Apéndice B — Normal multivariada
B.1 Definición
La distribución Normal multivariada es una extensión de la distribución Normal o Gaussiana.
Definición B.1 (A través de la función de densidad) Decimos que un vector aleatorior \(\boldsymbol{Y}^{\top}=\left(Y_1, Y_2, \cdots, Y_p\right)\) tiene distribución Normal multivariada \(\left(N_p(\boldsymbol{\mu}, \Sigma)\right)\) si y solo si su función de densidad de probabilidad tiene la siguiente expresión \[ \begin{aligned} f_\boldsymbol{Y}\left(y_1, y_2, \cdots, y_p\right) &= \phi(\boldsymbol{y} ; \boldsymbol{\mu}, \Sigma)\\ & = \frac{1}{(2 \pi)^{p / 2}|\Sigma|^{1 / 2}} \exp \left\{-\frac{1}{2}(\boldsymbol{y}-\boldsymbol{\mu})^{\top} \Sigma^{-1}(\boldsymbol{y}-\boldsymbol{\mu})\right\}, \end{aligned} \] donde \(\boldsymbol{y}\in \mathbb{R}^p\), \(\Sigma=\left(\sigma_{i j}\right)_{p \times p}\) es la matriz real simétrica de varianzas y covarianza de \(\boldsymbol{Y}\) que además es positiva definida (por lo que su inversa \(\Sigma^{-1}\) existe) y el vector \(\boldsymbol{\mu}^{\top}=\left(\mu_1, \mu_2, \cdots, \mu_p\right) \in \mathbb{R}^p\) es la media de \(\boldsymbol{Y}\).
Recordamos que una matriz simétrica \(A\) de dimensión \(p\times p\) se denomina positiva definida ssi \[ \boldsymbol{x}^{\top}A\boldsymbol{x}>0 \quad \forall \ \boldsymbol{x}\in \mathbb{R}^p \quad \text{tq}\quad \boldsymbol{x}\ne \boldsymbol{0}. \]
En general \(\Sigma\) es positiva semidefinida, permitiendo que la distribución tenga “varianza cero”.
A la matriz \(\Sigma^{-1}\) se le denomina matriz de concentración o matriz de precisión.
Definición B.2 (Normal Estándar) En analogía al caso univariado, a la distribución \(N(\boldsymbol{0}, \text{diag}(1,\ldots, 1))\) se le denomina distribución Normal multivariada estándar.
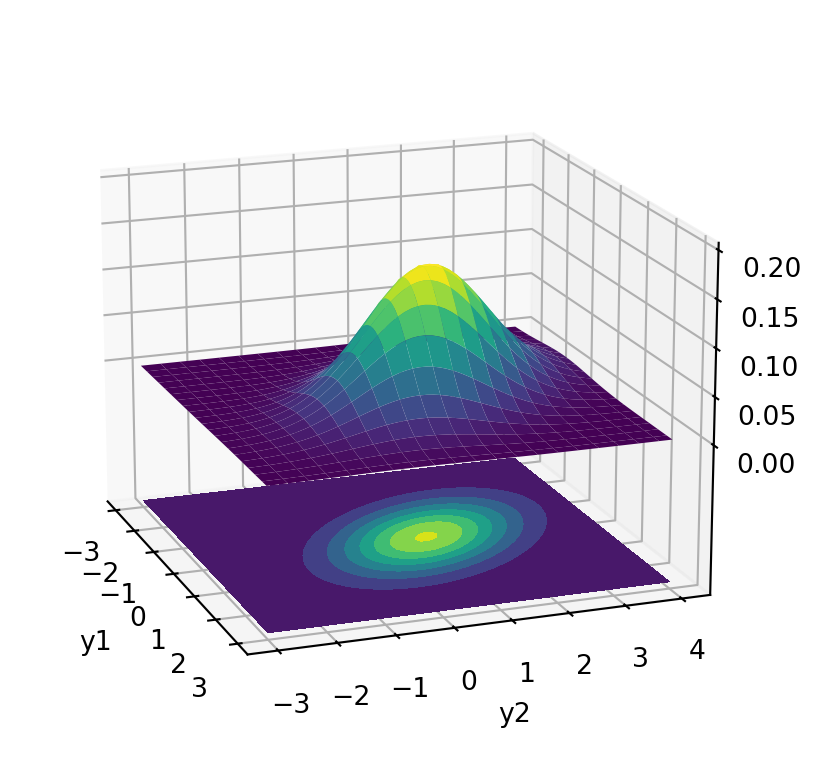
NotaEjemplo: Normal Bivariada
La siguiente figura representa la función de densidad de un v.a. con distribución \[ N\left((0, 1)^{\top}, \left(\begin{array}{cc} 1 & -0.5\\ -0.5& 1.5 \end{array}\right)\right) \]
Hemos definido la distribucion normal multivariada especificando su función de densidad conjunta, pero además de considerar alguna otra función que la caracteriza (como la FD, generadora, etc) también se puede especificar con la siguiente definición:
Definición B.3 (Definición alternativa) El vector aleatorio \(\boldsymbol{Y}\) que es \(p\) dimensional, tiene distribución Normal multivariada si existe un vector \(\boldsymbol{\mu} \in \mathbb{R}^p\) y una matriz \(\Sigma\) de dimensión \(p \times p\) tal que \[ \boldsymbol{\gamma}^{\top}\boldsymbol{Y}\sim N(\boldsymbol{\gamma}^{\top}\mu,\ \boldsymbol{\gamma}^{\top}\Sigma \boldsymbol{\gamma}) \quad \ \forall \boldsymbol{\gamma}\in \mathbb{R}^p. \]
A partir de esta definición, si tomamos como \(\boldsymbol{\gamma}=\boldsymbol{e_i}\) que es el vector de base canónica, esto es con un 1 en el \(i\)-ésimo elemento y 0 en las otras posiciones, tenemos que \[ Y_i\sim N(\mu_i, \sigma_{ii}). \] Es decir, las marginales de \(\boldsymbol{Y}\) tiene distribución Normal univariada, pero esto no implica que cualesquiera distribuciones Normales univariadas tienen una distribución conjunta que es Normal multivariada.
