Una matriz es un arreglo rectangular de números (reales o complejos, símbolos o expresiones) con elementos (entradas) arregladas en renglones y columnas. En este curso nos enfocaremos en matrices con entradas reales y las denotaremos con letras mayúsculas (no negritas). Por ejemplo \(A\).
Si \(A\) es un matriz de dimensión \(n\times p\), señalaremos su elemento \(ij\) como \([A]_{ij}\) o \(a_{ij}\) para \(i=1,\ldots, n, j=1,\ldots,p\).
Definición C.1 (Subespacio) Sea \(\mathcal{M}\) un espacio vectorial y sea \(\mathcal{N} \subset \mathcal{M}\). Decimos que \(\mathcal{N}\) es un subespacio de \(\mathcal{M}\) ssi \(\mathcal{N}\) es un espacio vectorial.
Se puede comprobar que \(\mathcal{N}\) es un subepacion de \(\mathcal{M}\) si es un subconjunto no vacío que es cerrado bajo la suma vectorial y multiplicación por escalares.
Sea \(\mathcal{M}\) un espacio vectorial y sea \(\boldsymbol{x}_1, \ldots, \boldsymbol{x}_r\) elementos de \(\mathcal{M}\). El conjunto de combinaciones lineales de \(\boldsymbol{x}_1, \ldots, \boldsymbol{x}_r\): \[
\left\{v \mid v=\alpha_1 x_1+\cdots+\alpha_r x_r, \ \alpha_i \in \mathbb{R}\right\})
\] es un subespacio de \(\mathcal{M}\).
Definición C.2 (Espacio generado) Denominamos como espacio generado por \(\boldsymbol{x}_1, \ldots, \boldsymbol{x}_r\) y lo denotamos como \[
\operatorname{gen}(\boldsymbol{x}_1, \ldots, \boldsymbol{x}_r)=\left\{v \mid v=\alpha_1 x_1+\cdots+\alpha_r x_r, \ \alpha_i \in \mathbb{R}\right\}.
\]
Esto es, los vectores \(\boldsymbol{x}_1, \boldsymbol{x}_2, \ldots, \boldsymbol{x}_r\) de un espacio vectorial \(V\) generan a \(\mathcal{V}\), si cada vector en \(\mathcal{V}\) es una combinación lineal de \(\boldsymbol{x}_1, \boldsymbol{x}_2, \ldots, \boldsymbol{x}_r\).
En particular cuando \(\boldsymbol{x}_1, \boldsymbol{x}_2, \ldots, \boldsymbol{x}_r\) son linealmente independientes, se denominan como base de \(\mathcal{V}\).
Todas las bases de un espacio tienen el mismo número de vectores
La caracterización de cualquier vector es única con respecto a una base.
Si los elementos de la base son ortogonales, la base se denomina ortogonal.
Si además cada elemento de la base tiene norma igual a 1, la base se denomina ortonormal.
Teorema C.1 (Proceso de Gram-Schmidt) Sea \(W\) un subespacio no nulo de \(\mathbb{R}^n\) con base \(S=\)\(\left\{\mathbf{u}_1, \mathbf{u}_2, \ldots, \mathbf{u}_m\right\}\), Entonces, hay una base ortonormal \(T=\left\{\mathbf{w}_1, \mathbf{w}_2, \ldots, \mathbf{w}_m\right\}\) para \(W\).
C.1.1 Rango
Definición C.3 (Rango de subespacio) El rango de un subespacio \(\mathcal{V}\) es el número de elementos de una base de \(\mathcal{V}\).
Definición C.4 (Espacio fila y Espacio Columna) Sea
consideradas como vectores en \(\mathbb{R}^p\), generan un subespacio de \(\mathbb{R}^p\), denominado el espacio fila de \(A\) (denotado como \(\mathcal{R}(A)\). Análogamente, las columnas de \(A\), \(\mathcal{C}(A)\),
consideradas como vectores de \(\mathbb{R}^n\), generan un subespacio de \(\mathbb{R}^n\), denominado el espacio columna de \(A\).
Nota que esto es equivalente a definir a \[
\mathcal{C}(A) =\left\{\boldsymbol{y}\in \mathbb{R}^n : \boldsymbol{y}=A\boldsymbol{x} \ \ \text{ para algun }\ \ \boldsymbol{x}\in \mathbb{R}^p\right\}
\] y \(\mathcal{R}(A)=\mathcal{C}(A^{\top})\).
Definición C.5 (Espacio nulo de una matriz) El espacio nulo de una matriz \(A\), \(n\times p\), denotado como \(\mathcal{N}(A)\), es el conjunto \[
\mathcal{N}(A)=\{\boldsymbol{x}\in \mathbb{R}^p : A\boldsymbol{x}=\boldsymbol{0}\}.
\]
Cualquier miembro de \(\mathcal{N}(A)\) es un vector \(p\times 1\), así que \(\mathcal{N}(A) \subset \mathbb{R}^p\). Además, es fácil verificar que \(\mathcal{N}(A)\) es un subespacio de \(\mathbb{R}^p\).
Observamos que cuando \(\mathcal{N}(A)=\{\boldsymbol{0}\}\) las columna de \(A\) son linealmente independientes. Ahora \(\mathcal{N}(A^{\top})=\{\boldsymbol{0}\}\) ssi los renglones son linealmente independientes.
Definición C.6 (Rangos de una matriz) La dimensión del espacio fila de \(A\) se denomina rango fila de \(A\) y la dimensión del espacio columna de \(A\) se denomina rango columna de \(A\).
Teorema C.2 (Rango de una matriz) El rango fila y el rango columna de la matriz \(A=\left[a_{i j}\right]\) de \(n \times p\) son iguales. A esta la denotamos como rango\((A)\).
En particular nos interesa el espacio columna de una matriz \(A\) que corresponde a \[
A\boldsymbol{x}=x_1\boldsymbol{w}_n+x_2\boldsymbol{w}_n+\cdots+x_p\boldsymbol{w}_p,
\] variando los valores de \(\boldsymbol{x}=(x_1,x_2,\ldots,x_p)^{\top} \in \mathbb{R}^n\).
Proposición C.1 (Rango de una matriz) Si \(A\) es una matriz \(n \times p\),
Se puede mostrar que \(\operatorname{rango}(A)=\operatorname{rango}\left(A^{\top}\right)=\operatorname{rango}\left(A^{\top}A\right)=\operatorname{rango}\left(A A^{\top}\right)\).
C.1.2 Eigenvalores
Proposición C.2 Para matrices conformables, los eigenvalores no nulos de \(AB\) son los mismos que los de \(BA\). Los eigenvalores son idénticos para matrices cuadradas.
ImportanteDemostración
Sea \(\lambda\) uno de los eigenvalores diferentes de cero para \(AB\). Entonces \(\exists\ \boldsymbol{u} \neq \boldsymbol{0}\) tal que \[
\begin{aligned}
&AB\boldsymbol{u}=\lambda\boldsymbol{u}\\
\Leftrightarrow \qquad & BAB\boldsymbol{u}=\lambda B \boldsymbol{u}\\
\Rightarrow \qquad & BA\boldsymbol{v}=\lambda \boldsymbol{v}
\end{aligned}
\] con \(\boldsymbol{v}=B\boldsymbol{u}\neq \boldsymbol{0}\). Entonces \(\lambda\) es eigenvalor de \(BA\).
