La prueba Anderson-Darling de bondad de ajuste es una de las pruebas basadas en la función de distribución empírica; cuantifica la discrepancia entre las distribuciones teórica y empírica. Una forma general ded medir esa discrpancia es mediante:
\[
A^2=n \int_{-\infty}^{\infty}\left[F_n(x)-F(x)\right]^2 \psi(x) f(x) d x
\] donde \(F_n(x)\) es la función de distribución empírica, \(F(x)\) es la función de distribución teórica o hipotetizada, \(\psi(x)\) es una función ponderadora y \(f(x)\) es la densidad teórica. El caso especial de la AndersonDarling ocurre cuando se toma la función ponderadora como: \[
\psi(x)=\frac{1}{F(x)[1-F(x)]}
\]
\(\psi(x)\) tiene como objetivo darle una mayor importancia a discrepancias en las colas de la distribución, permitiéndole al estadístico \(A^2\) una mayor capacidad para detectar otras distribuciones. La razón por la cual se le dá importancia a las colas es que la diferencia \(F_n(x)-F(x)\) tiende a cero en las colas, aún cuando la función \(F(x)\) no sea la distribución verdadera.
Proposición F.1 (Expresión alternativa de \(A^2\)) Sea \(y_1, \cdots, y_n\) una muestra aleatoria proveniente de cierta distribución. Si queremos probar la hipótesis \(H_0: y \sim F\), el estadístico \(A^2\) toma la forma \[
A^2=-n-\frac{1}{n} \sum_{i=1}^n(2 i-1)\left[\log \left(z_i\right)-\log \left(1-z_{n-i+1}\right)\right]
\] donde \(z_i=F\left(y_i ; \theta\right)\).
ImportanteDemostración
Supongamos \(x_1 \leq x_2 \leq \cdots \leq x_n\). Entonces \[
\begin{aligned}
\frac{1}{n} A^2 & =\int_{-\infty}^{\infty}\left[F_n(x)-F(x)\right]^2 \psi(x) f(x) d x \\
& =\int_{-\infty}^{x_1} \frac{F(x)}{1-F(x)} f(x) d x+\sum_{j=1}^{n-1} \int_{x_j}^{x_{j+1}} \frac{\left[\frac{j}{n}-F(x)\right]^2}{F(x)[1-F(x)]} f(x) d x+\int_{x_n}^{\infty} \frac{1-F(x)}{F(x)} f(x) d x \\
& =\int_0^{z_1} \frac{u}{1-u} d u+\sum_{j=1}^{n-1} \int_{z_j}^{z_{j+1}} \frac{\left(\frac{j}{n}-u\right)^2}{u(1-u)} d u+\int_{z_n}^1 \frac{1-u}{u} d u \equiv a+\sum_j b_j+c.
\end{aligned}
\]
Aquí hicimos el cambio de variable \(u=F(x)\) con \(d u=f(x) f x\) y tenemos que \[
\begin{aligned}
a & :=\int_0^{u_1}\left(-1-\frac{1}{1-u}\right) d u=-u-\left.\log (1-u)\right|_0 ^{u_1}=-u_1-\log \left(1-u_1\right) \\
c & :=\int_{u_n}^1\left(\frac{1}{u}-1\right) d u=\log (u)-\left.u\right|_{u_n} ^1=-1-\log u_n+u_n\\
a_j&:= j / n\\
b_j &:= \int_{u_j}^{u_{j+1}} \frac{\left(a_j-u\right)^2}{u(1-u)} d u=\int_{u_j}^{u_{j+1}} \frac{\left(\left[a_j-1\right]+[1-u]\right)^2}{u(1-u)} d u \\
&= \left(1-a_j\right)^2 \int_{u_j}^{u_{j+1}} \frac{1}{u(1-u)} d u-2\left(1-a_j\right) \int_{u_j}^{u_{j+1}} \frac{1}{u} d u+\int_{u_j}^{u_{j+1}} \frac{1-u}{u} d u \\
&= \left(1-a_j\right)^2\left[\log u_{j+1}-\log \left(1-u_{j+1}\right)-\log u_j+\log \left(1-u_j\right)\right] \\[5pt]
&\quad -2\left(1-a_j\right)\left[\log u_{j+1}-\log u_j\right] +\log u_{j+1}-u_{j+1}-\log u_j+u_j.