B.2 Funciones Generadora de Momentos y algunas propiedades
Por otro lado, la función generadora de momentos multivariada de \(\boldsymbol{Y}\) se define como \(m_Y(\boldsymbol{s})=\mathbb{E}\left[\exp\{\boldsymbol{s}^{\top}\boldsymbol{Y}\}\right]\) y se comprueba que para el caso Normal multivariado tenemos: \[ m_Y(\boldsymbol{s})= \exp\left\{\boldsymbol{s}^{\top}\boldsymbol{\mu}+\frac{\boldsymbol{s}^{\top}\Sigma\boldsymbol{s}}{2}\right\}. \]
Teorema B.1 (Independencia) Si \(p \in \mathbb{N}\), \(\boldsymbol{Y}^{\top}=\left(Y_1, Y_2, \cdots, Y_p\right) \sim N(\boldsymbol{\mu}, \Sigma)\) y \(\Sigma=\operatorname{diag}\left(\sigma_{1}^2, \sigma_{2}^2, \cdots, \sigma_{p}^2\right)\), entonces \(Y_1, Y_2, \cdots, Y_p\) son independientes.
Este teorema se puede comprobar considerando la forma específica de \(\Sigma=\operatorname{diag}\left(\sigma_{1}^2, \sigma_{2}^2, \cdots, \sigma_{p}^2\right)\) en la función de distribución conjunta y comprobando que ésta corresponde al producto de sus marginales (cada una con distribución Gaussiana como hemos apuntado arriba): \[ f\left(y_1, y_2, \cdots, y_p\right) = \prod_{i=1}^p \frac{1}{\sqrt{2 \pi} \sigma_i^2} \exp \left\{-\frac{\left(y_i-\mu_i\right)^2}{2\sigma_i^2}\right\}. \] Entonces tenemos que si los componentes de una distribución Normal multivariada son no correlacionados, entonces también son independientes. Es importante notar que esta propiedad no solo no se cumple para cualquier otra distribución multivariada sino que incluso no significa que si cualesquiera dos distribuciones gausianas son correlacionadas estas son independientes. Esto se puede comprobar con el siguiente ejemplo.
Proposición B.1 (Transformaciones lineales) La distribución Normal Multivariada se preserva bajo transformaciones lineales.
Sea \(A\) una matriz de dimensión \(m\times p\), \(\operatorname{rango}(A)=m\), y \(\boldsymbol{b}\in \mathbb{R}^m\). Si \(\boldsymbol{Y}\sim N_p(\boldsymbol{\mu},\Sigma)\) entonces
\[ A\boldsymbol{Y}+\boldsymbol{b} \sim N_m\left(A\boldsymbol{\mu}+\boldsymbol{b}, \ A\Sigma A^{\top}\right) \]
Proposición B.2 (Independencia de transformaciones lineales) Las transformaciones lineales \(A \mathbf{X}\) y \(B \mathbf{X}\) donde \(\mathbf{X} \sim N(\mu, \Sigma)\), son independientes ssi \[ A \Sigma B^T=0. \]
B.3 Particiones y Condicionales
Podemos particionar \(\boldsymbol{Y}\) en \(\boldsymbol{Y}_1\) y \(\boldsymbol{Y}_2\) donde \(\boldsymbol{Y}_1 \in \mathbb{R}^r\) y \(\boldsymbol{Y}_2 \in \mathbb{R}^s\) con \(r+s=p\): \[ \boldsymbol{Y}=\left[\begin{array}{c} \boldsymbol{Y}_1 \\ \boldsymbol{Y}_2 \end{array}\right]. \]
Las correspondientes medias y varianzas-covarianzas particionadas son: \[ \boldsymbol{\mu}=\binom{\boldsymbol{\mu}_1}{\boldsymbol{\mu}_2}, \quad \Sigma=\left(\begin{array}{ll} \Sigma_{11} & \Sigma_{12} \\ \Sigma_{21} & \Sigma_{22} \end{array}\right) \] donde \(\Sigma_{11}\) es \(r \times r\) y así sucesivamente. Entonces si \(\boldsymbol{Y} \sim \mathcal{N}_q(\mu, \Sigma)\) \[ \boldsymbol{Y}_2 \sim N_s\left(\boldsymbol{\mu}_2, \Sigma_{22}\right) \] Esto se comprueba simplemente considerando la transformación \(A\boldsymbol{Y}\) con \(A=(0_{s\times r}, I_s)\). En donde \(0_{s\times r}\) es la matriz de ceros de dimensión \(s\times r\) e \(I_s\) es la matriz identidad (\(s\times s\)).