El argumento hacia la otra dirección se obtiene intercambiando el orden de \(A\) y \(B\).
Para matrices cuadradas se obtiene el resultado a partir de que \(AB\) y \(BA\) tienen el mimo numero de eigenvalores que son 0.
C.2 Matrices cuadradas y algunas definiciones y resultados
Una matriz es cuadrada cuando tiene el mismo número de renglones y de columnas. Para estas matrices podemos realizar las siguiente definiciones.
Teorema C.3 (Sigularidad y rango) Una matriz \(A\) de \(n \times n\) es no singular (o invertible) si existe una matriz \(B\) de \(n \times n\) tal que \[
A B=B A=I_n
\] La matriz \(B\) se denomina inversa de \(A\). Si no existe tal matriz \(B\), entonces \(A\) es singular (o no invertible).
Si \(A\) es matrix de \(n\times p\) y \(P\) y \(Q\) son matrices no singulares de \(n\times n\) y \(p\times p\), respectivamente, entonces \(\operatorname{rango}(PAQ)=\operatorname{rango}(A)\).
C.2.1 Sigularidad y rango
Una matriz A de \(n \times n\) es no singular si y sólo si \(\operatorname{rango}(A)=n\).
Sea \(A\) una matriz de \(n \times n\). El sistema lineal \(A \boldsymbol{x}=\boldsymbol{b}\) tiene una solución única para toda matriz \(\boldsymbol{b}\) de \(n \times 1\) si y sólo si \(\operatorname{rango}(A)=n\).
Si \(A\) y \(B\) son no singulares y de la misma dimensión
\(\left(A^{-1}\right)^{-1}=A\)
\((AB)^{-1}=B^{-1}A^{-1}\)
\((A^{-1})^{\top}=(A^{\top})^{-1}\)
Si \(A=\operatorname{diag}(a_1,\ldots,a_n)\) entonces \(A^{-1}=\operatorname{diag}(1/a_1,\ldots, 1/a_n)\).
Teorema C.4 (Serie de Neumann) Si la serie \(\sum_{k=0}^{\infty} A^k\) converge, entonces \(I_n-A\) es invertible y su inversa es \[
(I_n-A)^{-1}=\sum_{k=0}^{\infty} A^k.
\]
En relación a los eigenvalores, el rango y la dimensión del espacio nulo, podemos anotar lo siguiente:
Si \(\lambda = 0\) es un eigenvalor de una matriz \(A\), entonces existe al menos un eigenvector no nulo \(\boldsymbol{v}\) tal que: \[
A \boldsymbol{v} = 0 \cdot \boldsymbol{v} = \boldsymbol{0}
\]
Esto significa que \(\boldsymbol{v}\) pertenece al espacio nulo de \(A\).
La dimensión del espacio nulo se llama nulidad de \(A\) y el Teorema de la Nulidad-Rango nos indica que \[
\text{rango}(A) + \text{nulidad}(A) = n.
\]
Cada eigenvector linealmente independiente asociado a \(\lambda = 0\) contribuye a la base del espacio nulo. Si hay \(k\) eigenvectores linealmente independientes para \(\lambda = 0\), entonces la nulidad es al menos \(k\). Por lo tanto, el rango de \(A\) será \(n - k\) (o menor, si hay otros vectores en el espacio nulo no capturados como eigenvectores, que ocurre cuando la matriz no es diagonalizable).
La multiplicidad geométrica de \(\lambda = 0\) es el número máximo de eigenvectores linealmente independientes asociados a \(\lambda = 0\): \[
\text{multiplicidad geométrica de } \lambda=0 = \dim(\mathcal{N}(A)) = \text{nulidad}(A).
\]
NotaEjemplo
Consideramos la matriz: \[
A = \begin{pmatrix} 1 & 2 \\ 2 & 4 \end{pmatrix}
\]
cuyos eigenvalores son \(\lambda_1 = 5\) y \(\lambda_2 = 0\).
El eigenvector para \(\lambda=0\) es \(\mathbf{v} = (2, -1)^\top\) (o cualquier múltiplo) y podemos verificar que \(A\mathbf{v} = \begin{pmatrix}1&2\\2&4\end{pmatrix} \begin{pmatrix}2\\-1\end{pmatrix} = \begin{pmatrix}0\\0\end{pmatrix}.\)
El espacio nulo son todos los vectores de la forma \(\alpha(2, -1)^\top\), así que la nulidad es 1.
Por otro lado, el rango de \(A\) es \(2 - 1 = 1\).
Si \(A\) es diagonalizable, la multiplicidad algebraica de \(\lambda=0\) (cuántas veces aparece como raíz del polinomio característico) coincide con su multiplicidad geométrica. Así \[
\text{rango}(A) = n - (\text{número de veces que } \lambda=0 \text{ aparece como raíz})
\]
Estos resultados nos indica que los eigenvectores no nulos asociados al eigenvalor cero son precisamente los generadores del espacio nulo, y la cantidad de ellos linealmente independientes determina cuánto falta para que el rango sea máximo.
C.2.2 Traza
Definición C.7 (Traza de una matriz) La traza de una matriz cuadrada \(A\) (donde \([A]_{ij}=a_{ij}\)) se define como \[
\operatorname{tr}(A)=\sum_i a_{i i}
\]
Y este mapeo tiene las siguiente propiedades:
\(\operatorname{tr}(\gamma A+\mu B)=\gamma \operatorname{tr}(A)+\mu \operatorname{tr}(B)\) para \(\gamma\), \(\mu\) escalares;
\(\operatorname{tr}(A)=\sum_i \lambda_i\) donde \(\lambda_i\) son los eigenvalores de \(A\).
\(\operatorname{tr}(A B)=\operatorname{tr}(B A)\)
La propiedad 4. se relaciona con la siguiente propiedad.
Proposición C.3 (Propiedad cíclica de la traza)\[
\operatorname{tr}(A BC)=\operatorname{tr}(CAB)=\operatorname{tr}(BCA)
\] y en general \[
\operatorname{tr}(A_1A_2\cdots A_n)=\operatorname{tr}(A_nA_1A_2\cdots A_{n-1}).
\]
C.2.3 Determinante
Denotamos el determinante de una matriz cuadrada \(A\) como \(\operatorname{det}(A)=|A|\).
\(|A|=|A^{\top}|\)
Si uno de las columnas (renglones) de \(A\) está llena de ceros, entonces \(|A|=0\)
Si \(A\) tiene al menos un par de columnas (renglones) que son múltiplos, entonces \(|A|=0\)
Si \(B\) es la matriz \(A\) con dos columnas (renglones) intercambiados, entonces \(|A|=-|B|\)
Si \(B\) es la matriz \(A\) en donde se ha substiuido una fila por la suma (o resta) de la misma fila más (o menos) otra fila multiplicada por un número, entonces \(|B|=|A|\)
Si \(B\) es la matriz \(A\) con una de sus columnas (renglones) multiplicadas por un escalar \(c\), entonces \(|B|=c|A|\). Este resultado implica también \(|cA|=c^p|A|\), donde \(p\) es el número de renglones y columnas de \(A\).
Si \(A\) y \(B\) son matrices cuadradas de las mismas dimensiones, entonces \(|AB|=|A||B|\)
Si \(|A|\ne 0\) entonces \(|A^{-1}|=1/|A|\).