\end{aligned}
\]
Por otro lado, \(a_j^2-a_{j-1}^2=(2 j-1) / n^2\) y \(\left(1-a_{j-1}\right)^2-\left(1-a_j\right)^2=[2(n-j)+1] / n^2\), entonces \[
\frac{1}{n} A^2=-1-\frac{1}{n^2} \sum_{j=1}^n[2(n-j)+1] \log \left(1-u_j\right)-\frac{1}{n^2} \sum_{j=1}^n[2 j-1] \log u_j.
\]
Cambiando el orden de los subíndices de la primera suma, tenemos que \[
\frac{1}{n} A^2=-1-\frac{1}{n^2} \sum_{j=1}^n[2 j-1] \log \left(1-u_{n-j+1}\right)-\frac{1}{n^2} \sum_{j=1}^n[2 j-1] \log u_j
\]
y de aquí se obtiene la forma computacional del estadístico Anderson-Darling.
Si \(y_1, \cdots, y_n\) es una muestra aleatoria proveniente de cierta distribución y si queremos probar la hipótesis \(H_0: y \sim F\), entonces rechazamos \(H_0\) para valores grandes de \(A^2\).
Ahora, para el cálculo de \(A^2\) tenemos que evaluar \(u_j=F\left(x_j ; \mu, \sigma^2\right)\), pero, ¿cuáles parámetros debemos usar en \(F\)?
Para el caso de la distribución normal, es natural usar \(\bar{x}\) y \(s^2\), sin embargo, el hacer esto hace que el problema de determinar la distribución de \(A^2\) sea extremadamente difícil. Una opción es usar simulación.
Esta opción es factible por una propiedad interesante: Para familias de localización y escala (como la normal), la distribución de \(A^2\) depende de \(F\) pero no de los parámetros de \(F\); así que podemos simular de una normal específica, digamos \(N(0,1)\), luego calculamos \(u_i=F\left(x_i ; \bar{x}, s^2\right)\) y la distribución resultante de \(A^2\) será válida cuando la distribución verdadera sea cualquier \(N\left(\mu, \sigma^2\right)\).
