes x:
(22) yi=xi⊤θ+ηi.
Donde habiamos dicho que ηi era ruido. Bueno, este ruido tienen una distribución y puede estar, o no, correlacionado.
Asumamos que no es correlacionado y su distribución se mantienen no cambia dependiendo de las muestras; esto es es ruido Independiente e Identicamente Distribuido (IID).
Además asumamos, ahora, que tienen distribución Gaussiana con media cero y varianza σ2: ηi∼N(0,σ2).
Luego, la densidad de ηi esta dada por
(23) p(ηi)=2πσ1exp[−2σ2ηi2]
Recordemos que ∫−∞∞p(η)dη=1 pero la probabilidad de que ηi=c esta dada por ∫ccp(η)dη=0.
Luego de (22) obtenemos que ηi=yi−xi⊤θ lo que implica, usando (23), que
(24) p(yi∣xi;θ)=2πσ1exp[−2σ21(yi−xi⊤θ)2]
p(yi∣xi;θ) se lee como la probabilidad condicional de yi dado xi; usando los parámetros (no son variables aleatorias) θ.
La notación p(yi∣xi;θ) indica que en nuestro modelo $ \mathbf{y}_i$ depende de xi (variable dependiente e independiente, respectivamente) a través de los parámetros θ.
Nosotros estamos interasados en estimar la función que relaciona los datos observados y y X. Note que ya estamos hablando de todos dos datos, no solo del i-ésimo.
Esta función que relaciona a y y a X depende de los parámetros desconocidos θ.
Por lo que es conveniente introducir una función que se vea explicitamente como función de θ.
Función de verosimilitud
Esta función se denomina verosimilitud (likelihood):
(25) L(θ)=L(θ;y,X)=p(y∣X;θ)
Donde p(y∣X;θ) es la probabilidad de toda la muestra; (24) es la probabilidad del i-ésimo dato.
Dado que asumimos que ηi es IDD:
(26) L(θ)=p(y∣X;θ)=i∏p(yi∣xi;θ)=i∏2πσ1exp[−2σ21(yi−xi⊤θ)2]=2πσ1exp[−2σ21i∑(yi−xi⊤θ)2]
Función de log-verosimilitud y los Mínimos Cuadrados
Dado que maxxf(x)=maxxg(f(x)) si g es estrictamente creciente. Por ejemplo g1(x)=log(x), g2(x)=x2 ambas cumplen para para x>0.
Luego en vez de maximizar la verosimilitud, uno pueded maximizar la log-verosimilitud: l(θ)=logL(θ)
Entonces, maximizar l(θ) equivale a resolver la minimización:
(28) min21i∑(yi−xi⊤θ)2
que resulta ser el problema de mínimos cuadrados original.
¿Como llegamos a ello?
Asumimos un modelo generador que relacional las variables independientes a partir de las dependientes
Asumimos un modelo de ruido: IID y Gaussiana.
La suposición IID implicó suma de residuos (errores) independientes en cada muestra.
La distribución del ruido fue determinante que la log-verosimilitud se reduzca a la norma L2
Nótese: otra distribución del ruido implicará otra norma.
Mínimos Cuadrados No-Lineales
Recordemos, los datos son denotados por
xi∈Rnyi∈RX∈Rm×nY∈Rm
Como ya vimos, basta que analicemos la regresion monovaluada. Ahora, en el modelo (3) asumamos no-lineal función f:Rn→R y que dicha función es evaluada dados unos parámetros θ∈Rk:
(29) yi=f(xi;θ)+ηi.
Nóte que al escribir el modelo (29) hemos puesto un ‘;’ entre la x y θ. La razón es que queremos enfatizar que la función “produce” valores conforme cambiamos x, y que el hecho de que, por ahora, no conozcamos los valores de los parámetros θ es circunstancial. Una vez que la caractericemos (estimemos θ) computaremos valores f(x).