El determinante de una matriz triangular es el producto de los elementos de su diagonal principal. En particular, el determinante de una matriz diagonal es igual a la multiplicación de los elementos de su diagonal principal.
\(|A|=\prod_i \lambda_i\) donde \(\lambda_i\) son los eigenvalores de \(A\).
El rango\((A)=n\) ssi \(|A| \neq 0\).
C.3 Matrices Ortogonales
Geométricamente, las matrices ortogonales representan transformaciones isométricas en espacios vectoriales reales llamadas transformaciones ortogonales. Estas transformaciones son isomorfismos internos del espacio vectorial en cuestión, lo que significa que conservan la estructura del espacio vectorial, incluyendo la longitud y el ángulo entre los vectores.
En términos más específicos, una transformación isométrica es aquella que preserva la distancia entre los puntos. Por lo tanto, las matrices ortogonales mantienen las normas de los vectores y las distancias entre ellos, lo que implica que no distorsionan la geometría del espacio. Esto es de gran importancia en muchas áreas de las matemáticas y la física, así como en aplicaciones prácticas.
Estas transformaciones pueden incluir:
Rotaciones: Movimientos que giran los vectores alrededor del origen sin cambiar sus longitudes.
Reflexiones: Transformaciones que “voltean” los vectores a través de un eje o plano.
Inversiones: Transformaciones que invierten la dirección de los vectores manteniendo sus magnitudes.
Estas propiedades hacen que las matrices ortogonales sean muy útiles en computación gráfica, donde se requiere manipular y transformar imágenes y modelos tridimensionales de manera precisa sin alterar sus proporciones.
Además, en áreas como el análisis de datos y la inteligencia artificial, las transformaciones ortogonales se utilizan en técnicas como el Análisis de Componentes Principales (PCA, por sus siglas en inglés) para reducir la dimensionalidad de los datos mientras se preserva la variabilidad original tanto como sea posible.
Definición C.8 (Vectores Ortogonales) Dos vectores \(\boldsymbol{x},\boldsymbol{y} \in \mathbb{R}^n\) son ortogonales (perpendiculares) ssi forman un ángulo recto. Esto equivale a \(\boldsymbol{x}\cdot\boldsymbol{y}=\boldsymbol{x}^{\top}\boldsymbol{y}=\boldsymbol{y}^{\top}\boldsymbol{x}=0\).
Definición C.9 (Vectores Ortonormales) Dos vectores \(\boldsymbol{x},\boldsymbol{y} \in \mathbb{R}^n\) son ortonormales si son ortogonales y \(||\boldsymbol{x}||=||\boldsymbol{y}||=1\)
Como \(||\boldsymbol{x}||^2=\boldsymbol{x}^{\top}\boldsymbol{x}=\boldsymbol{x}\cdot \boldsymbol{x}\), la condición de la definición anterior se puede substituir con \(\boldsymbol{x}\cdot \boldsymbol{x}=\boldsymbol{y}\cdot \boldsymbol{y}=1\).
Definición C.10 (Matriz ortogonal) Una matriz real cuadrada \(A\), \(n\times n\), se dice que es ortogonal si su tranpuesta coincide con la inversa de \(A\). Esto es, \(A^{\top}=A^{-1}\).
La definición anterior equivale a decir que \(A\) es ortogonal ssi \(AA^{\top}=I_n\).
A pesar que el nombre sugiere que la definición de ortogonalidad de una matriz está dada en términos de la ortogonalidad de sus vectores (renglones o columnas) componentes, el nombre no obedece exactamente esta cualidad.
Algunas propiedades de las matrices ortogonales son:
Proposición C.4 (Propiedades de matriz ortogonal)
\(A\) es matriz ortogonal ssi \(A^{\top}\) es matriz ortogonal.
Si \(A\) y \(B\) son matrices ortogonales de la misma dimensión, entonces \(AB\) es también una matriz ortogonal.
El determinante de una matriz ortogonal es \(-1\) o \(1\).
Los eigenvalores de una matriz ortogonal son \(-1\) o \(1\) y sus eigenvectores son ortogonales.
Definición C.11 (Definición alternativa de matriz ortogonal) Una matriz ortogonal \(A\), \(n \times n,\) es una matriz cuyas columnas y renglones son vectores ortonormales.
Debido al nombre no tan preciso de “matriz ortogonal”, alternativamente se utiliza el nombre de “matriz ortonormal”, pero el primero es todavía prevalente.
Se puede checar la equivalencia de las dos definiciones de matriz ortogonal notando que si \(\boldsymbol{v}_i\) es el \(i\)-ésimo vector renglón de \(A\), tenemos \(\boldsymbol{v}_i \perp \boldsymbol{v}_j\) y tienen norma 1 ssi \(\boldsymbol{v}_i \perp \boldsymbol{v}_j=0\), \(i\ne j\) y \(\boldsymbol{v}_k \perp \boldsymbol{v}_k=1\), \(k=i,j\). Esto es, \[
[AA^{\top}]_{ij}=\boldsymbol{v}_i\cdot \boldsymbol{v}_j= \begin{cases}
0 & \text { si } i\ne j \\
1, & \text { si } i=j.
\end{cases}
\] Que equivale a \(AA^{\top}=I_n\).
Como \(B=A^{\top}\) es también ortogonal con \(i\)-ésimo renglón \(\boldsymbol{w}_i\), tenemos el caso para columnas de \(A\).
C.4 Matrices Simétricas
Una matriz real \(A\) se denomina simétrica ssi \(A^{\top}=A\).
Es trivial verificar que bajo ciertas operaciones la propiedad prevalece, como que la suma de matrices simétricas es también simétrica, pero bajo el producto no es necesariamente cierto.
Otros resultados son, considerando \(A\) simétrica:
Proposición C.5 (Propiedades) Si \(A\) es simétrica, tenemos:
Si \(n \in \mathbb{N}\) entonces \(A^{n}\) es simétrica.
Los determinantes de \(A\) y \(A^{\top}\) son iguales
La adjunta de \(A\), \(A^*=\bar{A}^{\top}\), es simétrica
Si \(A\) es invertible, entonces \(A^{-1}\) es simétrica.
Estas matrices tienen varias propiedades, entre las que se destaca:
Proposición C.6 (Eigenvalores de matrices simétricas) Si \(A\), \(n \times n\), es una matriz simétrica, todos sus \(n\) eigenvalores son reales.
Una extensión a esta proposición se presenta en Proposición C.9.
Proposición C.7 Si \(A\) es simétrica entonces \(\operatorname{rango}(A)\) es igual al número de eigenvalores que no son nulos.
La Proposición C.6 no menciona que todos los eigenvalores son diferentes, pero para aquellos con multiplicidad mayor a 1 tenemos el siguiente resultado
Proposición C.8 (Eigenvectores de un mismo eigenvalor en matrices simétricas) Si \(\lambda_1\) y \(\lambda_2\) son dos eigenvalores de \(A\) que son iguales, hay dos vectores propios diferentes que corresponden al mismo valor propio. En este caso, tenemos de las infinitas opciones para vectores propios, siempre podemos elegir que sean ortogonales.
Para el espacio generado por dos eigenvectores (ie los eigenvectores son base de este) se puede obtener una base ortogonal usando el proceso de Gram-Schmidt.
Proposición C.9 (Eigenvalores y eigenvectores para matrices simétricas) Si \(A\) es una matriz simétrica, sus eigenvalores son reales y sus eigenvectores son ortogonales.