A continuación presentamos el ejercicio de simulación para determinar la distribución de \(A^2\)
NotaEjercicio de simulación para determinar la distribución de A2
Código
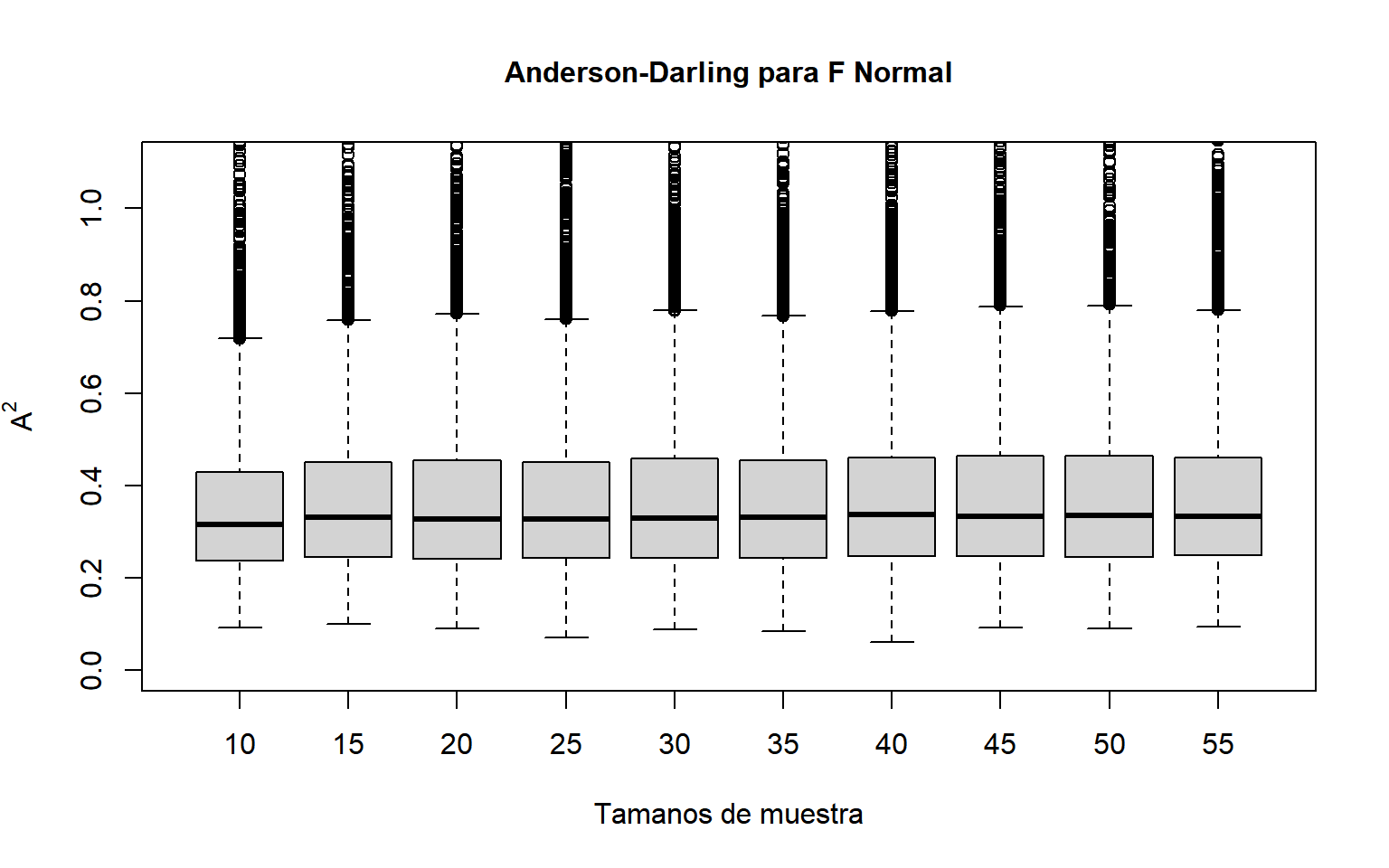
# Comportamiento del Anderson-Darling estimando parametrosAD<-function(x){x<-sort(x)n<-length(x)m<-mean(x)s<-sqrt(var(x))z<-pnorm(x,m,s)zi<-rev(z)i<-1:na2<--mean((2*i-1)*(log(z)+log(1-zi)))-nreturn(a2)}N<-100000mues<-c(10,15,20,25,30,35,40,45,50,55)and<-matrix(0,N,length(mues))for(jin1:length(mues)){for(iin1:N){z<-rnorm(mues[j])and[i,j]<-AD(z)}}# boxplots con menos datos para que grafico en eps no este tan pesadopocos<-sort(sample(1:N,size=5000))boxplot(and[pocos,1], and[pocos,2], and[pocos,3], and[pocos,4],and[pocos,5], and[pocos,6], and[pocos,7], and[pocos,8],and[pocos,9], and[pocos,10], ylim=c(0,1.1),ylab=expression(A^2), xlab="Tamanos de muestra", names=c("10", "15", "20", "25", "30", "35", "40", "45", "50", "55"), main="Anderson-Darling para F Normal",cex.main=1)
Figura F.1: Diagrama de Cajas de simulaciones
Ahora calculamos los cuantiles de la distribución usando
NotaCuantiles de A2
Código