Análogamente, \(\boldsymbol{Y}_1 \sim N_r\left(\boldsymbol{\mu}_1, \Sigma_{11}\right)\).
La matriz \(\Sigma_{12}\) es la covarianza cruzada entre elementos de \(\boldsymbol{Y}_1\) y \(\boldsymbol{Y}_2\), así que \(\Sigma_{12}=\Sigma_{21}^{\top}\).
Proposición B.3 (Independencia) \(\boldsymbol{Y}_1\) y \(\boldsymbol{Y}_2\) son independientes ssi \(\Sigma_{12}=\boldsymbol{0}\)
Proposición B.4 (Condicional) Si condicionamos \(\boldsymbol{Y}_1\) dado el evento \(\boldsymbol{Y}_2=\boldsymbol{y}_2\) tenemos: \[ \boldsymbol{Y}_1 \mid \boldsymbol{Y}_2=\boldsymbol{y}_2 \ \sim \ N_r\left(\boldsymbol{\mu}_{1 \mid 2}, \Sigma_{1 \mid 2}\right) \] donde \[ \boldsymbol{\mu}_{1 \mid 2} = \boldsymbol{\mu}_1+\Sigma_{12} \Sigma_{22}^{-1}\left(\boldsymbol{y}_2-\boldsymbol{\mu}_{2}\right) \quad \text { y } \quad \Sigma_{1 \mid 2}=\Sigma_{11}-\Sigma_{12} \Sigma_{22}^{-1} \Sigma_{21} \]
En particular, si \(\Sigma_{12}=0\) vemos que la distribución condicionada corresponde a la marginal de \(\boldsymbol{Y}_1\) (resultado también de que en este caso \(\boldsymbol{Y}_{1}\) y \(\boldsymbol{Y}_{2}\) son independientes).
La demostración del resultado anterior se basa en el siguiente resultado
Proposición B.5 (Inversa de una matriz particionada) Sea \[ A = \left[ \begin{array}{cc} A_{11} & A_{12} \\ A_{21} & A_{22} \end{array} \right], \] entonces \[ A^{-1}= \left[ \begin{array}{cc} S_{1|2}^{-1} & -S_{1|2}^{-1}A_{12}A_{22}^{-1} \\ -A_{22}^{-1}A_{21}S_{1|2}^{-1} & A_{22}^{-1}+A_{22}^{-1}A_{21}S_{1|2}^{-1}A_{12}A_{22}^{-1} \end{array} \right] \] donde \[ S_{1|2} = A_{11} - A_{12}A_{22}^{-1}A_{21}. \]
Proposición B.6 (Fórmula de Woodbury) Si \(A\), \(U\), \(C\) y \(V\) son conformables (\(A\) es \(n \times n, C\) es \(k \times k, U\) es \(n \times k\), y \(V\) es \(k \times n\)), entonces, \[ (A+UCV)^{-1}=A^{-1}-A^{-1}U(C^{-1}+VA^{-1}U)^{-1}VA^{-1}. \]
Una forma particular es cuando \(C=-1\), \(U=u\) un vector y \(V=u^T\): \[ (A-uu^T)^{-1}=A^{-1}+A^{-1}u(1-u^TA^{-1}u)^{-1}u^TA^{-1} \]
De la fórmula de Woodbury y la expresión anterior, también podemos derivar la siguiente. Esta es particularmente importante porque nos permitirá indagar en forma eficiente el efecto de cada observación en las estimaciones: \[ (X^{\top}X-\boldsymbol{x}_1\boldsymbol{x}_1^{\top})^{-1}= (X^{\top}X)^{-1}+(X^{\top}X)^{-1}\boldsymbol{x}_1(1-\boldsymbol{x}_1^{\top}(X^{\top}X)^{-1}\boldsymbol{x}_1)^{-1}\boldsymbol{x}_1^{\top}(X^{\top}X)^{-1}. \tag{B.1}\] donde \(\boldsymbol{x}_1\) es el primer renglón de \(X\).