Para estimar θ, definimos una función que depende explícitamente de su valor. Por ello, definimos el residual:
(30) ri(θ)=yi−f(xi,θ)
Luego, en un esquema de mínimos cuadrados (no lineales), los parámetros θ los puedemos estimar mediante la solución del problema de optmización:
Donde definimos el “Jacobiano” J de una función vectorial como:
(34) Jij=∂θj∂ri
Entonces
(35) J(θ)⊤=∇θr(θ)=[∇θr1(θ),∇θr2(θ),…,∇θrm(θ)]
Entonces, J(θ)⊤ es el gradiente de cada una de las funciones ri acomodado columna por columna.
El algortimo de descenso de gradiente estará dado por:
(36) θt+1=θt−αi∑ri(θ)∇θri(θ)=θt−αJ(θ)⊤r(θ)
Newton, Gauss-Newton y Levenberg-Marquardt
Sin dar ninguna derivación formal, aqui introducimos directamente métodos mas eficientes de optimizacion de mínimos cuadrados no-lineales; ver su derivación en un texto de Optimizacion Numérica [2]_.
Los métodos de Newton calculan la actualización usando:
(37) θt+1=θt−αpt
donde α se escoge tal que F(θt+1)≤F(θ) y la dirección de descenso p es solución de alguno de los tres siguientes:
Newton
(38) [J(θ)⊤J(θ)+H(θ)r(θ)]p=−J(θ)⊤r(θ)
donde H(θ)r(θ)=i∑ri(θ)∇θ2ri(θ)
Tal que H es el Hessiano de r y ∇θ2ri es el Hessiano de ri.
2. Gauss-Newton
(39) J(θ)⊤J(θ)p=−J(θ)⊤r(θ)
Levenberg-Marquardt (LM)
(40) [J(θ)⊤J(θ)+τI]p=−J(θ)⊤r(θ)
con τ>0 garantizando que la matriz tenga un número de condición apropiado para ser establemente resuelto el sistema.
El método de Newton no es el preferido debido a:
Require calcular Hessianos costosos
Si los residuales ri se distribuyen con media cero, en el óptimo es de esperarse que el término extra se cancele: suma de residos pesados
Los datos atípicos (outliers), harían que la suma no se cancelaría e introducirían error en el método.
[2] J. Nocedal and S. J. Wright, Numerical Optimization, Springer 2nd Ed., 2006.
Gradiente estocástico
Como podemos observar la función de costo de mímimos cuadrados (lineales o no-lineales) puede escribirse como la suma de residuos individuales: la suma corre sobre todos los residuales. En el caso de problemas de aprendizaje de máquina, estos residuales se asocian con los datos y la suma se hace sobre toda la población. Esto admite una interpretación extra: la funcion de costo y su gradiente se pueden ver como esperanzas:
Si en vez de considerar toda la población, consideramos a la media muestral como estimador de la función de costo y su gradiente:
(43) F^(θ)=21i∈S∑ri(θ)2
(44) ∇θF^(θ)=i∈S∑ri(θ)∇θri(θ)
Donde S⊂{1,2,3,…,m} determina la muestra. Si se usa el F^(θ) en vez de F(θ) en el procedimiento iterativo de optimización el algoritmo se denominará:
Gradiente estocástico, Newton-estocástico, Gauss-Newton estocástico, LM estocástico, Quasi-Newton estocástico, etc.
Estas variantes estocásticas de algoritmos deterministas han sido extensivamente usadas en problemas de gran escala y sobre todo en problemas relacionados con técnicas llamadas de APRENDIZAJE PROFUNDO (DEEP LEARNING).
Su ventaja es que evitan ser atrapados por mínimos locales y son computacionalmente eficientes.
Regresión Logística
Consideremos el problema de clasificación binaria donde los datos se denotan por
xi∈Rnyi∈{0,1}X∈Rm×nY∈{0,1}m
donde asumimos que a todos los datos les hemos agregado un 1 en su primer entrada xi1=1 y a partir del 2do. elemento se tienen las características observadas. Esto simplifica la notación al escribir el sistema lineal.