ImportanteDemostración
Es sencillo verificar la primera afirmación ya que \(A\boldsymbol{x}=\lambda \boldsymbol{x}\) y si conjugamos tenemos \(\bar{A}\bar{\boldsymbol{x}}=\bar{\lambda}\bar{ \boldsymbol{x}}\). Si \(A\) es real entonces \(A\bar{\boldsymbol{x}}=\bar{\lambda}\bar{ \boldsymbol{x}}\), con lo que se comprueba que los eigenvalors de matrices reales se presentan en pares conjugados. Ahora, si trasponemos, \(\bar{\boldsymbol{x}}^{\top}\bar{A}=\bar{ \boldsymbol{x}}^{\top}\bar{\lambda}\). Ahora multiplicando ambos lado por \(\boldsymbol{x}\) a la derecha, tenemos \[
\bar{\boldsymbol{x}}^{\top}\bar{A}\boldsymbol{x}=\bar{ \boldsymbol{x}}^{\top}\bar{\lambda}\boldsymbol{x}
\] Por otro lado multiplicamos \(A\boldsymbol{x}=\lambda \boldsymbol{x}\) por \(\bar{\boldsymbol{x}}^{\top}\): \[
\bar{\boldsymbol{x}}^{\top}A\boldsymbol{x}=\bar{\boldsymbol{x}}^{\top}\lambda \boldsymbol{x}
\] De las dos expresiones tenemos que \(\bar{ \boldsymbol{x}}^{\top}\bar{\lambda}\boldsymbol{x}=\bar{\boldsymbol{x}}^{\top}\lambda \boldsymbol{x}\). Entonces si \(\bar{\boldsymbol{x}}^{\top}\boldsymbol{x}\ne 0\) podemos concluir que \(\bar{\lambda}={\lambda}\). Ahora es obvio que si \(\boldsymbol{x}\ne 0\) entonces la suma de sus términos cuadrados \(\bar{\boldsymbol{x}}^{\top}\boldsymbol{x}>0\).
Para verificar la ortogonalidad queremos verificar que el \(i\)-ésimo y \(j\)-ésimo eigenvectores, \(\boldsymbol{x}_i\) y \(\boldsymbol{x}_j\), cumplen \(\boldsymbol{x}_i^{\top} \cdot \boldsymbol{x}_j=0\). Por la proposición anterior nos enfocamos en el caso que los eigenvectores sean de diferentes eigenvalores: \(\lambda_i\ne \lambda_j\).
\[
\begin{align}
\boldsymbol{x}_j^{\top}A\boldsymbol{x}_i&=\boldsymbol{x}_j^{\top}\lambda_i\boldsymbol{x}_i=\lambda_i\boldsymbol{x}_j^{\top}\boldsymbol{x}_i\\
&=\boldsymbol{x}_j^{\top}A\boldsymbol{x}_i=\left(\boldsymbol{x}_j^{\top}A\boldsymbol{x}_i\right)^{\top}=\boldsymbol{x}_i^{\top}A\boldsymbol{x}_j=\boldsymbol{x}_i^{\top}\lambda_j\boldsymbol{x}_j=\lambda_j\boldsymbol{x}_i^{\top}\boldsymbol{x}_j.\ \ \because A\ \text{es simétrica}
\end{align}
\] Como \(\boldsymbol{x}_i^{\top}\boldsymbol{x}_j=\boldsymbol{x}_j^{\top}\boldsymbol{x}_i=\boldsymbol{x}_i\cdot\boldsymbol{x}_j\) entonces \((\lambda_i-\lambda_j)(\boldsymbol{x}_i\cdot \boldsymbol{x}_j)=0\) y si \(\lambda_i\ne\lambda_j\), \(\boldsymbol{x}_i\cdot\boldsymbol{x}_j=0\).
Cuando los eigenvalores son distintos, los eigenvelores son únicos con excepción de un factor de escala y signo. Por convención, cada eigenvector se define como el vector asociado a cada eigenvalor, pero con longitud 1 (\(\boldsymbol{x}_i^{\top}\boldsymbol{x}_i=1\)). Estos eigenvectores forman entonces una base ortonormal.
Teorema C.5 (Descomposición Espectral) Si \(A\), \(n\times n\), es una matriz simétrica, entonces existe una matriz ortogonal \(T=(\boldsymbol{t}_1,\boldsymbol{t}_2,\ldots,\boldsymbol{t}_n)\) tal que \(T^{\top}AT=\Lambda\), donde \(\Lambda=\operatorname{diag}(\lambda_1,\lambda_2,\ldots,\lambda_n)\), \(\ \lambda_i\) son los eigenvalores de \(A\) y \(A\boldsymbol{t}_i=\lambda_i \boldsymbol{t}_i\), \(\boldsymbol{t}_i^{\top}\boldsymbol{t}_i=1\) ( \(\{\boldsymbol{t}_1,\ldots,\boldsymbol{t}_n\}\) base ortonormal de \(\mathbb{R}^n\)). La factorización \[
A=T\Lambda T^{\top} =\sum_{i=1}^n \lambda_i \boldsymbol{t}_i\boldsymbol{t}_i^{\top}.
\] se denomina descomposición espectral de \(A\) pero también se conoce con el nombre de “eigen decomposition”
La descomposición espectral es fundamental en la estadística multivariada por su interpretación y la facilidad con la que pueden realizarse cálculos.
Tip
Existe un concepto más general que descompone una matriz cuadrada. Decimos que \(A\) es diagonalizable si existe una matriz invertible \(P\) y una matriz diagonal \(T\) tal que: \[
A = PDP^{-1}.
\]
# Suma de los cuadrados de los elementos de los vectores propiosc1 = np.sum(eA[1][:, 0]**2)c2 = np.sum(eA[1][:, 1]**2)[c1, c2]
#> [np.float64(1.0), np.float64(1.0)]
Código
# Reconstrucción de la matriz originalrec_A = eA[1] @ np.diag(eA[0]) @ eA[1].Trec_A
#> array([[-3., 5.],
#> [ 5., -2.]])
La descomposición espectral tiene las siguientes propiedades
Proposición C.10 (Propiedades)
Si ninguno de los eigenvalores de \(A\) es cero (ie es invertible) entonces \[
A^{-1}=T \Lambda^{-1} T^{-1}.
\]
Si además \(A\) es simétrica, entonces \(T\) es ortogonal y \(T^{-1}=T^{\top}\), entonces \[
A^{-1}=T \Lambda^{-1} T^{\top}.
\] En ambos casos \(\Lambda^{-1}=\operatorname{diag}(1/\lambda_1,1/\lambda_2,\ldots,1/\lambda_n)\).
Si \(m \in \mathbb{N}\) entonces \[
A^{m} = T \Lambda^{m} T^{\top}.
\]
Sea la matriz exponencial \[
\exp(A)=\sum_{j=0}^{\infty}\frac{A^j}{j!}, \ \ \ \text{ entonces }\ \ \
\exp(A)= T \exp(\Lambda) T^{\top}.
\] La segunda expresión es fácil calcular porque \(\exp(\Lambda)\) es una matriz diagonal con elementos \([\exp(\Lambda)]_{ii}=\exp(\lambda_i)\).