probas<-c(.5,.6,.7,.8,.90,.91,.92,.93,.94,.95,.96,.97,.975,.98,.99,.995,.999)pes<-length(probas)cuantad<-matrix(0,pes,length(mues))for(jin1:length(mues)){cuantad[,j]<-quantile(and[,j], probs =probas)}# quitar comentario para imprimir en pantalla# rbind( c(0,mues),cbind(probas,round(cuantad,2)) )
Los cuantiles resultantes son:
cuantiles
10
15
20
25
30
35
40
45
50
55
50
0.32
0.32
0.33
0.33
0.33
0.33
0.34
0.34
0.34
0.34
60
0.35
0.36
0.37
0.37
0.38
0.38
0.38
0.38
0.38
0.38
70
0.40
0.42
0.42
0.42
0.43
0.43
0.43
0.43
0.43
0.43
80
0.47
0.48
0.49
0.49
0.50
0.50
0.50
0.50
0.50
0.50
90
0.58
0.60
0.61
0.61
0.62
0.62
0.62
0.62
0.62
0.62
91
0.59
0.62
0.63
0.63
0.63
0.63
0.64
0.64
0.64
0.64
92
0.61
0.63
0.65
0.65
0.65
0.65
0.66
0.66
0.66
0.66
93
0.63
0.66
0.67
0.67
0.68
0.68
0.68
0.68
0.68
0.68
94
0.66
0.68
0.69
0.70
0.70
0.70
0.70
0.71
0.71
0.71
95
0.69
0.71
0.72
0.73
0.73
0.73
0.74
0.74
0.74
0.74
96
0.72
0.75
0.76
0.77
0.77
0.77
0.77
0.78
0.77
0.78
97
0.76
0.80
0.81
0.82
0.82
0.82
0.82
0.83
0.82
0.83
97.5
0.79
0.83
0.84
0.85
0.86
0.85
0.85
0.86
0.86
0.86
98.0
0.83
0.87
0.88
0.89
0.89
0.89
0.89
0.90
0.90
0.90
99.0
0.93
0.98
0.99
1.01
1.00
1.01
1.01
1.01
1.01
1.01
99.5
1.04
1.09
1.11
1.12
1.12
1.13
1.13
1.13
1.13
1.13
99.9
1.28
1.33
1.38
1.40
1.41
1.41
1.45
1.39
1.42
1.43
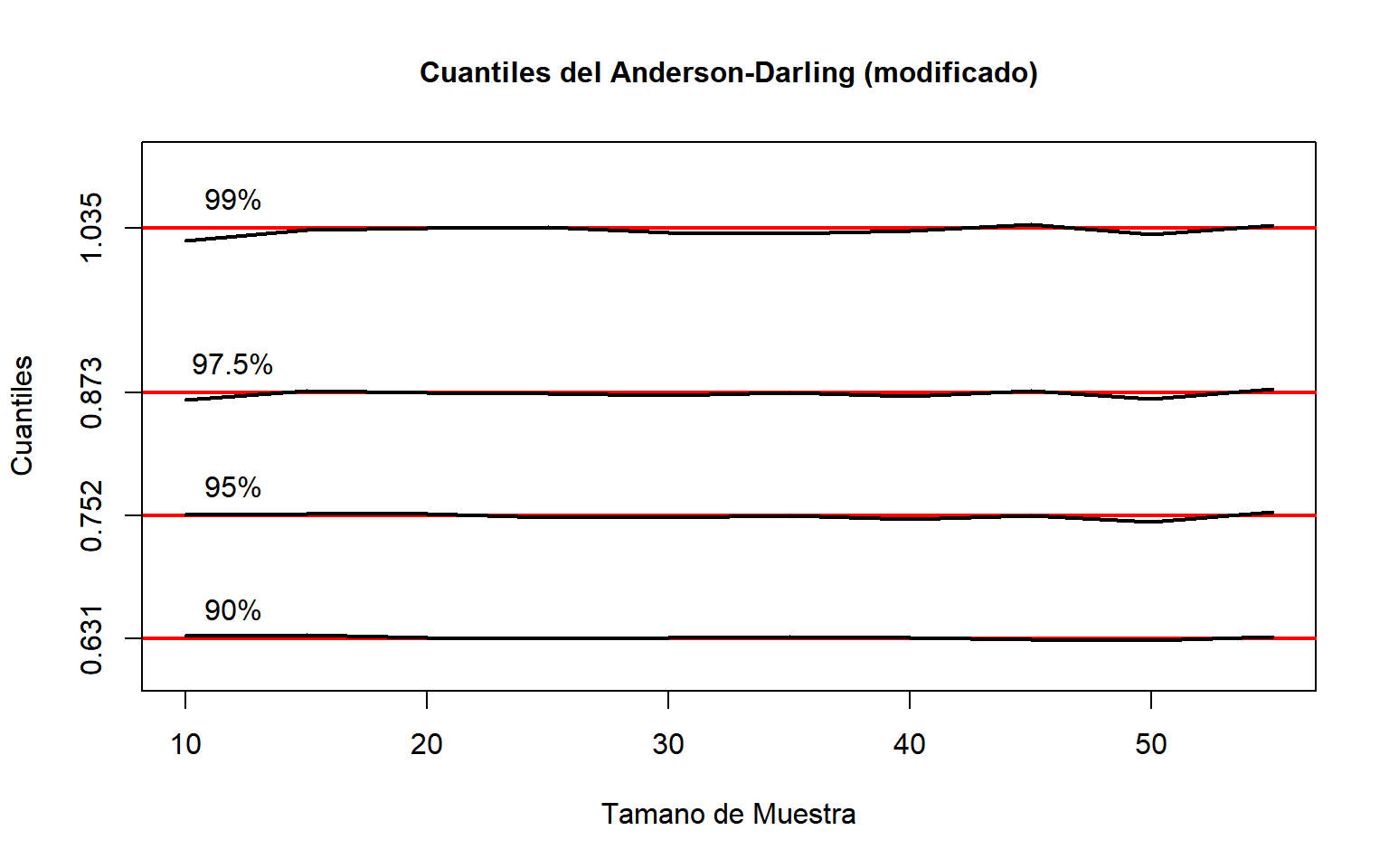
La distribución de \(A^2\) depende de \(n\). Una forma de tener un solo juego de cuantiles críticos es usar la siguiente modificación:
Algunos cuantiles convenientes para pruebas de bondad de ajuste son
\(90 \%\)
\(95 \%\)
\(97.5 \%\)
\(99 \%\)
0.631
0.752
0.873
1.035
La siguiente gráfica muestra que, efectivamente, al modificar los cuantiles de \(A^2\) mediante la transformación anterior, tenemos que la distribución de \(A_*^2\) no depende de \(n\), de modo que sólo necesitamos conocer los cuantiles antes mencionados.
NotaCuantiles de \(A^2_*\)
Código
sel<-c(5,10,13,15)aa<-cuantad[sel,]fac<-1+0.75/mues+2.25/(mues^2)aa<-t(fac*t(aa))adm<-c(.631,.752,.873,1.035)plot(mues, aa[1,],ylim=c(0.6,1.1),type="n",lwd=2,xlab="Tamano de Muestra", ylab="Cuantiles",main="Cuantiles del Anderson-Darling (modificado)", cex.main=1,yaxt="n")abline(h=adm, col="red",lwd=2)for(iin1:4){lines(mues,aa[i,],lwd=2)}axis(2,at=adm)text(rep(12,4), adm+.03, labels=c("90%","95%","97.5%","99%"))
Cuantiles de \(A^2_*\)
F.2 Centrar y escalar covariables
Al lector interesado, referimos a la Sección 3.11 de Seber et al.(2012).
La estandarización (también llamada normalización o escalado) se refiere al ajuste de los valores medidos en diferentes escalas respecto a una escala común. Es decir, ajusta todas las columnas al mismo rango.
Uno de los procedimientos comunes antes de ajustar cualquier modelo es el de modificar los valores observados de las covariables, centrandolas o escalandolas o ambas. Exploramos el efecto de este procedimiento.