Luego
X=⎣⎢⎢⎢⎢⎢⎡x1⊤x2⊤x3⊤⋮x3⊤⎦⎥⎥⎥⎥⎥⎤
El algoritmo de regresión logística es un algoritmo de clasificación binaria para clases linealmente separables, capítulo 4 en [3], pero donde existen datos que se confunden (no exactamente linelamente separables).
Es un poco extraño, es un clasificador, pero se le denomina “regresión” logística. Si somos un poco pacientes, entenderemos el porque del nombre.
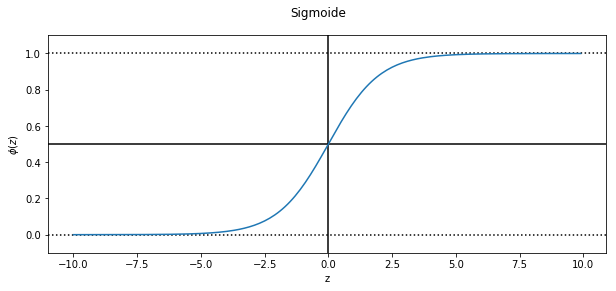
Primero introducimos la función sigmoide (que tiene forma de sigma o ‘s’):
(45) ϕ(z)=1+exp(−z)1
La función (45) se grafica en seguida usando Python
[3] T._Hastie et al., The elements of Statistical Learning, 2nd Ed. Springer, 2009.
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
defsigmoid(z):return(1/(1+np.exp(-z)))
T =10
z = np.arange(-T,T,0.1)
plt.figure(figsize=(10,4))
plt.axvline(0.0,color='k')
plt.axhline(0.0,ls='dotted', color='k')
plt.axhline(1.0,ls='dotted', color='k')
plt.axhline(0.5,color='k')
plt.plot(z,sigmoid(z))
plt.ylim(-.1,1.1)
plt.xlabel('z')
plt.ylabel('$\phi(z)$')
plt.suptitle('Sigmoide')
plt.show()
Recordenos que el i-ésimo dato esta dado por el vector columna xi. Ahora, asumiremos que las etiquetas binarias estarán sujetas al modelo
(46) yi=ϕ(xi⊤ω)+ηi
donde los parámetros ω∈Rk son tal que el hiperplano
xi⊤ω>0siyi=1
y
xi⊤ω<0siyi=0;
luego, la sigmoide ϕ:R→[0,1] hará el resto del trabajo: ajustar los valores del hiperplano a las etiquetas. Los errores en classificación y residuales se representan por η.
Usando una estrategia de mínimos cuadrados no lineales, ω se puede estimar mediante:
(47) argωminF(ω)=21i=1∑m[yi−ϕ(xi⊤ω)]2
En este caso, el gradiente estará dado por las parciales
Sin embargo, mejor tomemos un enfoque probabilista para derivar el algoritmo de ML para la Regresión Logística , y veamos si tenemos una ventaja.
Derivación Probabilística de la Regresión Logística
Asumamos p la probabilidad de que ocurra un evento, luego 1−p será la probabilidad de que no ocurra.