Proposición C.11 Una matriz simétrica \(A\), de orden \(n\) y rango \(r\), se puede escribir como \(L L^{\top}\) donde \(L\) es matriz de \(n \times r\) y rango \(r\) (i.e. \(L\) tiene rango completo de columnas).
donde \(L^{\top}=\left[\begin{array}{ll}D_r & 0\end{array}\right] P\) de orden \(r \times n\) y rango completo de renglón.
La proposición anterior se generaliza para matrices no cuadradas. Sea \(A\) matriz \(m\times n\) de rango \(r\), esta se puede expresar como \(A=EF\) con \(E\) matriz \(m\times r\) y \(F\) matriz \(r\times n\), cada una de rango columna y renglón completos, respecitvamente. Este resultado se conoce como Factorización de Rango Completo (Pleno) o Descomposición de Rango.
Proposición C.12 Sea \(c\in \mathbb{R}\), \(A\), \(n\times n\) matriz y si los eigenvalores de \(A\) son \(\{\lambda_i\}\), entonces los eigenvalores de \(I_n+cA\) son \(\{1+c\lambda_i\}\).
ImportanteDemostración
Es fácil verificar de forma directa el resultado anterior, considerando que \(A\boldsymbol{x}=\lambda\boldsymbol{x}\) para \(\lambda\) eigenvalor de \(A\), implica que \((I_n+cA)\boldsymbol{x}=(1+c\lambda)\boldsymbol{x}\).
C.5 Matrices Definidas Positivas y Semidefinidas Positivas.
Definición C.12 (Definiciones) Una matriz cuadrada \(A \in \mathbb{R}^p\) se denomina
definida positiva si \(\boldsymbol{x}^{\top} A \boldsymbol{x}>0\) para todo \(\boldsymbol{x} \in \mathbb{R}^{p}, \boldsymbol{x} \neq \mathbf{0}\);
semidefinida positiva si \(\boldsymbol{x}^{\top} A \boldsymbol{x} \geqslant 0\) for all \(\boldsymbol{x} \in \mathbb{R}^{p}\);
definida negativa si \(\boldsymbol{x}^{\mathrm{T}} A \boldsymbol{x}<0\) para todo \(\boldsymbol{x} \in \mathbb{R}^{p}, \boldsymbol{x} \neq \mathbf{0}\);
semidefinida negative si \(\boldsymbol{x}^{\top} A \boldsymbol{x} \leqslant 0\) para todo \(\boldsymbol{x} \in \mathbb{R}^p\).
Proposición C.13 (Equivalencias) Si \(A\) es simétrica, las siguientes afirmaciones son equivalentes:
\(A\) es positiva definida.
Todos los \(\boldsymbol{p}\) eigenvalores de \(A\) son positivos.
Todos los determinantes de la principales menores de \(A\) (incluyendo \(|A|\)) son positivos.
\(A=B^{\top} B\) para alguna matriz \(B\) de rango completo.
Usando estas equivalencias entonces se pueden demostrar otras propiedades como la siguiente:
Proposición C.14 (Propiedad sobre la propiedad de ser positiva definida) Si \(A\) es simétrica y positiva definida, entonces \(A^{-1}\) también es definida positiva.
ImportanteDemostración
Esta propiedad de demuestra directamente de 4. ya que \(A^{-1}\) es simétrica (Proposición C.5) y \(A^{-1}=(B^{\top} B)^{-1}=B^{-1}(B^{\top})^{-1}=B^{-1}(B^{-1})^{\top}=S^{\top}S\), donde \(S\) tiene rango completo.
C.5.1 Más propiedades
Proposición C.15 Los eigenvalores de una matriz semidefinida positiva (definida positiva) son no negativos (positivos).
Debido a que la traza es la suma de los eigenvalores entonces si \(A\) es semidefinida positiva, \(\operatorname{tr}(A)\geq 0\).
Proposición C.16\(A\) es semidefinida positiva y \(\operatorname{rango}(A)=r\) ssi existe una matriz \(R\), \(n\times n\) de rango \(r\) tal que \(A=RR^{\top}\).
Si \(A\) es definida positiva, entonces \(\operatorname{rango}(CAC^{\top})=\operatorname{rango}(C)\)
Si \(X\) es una matriz \(n\times p\) de \(\operatorname{rango}(X)=p\), entonces \(X^{\top}X\) es definida positiva.
Si \(A\) es definida positiva, entonces todos los elementos de su diagonal son positivos.
Teorema C.6 (Descomposición de Cholesky) Si \(A\) una matriz simétrica es definida positiva ssi tiene una descomposición de Cholesky \(A=R^{\top}R\) donde \(R\) es triangular superior y con elementos en la diagonal estrictamente positivos.
Proposición C.17 (Raiz de matriz definida positiva) Si \(A\) simétrica y definida positiva, existe una matriz \(B\) tal que \(B\) es también definida positiva y \(B^2=A\). Denotamos \(B=A^{1/2}\).
ImportanteDemostración
Por el teorema de descomposición espectral, tenemos que si \(\lambda_1,\ldots,\lambda_n\) son los eigenvalores de \(A\), \[
A=T\Lambda T^{\top}, \ \ \ \text{donde } \ \ \ \Lambda=\operatorname{diag}(\lambda_1,\ldots,\lambda_n).
\] Entonces si \[
A^{1/2}=T\Lambda^{1/2} T^{\top}\ \ \ \text{donde } \ \ \ \Lambda^{1/2}=\operatorname{diag}(\sqrt{\lambda_1},\ldots,\sqrt{\lambda_n}),
\] se verifica, \(A^{1/2}A^{1/2}=T\Lambda^{1/2} T^{\top}T\Lambda^{1/2} T^{\top}=T\Lambda T^{\top}=A\), gracias a que \(T\) es ortogonal.
Verificar que \(A^{1/2}\) es definida positiva se deja como ejercicio.
C.6 Proyecciones
Definición C.13 (Complemento ortogonal) Sea \(\mathcal{V}\) un subespacio de \(\mathbb{R}^n\). Un vector \(\boldsymbol{u}\) en \(\mathbb{R}^n\) es ortogonal a \(\mathcal{V}\) si es ortogonal a cada vector de \(\mathcal{V}\). El conjunto de vectores en \(\mathbb{R}^n\) que son ortogonales a todos los vectores de \(\mathcal{V}\) se llama el complemento ortogonal de \(\mathcal{V}\) en \(\mathbb{R}^n\) y se denota \(\mathcal{V}^{\perp}\) (se lee ” \(\mathcal{V}\) ortogonal”, ” \(\mathcal{V}\) perp”, o “complemento ortogonal de \(\mathcal{V}\)”).
Teorema C.7 (Propiedades Complemento ortogonal) Sea \(\mathcal{V}\) un subespacio de \(\mathbb{R}^n\). Entonces
\(\mathcal{V}^{\perp}\) es un subespacio de \(\mathbb{R}^n\).
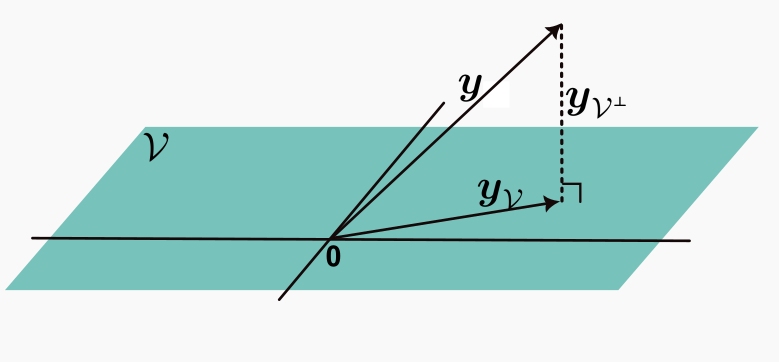
La descomposición ortogonal de un vector consiste en expresarlo como la suma única de dos vectores: uno que pertenece a un subespacio dado \(\mathcal{V}\) y otro que pertenece a su complemento ortogonal \(\mathcal{V}^{\perp }\).