Cabe mencionar que cualquier análisis debe mencionarse explícitamente el tipo de transformación que se le hizo a las variables cuando se muestran los resultados.
F.2.1 Centrado
El modelo que consideramos en el los primeros dos capítulos de estas notas corresponden a \(\boldsymbol{Y}=X\boldsymbol{\beta}+\boldsymbol{\epsilon}\) con \(\boldsymbol{\epsilon}\sim N_n(0,\sigma^2 I_n)\). Nos enfocaremos ahora en las columnas de \(X\) que corresponden a las covariables. Esto es \[
X_{(.1)}\qquad \text{ tal que }\qquad X=(\boldsymbol{1}_n,\ X_{(.1)})
\] Ahora consideramos los datos centrados en sus medias: \[
\widetilde{X}=\left(\boldsymbol{X}_{(.1)1}-\overline{\boldsymbol{X}}_{(.1)1}\boldsymbol{1}_n, \ \
\boldsymbol{X}_{(.1)2}-\overline{\boldsymbol{X}}_{(.1)2}\boldsymbol{1}_n, \ \ \ldots,\ \ \boldsymbol{X}_{(.1)k}-\overline{\boldsymbol{X}}_{(.1)k}\boldsymbol{1}_n\
\right)
\] Ahora consideramos el modelo \[
Y_i=\alpha_0+\beta_1\widetilde{x}_{i 1}+\cdots+\beta_{k}\widetilde{x}_{1 k}+\epsilon_i
\] donde \(\widetilde{x}_{i j}\) es el componente \(ij\) de \(\widetilde{X}\). Entonces la ordenada al origen \(\alpha_0\) es \[
\alpha_0=\beta_0+\beta_1 \overline{\boldsymbol{X}}_{(.1)1}+\cdots+\beta_{k} \overline{\boldsymbol{X}}_{(.1)k}
\]
El modelo lo denotamos como \(\boldsymbol{Y}=X_c \boldsymbol{\alpha}+\epsilon\), donde \[
\begin{align}
\boldsymbol{\alpha}^{\top}&=\left(\alpha_0, \beta_1, \ldots, \beta_{k}\right)=\left(\alpha_0, \boldsymbol{\beta}_c^{\top}\right).
\end{align}
\] Como la transformación es uno a uno, el estimador de mínimos cuadrados de \(\boldsymbol{\beta}_{\boldsymbol{c}}\) están intimamente relacionados: \[
\begin{align}
\widehat{\boldsymbol{\alpha}} & =\left(X_c^{\top} X_c\right)^{-1} X_c^{\top} \boldsymbol{Y} \\
& =\left(\binom{\boldsymbol{1}_n^{\top}}{\widetilde{X}^{\top}}\left(\boldsymbol{1}_n\ \ \widetilde{X}\right)\right)^{-1} \binom{\boldsymbol{1}_n^{\top}}{\widetilde{X}^{\top} }\boldsymbol{Y} \\[10pt]
& =\left(\begin{array}{cc}
n & \boldsymbol{0}^{\top} \\[5pt]
\boldsymbol{0} & \widetilde{X}^{\top} \widetilde{X}
\end{array}\right)^{-1}\binom{\boldsymbol{1}_n^{\top}}{\widetilde{X}^{\top} }\boldsymbol{Y} \qquad \qquad\because \quad \boldsymbol{1}_n^{\top}\widetilde{X}=\boldsymbol{0}^{\top}\\[10pt]
& =\left(\begin{array}{cc}
n^{-1} & \boldsymbol{0}^{\top} \\
\boldsymbol{0} & \left(\widetilde{X}^{\top} \widetilde{X}\right)^{-1}
\end{array}\right)\binom{\mathbf{1}_n^{\top} \boldsymbol{Y}}{\widetilde{X}^{\top} \boldsymbol{Y}} \\[10pt]
& =\left(\begin{array}{cc}
\overline{\boldsymbol{Y}}\\
\left(\widetilde{X}^{\top} \widetilde{X}\right)^{-1} \widetilde{X}^{\top} \boldsymbol{Y}
\end{array}\right)
\end{align}
\tag{F.1}\] entonces \[\widehat{\alpha}_0=\overline{\boldsymbol{Y}}\qquad \text{y}\qquad \widehat{\boldsymbol{\beta}}_c=\left(\widetilde{X}^{\top} \widetilde{X}\right)^{-1} \widetilde{X}^{\top} \boldsymbol{Y}.