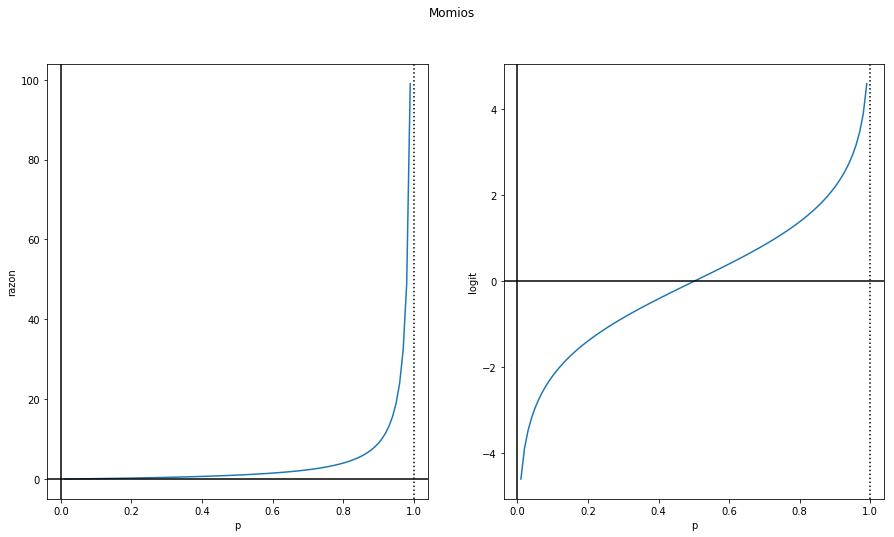
Ahora, ¿que tanto es mas probable que ocurra el evento a que no ocurra? Para responder esta pregunta calculamos los momios (odd ratios), que es la razón:
(49) 1−pp
que se interpreta como sigue. Si es valor toma un valor de 2, significa que es 2 veces mas probable que ocurra p respecto a que no ocurra. Una forma mas cómoda de ver esta razón es tomado su logaritmo (natural), y definimos la función logit:
(50) logit(p)=log1−pp
Los momios y la función Logit son graficados usando Python con el código siguiente
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
deflogit(p):return np.log(p/(1-p))
p = np.arange(0.01,1,0.01)
one = np.ones(p.shape)
plt.figure(figsize=(15,8))
plt.suptitle('Momios')
plt.subplot(121)
plt.plot(p,p/(1-p))
plt.axvline(0.0, color='k')
plt.axvline(1.0,ls='dotted', color='k')
plt.axhline(0.0,color='k')
plt.xlabel('p')
plt.ylabel('razon')#plt.grid(True)
plt.subplot(122)
plt.plot(p,logit(p))
plt.axvline(0.0, color='k')
plt.axvline(1.0,ls='dotted', color='k')
plt.axhline(0.0,color='k')
plt.xlabel('p')
plt.ylabel('logit')#plt.grid(True)
plt.show()
Asi que si p=2/3, tendiamos que 1−p=1/3 los momios son 2.
Si p=.9, tendiamos que 1−p=.1 los momios son 9.
Si p=.95, tendiamos que 1−p=.05 los momios son 19.
Por ello, la gráfica anterior de la izquierda se dispara para valores de p cercanos a 1. Por otro lado logit(p)=logp−log(1−p) es más fácil de entender, es cero para cuando p=1−p=.5, y antisimérica a partir de ese punto.
Verosimilitud de la Regresión Logística
Denotamos por p(yi=1∣xi;ω) la probabilidad condicional de clasificar el dato i a la clase 1 dado el vector de rasgos xi, asumidos los parámetros ω.
Luego, para cualquier clase:
(51) p(yi∣xi;ω)={ϕ(xi⊤ω)1−ϕ(xi⊤ω)yi=1yi=0
o podemos usar
(52) p(yi∣xi;ω)=yiϕ(xi⊤ω)+(1−yi)[1−ϕ(xi⊤ω)]
o, también
(53) p(yi∣xi;ω)=ϕ(xi⊤ω)yi[1−ϕ(xi⊤ω)](1−yi)
Las tres son equivalentes. Sin embargo, usaremos la forma (53) que corresponde a la distribución Bernoulli. Una distribución dicotómica, con solo dos posibles resultados: la probabilidad de éxitos p y fracasos (1−p).