Teorema C.8 (Descomposición ortogonal de un vector) Cada vector \(\boldsymbol{y}\in \mathbb{R}^n\) se puede expresar en forma única de la forma \(\boldsymbol{y}=\boldsymbol{y}_\mathcal{V}+\boldsymbol{y}_{\mathcal{V}^{\perp}}\), where \(\boldsymbol{y_\mathcal{V}} \in \mathcal{V}\) y \(\boldsymbol{y}_{\mathcal{V}^{\perp}} \in \mathcal{V}^{\perp}\). Esta se denomina la descomposición ortogonal de \(\boldsymbol{y}\) con respecto a \(\mathcal{V}\). Este resultado también se denota como \[
\mathbb{R}^n=\mathcal{V}\oplus\mathcal{V}^{\perp}.
\]
Ejemplo Complemento Ortogonal
Tenemos que \(\boldsymbol{y}_\mathcal{V}\) es el vector más cercano a \(\boldsymbol{y}\) en \(\mathcal{V}\).
Ejemplo Descomposicon de un vector con respecto a \(\mathcal{V}\)
Definición C.14 (Idempotencia) Una matriz \(P\) se llama idempotente si \(P^2=P\).
Proposición C.18 (Eigenvalores de matriz idempotente) Todos los eigenvalores de una matriz idempotente \(P\) son ceros o unos.
La demostración se deja como ejercicio.
Corolario C.1 (Rango y eigenvalores de matriz idempotente y simétrica) Sea \(A\) una matriz simétrica, \(n \times n\). \(A\) es idempotente de \(\operatorname{rango}(A)=r\) ssi \(A\) tiene \(r\) eigenvalores iguales a 1 y \(n-r\) eigenvalores iguales a 0.
ImportanteDemostración
\(\Leftarrow )\)
Una matriz \(A\) con \(r\) eigenvalores iguales a 1 y \(n-r\) eigenvalores iguales a cero, tiene \(r\) eigenvalores no nulos y entonces \(\operatorname{rango}(A)=r\). Porque \(A\) es simétrica su descomposición espectral es \(A=T\Lambda T^{\top}\) para una matriz ortogonal \(T\) y matriz diagonal \(\Lambda\). Como los eigenvalores de \(\Lambda\) son los mismos que los de \(A\), estos deben ser todos ceros o unos. Es decir, todos los elementos de la diagonal de \(\Lambda\) son ceros o unos. Entonces \(\Lambda\) es idempotente, \((\Lambda \Lambda=\Lambda)\), y \(A\) es también idempotente, ya que \[
A A={T} {\Lambda} T^{\top} T \Lambda T^{\top}={T} {\Lambda} T^{\top}=A,
\] debido a que \(T\) es una matriz ortogonal, con lo que \(T^{\top}=T^{-1}\).
Definición C.15 (Matriz de Proyección) Supongamos que \(X\) es \(n \times p\) de rango \(p\). Sea \(\mathcal{L}=\mathcal{C}(X)\), el espacio de columnas de \(X\). Decimos que \(P\), \(n \times n\), es la matriz de proyección sobre \(\mathcal{L}\) si se cumplen:
Si \(\boldsymbol{u} \in \mathcal{L} \quad \Rightarrow \quad P \boldsymbol{u}=\boldsymbol{u}\)
Si \(\boldsymbol{v} \in \mathcal{C}^{\perp}(X) \quad \Rightarrow \quad P \boldsymbol{v}=0\)
El punto 1. nos dice que si \(P\) es una proyección sobre un subespacio \(\mathcal{L}\), esta deja inalterados los vectores que ya están sobre \(\mathcal{L}\), por lo que \(P^2\boldsymbol{u}=P(P\boldsymbol{u})=P\boldsymbol{u}\), es decir que \(P\) debe ser idempotente.
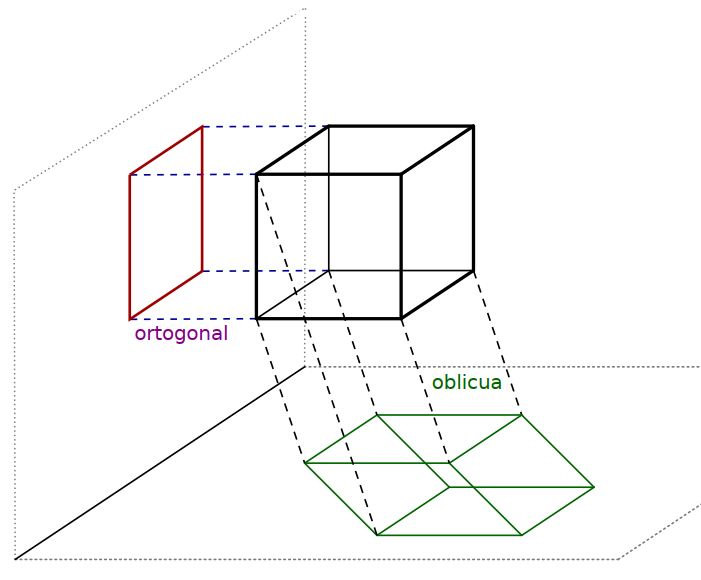
\(P\) es una aplicación lineal que en términos ópticos y geométricos, da la “sombra” de un vector sobre una recta o un plano o sus generalizaciones \(n\)-dimensionales cuando los rayos de luz son ortogonales o perpendiculares a ellos. Hay otras proyecciones que sirven para representar sombras oblicuas pero son matemáticamente menos importantes y no se consideran en este curso.
Tipos de Proyecciones
Definición C.16 (Matriz de proyección) Una matriz \(P_{n \times n}\) se dice que es de proyección si es idempotente.
El complemento de \(P\), \(P^c:=I-P\), es también una proyección ya que
En particular, una proyección es ortogonal si \(P^{\top} P^c=P^{\top}(I-P)=0\). En ese caso, las dos componentes son ortogonales \(\boldsymbol{u}^{\top} P^{\top} \cdot P^c \boldsymbol{u}=\boldsymbol{u}^{\top} P^{\top}(I-P) \boldsymbol{u}=0\) ssi \(P^{\top}=P\).
En ese caso \(P^c\) es la proyección en el complemento ortogonal, por lo que \(\boldsymbol{u} = P\boldsymbol{u} + P^c\boldsymbol{u}\).
Otra propiedad que se tiene es Si \(P\) es proyección ortogonal, \(\|\boldsymbol{u}\|^2=\|P \boldsymbol{u}\|^2+\left\|P^c \boldsymbol{u}\right\|^2\).
C.7 Proyección en el espacio generado por las columnas de una matriz
Proposición C.19 (Proyección en el espacio generado por columna de \(X\)) Sea \(X\) una matriz \(n\times p\) con \(\operatorname{rango}(X)=p\). Consideramos la matriz \[
P=X\left(X^{\top} X\right)^{-1} X^{\top}.