\]
Por otro lado tenemos que \(\mathcal{C}\left(X_c\right)=\mathcal{C}(X)\), ya que su primera columna es igual y las subsecuente \(j\) de \(X_c\) es igual a la respectiva columna de \(X\) menos \(\overline{\boldsymbol{X}}_{(.1)j}\boldsymbol{1}_n\) para cada \(j=2, \ldots, k+1=p\). Así, \(X_c\) and \(X\) tienen la misma matriz de projección: \[
\begin{aligned}
P & =X_c\left(X_c^{\top} X_c\right)^{-1} X_c^{\top} \\
& =\left(\mathbf{1}_n, \widetilde{X}\right)\left(\begin{array}{cc}
n & \boldsymbol{0}^{\top} \\
\boldsymbol{0} & \widetilde{X}^{\top} \widetilde{X}
\end{array}\right)^{-1}\left(\mathbf{1}_n, \widetilde{X}\right)^{\top} \\
& =\frac{1}{n} \mathbf{1}_n \mathbf{1}_n^{\top}+\widetilde{X}\left(\widetilde{X}^{\top} \widetilde{X}\right)^{-1} \widetilde{X}^{\top}.
\end{aligned}
\tag{F.2}\]
Representamos como \(\boldsymbol{x}_i\) el \(i-\)ésimo renglón de \(X\), con los \(k\) elementos de covaribles. Esto es, excluye el primer elemento unitario asociado a \(\alpha_0\).
Ahora consideramos el \(i-\)ésimo elemento de la diagonal de \(P\) y de Proposición 2.1 tenemos \[
\begin{aligned}
h_{i i} & =\frac{1}{n}+\left(\boldsymbol{x}_i-\overline{\boldsymbol{x}}\right)^{\top} \frac{\mathbf{S}_{\widetilde{X}}^{-1}}{n-1}\left(\boldsymbol{x}_i-\overline{\boldsymbol{x}}\right) \\
& =\frac{1}{n}+\frac{\mathrm{DM}_i^2}{n-1}
\end{aligned}
\]
donde \(\overline{X}=\sum_{i=1}^n \boldsymbol{x}_i/n\), \(\mathbf{S}_{\widetilde{X}}=\widetilde{X}^{\top} \widetilde{X} /(n-1)\) es la covarianza muestral o estimador de la covarianza para las variables centradas y \(\mathrm{DM}_i\) es la distancia de Mahalanobis del \(i-\)ésimo vector de covariables observadas.
Entonces \(h_{i i}\) es una distancia de \(\boldsymbol{x}_i\) del promedio de los datos. Notamos entonces que el proceso de centrar las covariables no afecta el modelo ajustado\(\hat{\boldsymbol{Y}}\), así que los residuales para el modelo con covariables centradas y no centradas, son iguales. Usando Ecuación F.2, tenemos: \[
\begin{aligned}
SS_{\mathbf{Res}} & =\boldsymbol{Y}^{\top}\left(I_n-P\right) \boldsymbol{Y} \\
& =\boldsymbol{Y}^{\top}\left(I_n-\frac{1}{n} \mathbf{1}_n \mathbf{1}_n^{\top}-\widetilde{X}\left(\widetilde{X}^{\top} \widetilde{X}\right)^{-1} \widetilde{X}\right) \boldsymbol{Y} \\
& =\boldsymbol{Y}^{\top}\left(I_n-\frac{1}{n} \mathbf{1}_n \mathbf{1}_n^{\top}\right) \boldsymbol{Y}-\boldsymbol{Y}^{\top} \widetilde{P} \boldsymbol{Y} \\
& =\sum_i\left(Y_i-\overline{Y}\right)^2-\boldsymbol{Y}^{\top} \widetilde{P} \boldsymbol{Y}\\
&=SS_{\mathbf{T}}-SS_{\mathbf{R}}
\end{aligned}
\] donde \[
\begin{align}
\widetilde{P}&=\widetilde{X}\left(\widetilde{X}^{\top} \widetilde{X}\right)^{-1} \widetilde{X}^{\top}\\
&=P-\frac{1}{n} \mathbf{1}_n \mathbf{1}_n^{\top}\\
&=P- \mathbf{1}_n \left(\mathbf{1}_n^{\top}\mathbf{1}_n\right)^{-1}\mathbf{1}_n^{\top}.