Ahora asumamos la probabibilidad condicional de las clasificación de toda la muestra
Ahora, notamos que la condicional P(Y∣X;ω) es función de Y, asume que ensayamos X para unos parámetros ω. Pero si lo que queremos es aprender es ω a partir de datos de entrenamiento [X,Y], necesitamos definir una función que depende explícitamente de ω y use como datos a [X,Y]. Esta función es, como antes, la verosimilitud:
(55) L(ω;X,Y)=defP(Y∣X;ω)
o simplemente L(ω).
La log-verosimulitud
Para estimar ω debe podemos usar (55) como función de mérito. Es decir, encontrar la ω que maximice la verosimilitud. Pero esta función tiene productos de probabilidades (valores entre cero y uno) y podemos tener el riesgo de sobreflujo en los cálculos. Asi que mejor calculamos la log-verosilitud : l(ω)=logL(ω)
y tenemos:
El gradiente de la función de de costo logística (56) esta dada por (57), que es muy similar en forma al gradiente de la regresión lineal de mínimos cuadrados, ver (18). Por lo computacionalmente no es mucho mas costosa la regresión logística.
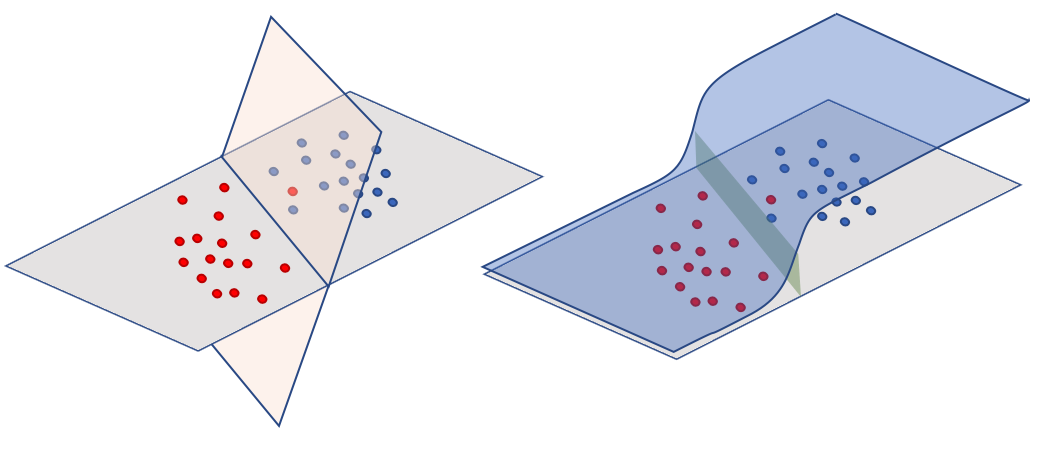
La regresión logistica puede explicarse a partir de la siguiente figura.
Se tienen dos clase (casi) linealmente separables (puntos rojos y azules), con etiquetas binaria yi∈{−1,1}.
El plano ω⊤x es tal que al evaluarse en cualquier punto xi con etiqueta yi=−1 resulta en ω⊤xi<0. Similarmente, para xj con etiqueta yj=−1 resulta en ω⊤xj>0. Es importante notar que existen algunos puntos que no cumplen con la regla que hemos establecido (en la figura hay un punto rojo), el propósito es calcular ω tak que minimize los errores.
Al aplicar la función sigmoide al plano, se tienen que los puntos el mapeo queda en el intervalo [−1,1], y se aproximará a la saturación ({−1,1}) a medida que la pendiente sea máxima: en el límite, es el plano vertical.
Es decir, la optimización de la regresión logística no esta acotada si las clases son perfectamente separables. Ésto se resuelve combiando al azar la etiquerta de un dato (convirtiendolo en outlier).
¿Que pasa si en vez de construir nuestro regresor sobre la restricción yi(ω⊤xi)>0, construimos sobre yi(ω⊤xi)>1?
Respuesta. Ver las Máquinas de Vectores de Soporte [4]
[4] C. Cortes and V. Vapnik. “Support-vector networks”. Machine Learning. 20 (3): 273–297 (1995).