\]\(P\) satisface las condiciones de proyección ortogonal y proyecta sobre el espacio generado por las columnas de \(X\)\(\left(\,\mathcal{C}(X)\,\right)\).
ImportanteDemostración
La matriz \(P\) (de rango \(p\)) es una proyección ya que \[
P^2=X\left(X^{\top} X\right)^{-1} X^{\top} X\left(X^{\top} X\right)^{-1} X^{\top}=X\left(X^{\top} X\right)^{-1} X^{\top}=P.
\] Por otro lado es una proyección ortogonal, porque \(P\) es una matriz simétrica. \[
P^{\top}=\left[X\left(X^{\top} X\right)^{-1} X^{\top}\right]^{\top}=X\left[\left(X^{\top} X\right)^{-1}\right]^{\top} X^{\top}=X\left(X^{\top} X\right)^{-1} X^{\top}=P.
\] Finalmente, es fácil verificar que \(P\) proyecta ortogonalmente sobre el espacio columna de \(X\) ya que si \(\boldsymbol{v}=X \boldsymbol{u}\), entonces \(P\boldsymbol{v}=X\left(X^{\top} X\right)^{-1} X^{\top} X \boldsymbol{u} = X \boldsymbol{u}=\boldsymbol{v}\).
Proposición C.20 (Unicidad de la Proyección ortogonal) Dada una matriz \(X\) de rango \(p\), la proyección ortogonal en \(\mathcal{C}\) es única.
ImportanteDemostración
Supongamos \(\exists H\ne P\) tal que \(H\) es \(n\times n\) y también es matriz de proyección ortogonal en \(\mathcal{C}\). Sea \(\boldsymbol{y}\in \mathbb{R}^n\) un vector. Entonces podemos escribirlo en forma única como \[
\boldsymbol{y}=\boldsymbol{u}+\boldsymbol{v},\qquad \boldsymbol{u}\in \mathcal{C},\ \boldsymbol{v}\in \mathcal{C}^{\perp}.
\] Entonces \[
H\boldsymbol{y}=H(\boldsymbol{u}+\boldsymbol{v})=H\boldsymbol{u}=\boldsymbol{u}.
\] Similarmente tenemos \(P\boldsymbol{y}=\boldsymbol{u}\), por lo que \(H\boldsymbol{y}=P\boldsymbol{y}\)\(\ \ \forall \boldsymbol{y}\in \mathbb{R}^n\). Por lo tanto \(P=H\).
Proposición C.21 (Relación entre Rango y Traza de una matriz de proyección) Para cualquier matriz idempotente \(A\), \(\operatorname{tr}(A)=\operatorname{rango}(A)\).
ImportanteDemostración
Como el rango de una matriz idempotente \(P\) sólo puede tener eigenvalores 0’s y 1’s (Ejercicio de Tarea), entonces sabemos que es semidefinida positiva. Gracias a estos sabemos existe \(R\), \(n\times n\) de rango \(r\) tal que \[
P=RR^{\top}.
\] Ver Proposición C.16 . Entonces \[
P^2=RR^{\top}RR^{\top}\ \text{y }\ P^2=P=RR^{\top}\quad \Rightarrow \quad R^{\top}RR^{\top}=R^{\top}\ \Rightarrow \ R^{\top}R=I_r
\] Considerando ahora la traza, tenemos \[
\operatorname{tr}(P)=\operatorname{tr}(RR^{\top})=\operatorname{tr}(R^{\top}R)=\operatorname{tr}(I_r)=r=\operatorname{rango}(P)
\]
El rango de una matriz \(A\) simétrica e idempotente, es la dimension de \(\mathcal{C}(A)\) que es el espacio en el que \(A\) proyecta.
Proposición C.22 (Suma de proyecciones ortogonales) Sean \(P_1\) y \(P_2\) dos matrices de proyecciones ortogonales en \(\mathbb{R}^n\). \(\left(P_1+P_2\right)\) es una matriz de proyección ortogonal en \(\mathcal{C}\left(P_1, P_2\right)\) ssi \(\mathcal{C}\left(P_1\right) \perp \mathcal{C}\left(P_2\right)\).
ImportanteDemostración
\(\Leftarrow )\)
Si \(\mathcal{C}\left(P_1\right) \perp \mathcal{C}\left(P_2\right)\), entonces \(P_1 P_2 = P_2 P_1 = 0\).
Ahora, como \[
\left(P_1+P_2\right)^2=P_1^2+P_2^2+P_1 P_2+P_2 P_1=P_1^2+P_2^2=P_1+P_2
\] y
\[
\left(P_1+P_2\right)^{\top}=P_1^{\top}+P_2^{\top}=P_1+P_2
\] entonces \(P_1+P_2\) es una proyección ortogonal en \(\mathcal{C}\left(P_1+P_2\right)\).
Tenemos que \(\mathcal{C}\left(P_1+P_2\right) \subset \mathcal{C}\left(P_1, P_2\right)\). Para ver que \(\mathcal{C}\left(P_1, P_2\right) \subset \mathcal{C}\left(P_1+P_2\right)\), consideramos \(v = P_1 b_1 + P_2 b_2\). Como \(P_1 P_2 = P_2 P_1 = 0\), entonces \(\left(P_1 + P_2\right) v=v\). Así, \(\mathcal{C}\left(P_1, P_2\right)=\mathcal{C}\left(P_1 + P_2\right)\).
\(\Rightarrow )\)
Si \(P_1 + P_2\) es una proyección ortogonal, entonces es idempotente. Esto es, \[
\begin{aligned}
\left(P_1+P_2\right) & =\left(P_1+P_2\right)^2=P_1^2+P_2^2+P_1 P_2+P_2 P_1 \\
& =P_1+P_2+P_1 P_2+P_2 P_1.
\end{aligned}
\] Entonces, \(P_1 P_2 + P_2 P_1 = 0\). Si multiplicamos esta expresión por \(P_1\) tenemos \[
0=P_1^2 P_2+P_1 P_2 P_1=P_1 P_2+P_1 P_2 P_1
\] Entonces \(-P_1 P_2 P_1=P_1 P_2\). Ahora, como \(-P_1 P_2 P_1\) es simétrica, también lo es \(P_1 P_2\). Así,\(P_1 P_2=\left(P_1 P_2\right)^{\top}=P_2 P_1\). Como \(P_1 P_2 + P_2 P_1=0\) entonces \(2\left(P_1 P_2\right)=0\) lo que implica que \(P_1 P_2=0\).
Proposición C.23 (Descomposición en proyecciones ortogonales) Si \(P_1\) y \(P_2\) son simétricas, \(\mathcal{C}\left(P_1\right) \perp \mathcal{C}\left(P_2\right)\), y \(\left(P_1+P_2\right)\) es una matriz de proyección ortogonal, entonces \(P_1\) y \(P_2\) son matrices de proyección ortogonales.
ImportanteDemostración
Por idempotencia \[
\left(P_1+P_2\right)=\left(P_1+P_2\right)^2=P_1^2+P_2^2+P_1 P_2+P_2 P_1
\]
Como \(P_1\) y \(P_2\) cumplen \(\mathcal{C}\left(P_1\right) \perp \mathcal{C}\left(P_2\right)\), tenemos \(P_1 P_2+P_2 P_1=0\) y \(P_1+P_2=P_1^2+P_2^2\).
Entonces \(P_2-P_2^2=P_1^2-P_1\), así que \(\mathcal{C}\left(P_2-P_2^2\right)=\mathcal{C}\left(P_1^2-P_1\right)\). Ahora, \(\mathcal{C}\left(P_2-P_2^2\right) \subset \mathcal{C}\left(P_2\right)\) y \(\mathcal{C}\left(P_1^2-P_1\right) \subset \mathcal{C}\left(P_1\right)\). Entonces \(\mathcal{C}\left(P_2-P_2^2\right) \perp \mathcal{C}\left(P_1^2-P_1\right)\). Un vector solo puede ser ortogonal a sí mismo si es el vector cero. Entonces, \(P_2-P_2^2=P_1^2-P_1=0\), \(P_2=P_2^2\) y \(P_1=P_1^2\).
Proposición C.24 (Diferencia de matrices de proyección ortogonal) Sean \(P\) y \(P_0\) matrices de proyección ortogonales con \(\mathcal{C}\left(P_0\right) \subset \mathcal{C}(P)\). Entonces \(P - P_0\) es una matriz de proyección ortogonal.
ImportanteDemostración
Como \(\mathcal{C}\left(P_0\right) \subset \mathcal{C}(P)\), entonces \(P P_0 = P_0\) y por simetría, \(P_0 P = P_0\). Entonces
\(\left(P-P_0\right)^2 = P^2 - P P_0 - P_0 P+ P_0^2 = P-P_0 - P_0 + P_0 = P - P_0\), (ie, \(P-P_0\) es idempotente), y
Sea \(P\) y \(P_0\) matrices de proyección ortogonales con \(\mathcal{C}\left(P_0\right) \subset \mathcal{C}(P)\). Entonces \(\mathcal{C}\left(P - P_0\right)\) es el complemento ortogonal de \(\mathcal{C}\left(P_0\right)\) con respecto a \(\mathcal{C}(P)\). Esto es, \(\mathcal{C}\left(P - P_0\right)=\mathcal{C}\left(P_0\right)_{\mathcal{C}(P)}^{\perp}\).
Por otro lado, si \(x \in \mathcal{C}(P)\) y \(x \perp C\left(P_0\right)\), entonces \(x = P x = \left(P-P_0\right) x+P_0 x = \left(P-P_0\right) x\). Entonces, \(x \in \mathcal{C}\left(P-P_0\right)\), entonces el complemento ortogonal de \(\mathcal{C}\left(P_0\right)\) con respecto a \(\mathcal{C}(P)\) está contenido en \(\mathcal{C}\left(P-P_0\right)\).
Proposición C.25 (Descomposición de rangos) Sea \(P\) y \(P_0\) matrices de proyección ortogonales con \(\mathcal{C}\left(P_0\right) \subset \mathcal{C}(P)\), entonces \[
\operatorname{rango}(P)=\operatorname{rango}\left(P_0\right)+\operatorname{rango}\left(P-P_0\right).
\]
C.8 Descomposición Espectral (SDV)
SVD
La descomposición espectral es uno de los teoremas de descomposición que se utlizan ampliamente en estadística y algoritmos computacionales. La siguiente descomposición generaliza la espectral ya que en este caso no solo \(A\) puede no ser simétrica, sino que no es necesario que sea cuadrada.
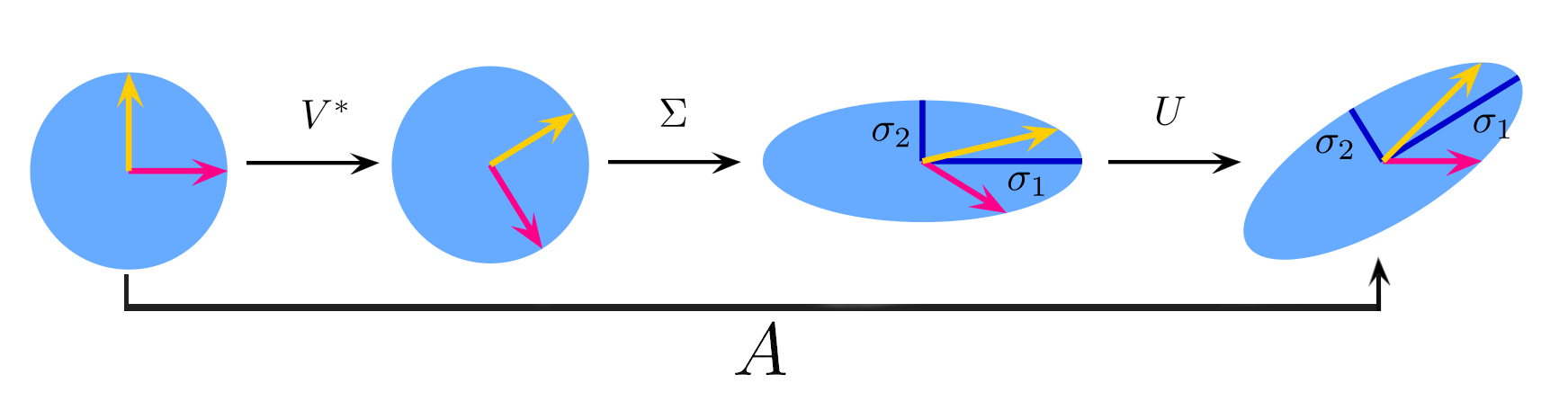
Teorema C.9 (Descomposición en Valores Singulares (SVD)) Sea \(A\) una matriz \(m \times n\) rectangular de rango \(r \leq \text{mín}\{m,n\}\). Entonces, \[
\underset{m \times n}{A}=\underset{m\times m}{U}\ \ \underset{m \times n}{\Sigma}\ \ \underset{n\times n}{V^{\top} }
\]
donde \(U^{\top} U = I_m, \ \ \ V^{\top} V = I_n\ \), y \(\ \ \Sigma=\operatorname{diag}\left(\sigma_1, \cdots, \sigma_r\right),\ \ \sigma_i>0\).
Las columnas de \(U\) y \(V\), \(\boldsymbol{u}_1,\ldots, \boldsymbol{u}_m, \ \boldsymbol{v}_1,\ldots, \boldsymbol{v}_n\) se denominan vectores singulares izquierdos y derechos, respectivamente. Los valores \(\sigma_i\) se denominan valores singulares.
Ya que \(U^{\top} U = I_m\), tenemos que \(U\) es una matriz con columnas ortogonal. Por otro lado, sus columnas son los vectores singulares izquierdos de \(A\). Estos son los eigenvectores de \(AA^{\top}\).
Similar a \(U\), \(V\) es una matriz con columnas ortogonales. Sus columnas son los vectores singulares derechos de \(A\) y corresponden a los eigenvectores de \(A^{\top}A\). Los vectores singulares derechos representan las direcciones principales en el espacio de las columnas de \(A\).
\(\Sigma\) es una matriz con los valores singulares de \(A\) en la diagonal ordenados de mayor a menor. Estos son valores no negativos que corresponden a la raiz positiva de los eigenvalores de \(A^{\top}A\) y \(AA^{\top}\).
Como el \(AA^{\top}\) y \(A^{\top}A\) son simétricas, y positivas definidas, todos sus eigenvalores son reales y no negativos. Además sus eigenvalores son los cuadrados de los eigenvalores de \(A\).