\end{align}
\] como en Ecuación 1.12 .
F.2.2 Escalado
Supongamos ahora que escalamos las columnas de \(\widetilde{X}\). Sea \(s_j^2=\sum_i \widetilde{x}_{i j}^2/(n-1)\) y consideramos las nuevas variables \(x_{i j}^{\star}=\widetilde{x}_{i j} / s_j\). Así el modelo se convierte a \[
Y_i=\alpha_0+\gamma_1 x_{i 1}^{\star}+\cdots+\gamma_{k} x_{i k}^{\star}+\varepsilon_i, \quad \text{donde}\quad \gamma_j=\beta_j s_j.
\] Nuevamente porque la transformación es uno a uno, \[
\widehat{\gamma}_j=\widehat{\beta}_j s_j \qquad \text{ y } \qquad \widehat{\alpha}_0=\overline{\boldsymbol{Y}}.
\]
Si \(X^{\star}\) es la \(n\times k\) matriz de covariables estandarizadas y \(\gamma=\left(\gamma_1, \ldots, \gamma_{k}\right)^{\top}\), entonces reemplazando \(\widetilde{X}\) con \(X^{\star}\) en Ecuación F.1, tenemos \[
\widehat{\gamma}=\left(X^{\star \top} X^{\star}\right)^{-1} X^{\star \top} \boldsymbol{Y}=R_{X}^{-1} X^{\star \top} \boldsymbol{Y}
\] donde ahora \(R_{x x}\) corresponde a la matriz de correlación muestral de las covariables: \[
R_{x x}= \left(\begin{array}{cccc}
1 & r_{12} & \cdots & r_{1, k} \\
r_{21} & 1 & \cdots & r_{2, k} \\
\vdots & \vdots & \ddots & \vdots \\
r_{k,1} & r_{k,2} & \cdots & 1
\end{array}\right)
\] donde la correlación muestral de la \(j-\)ésima y \(k-\)ésima covariables es \[
r_{j k}=\frac{\sum_{i=1}^n\left(x_{(.1)ij}-\overline{\boldsymbol{X}}_{(.1)j}\right)\left(x_{(.1)ik}-\overline{\boldsymbol{X}}_{(.1)k}\right)}{s_{_{X_{(.1)j}}} s_{_{X_{(.1)k}}}}.
\]
Si denotamos las columnas de \(X^{\star}\) como \(X^{\star}=\left(\boldsymbol{X}_{.1}^{*}, \boldsymbol{X}_{.2}^{*}\ldots, \boldsymbol{X}_{.k}^{*}\right)\), tenemos que \(r_{j k}=\boldsymbol{X}_{.j}^{* \top} \boldsymbol{X}_{.k}^{*}\).
NotaEjemplo: Ajuste de un modelo lineal
Considerando el caso \(k=2\), temos \[
\mathbf{R}_{x x}=\left(\begin{array}{ll}
1 & r \\
r & 1
\end{array}\right)
\]
donde \(r=\boldsymbol{X}_{.1}^{* \top} \boldsymbol{X}_{.2}^{*}\).
Ahora, \[
\begin{aligned}
\binom{\widehat{\gamma}_1}{\widehat{\gamma}_2} & =\left(\begin{array}{ll}
1 & r \\
r & 1
\end{array}\right)^{-1}\binom{\boldsymbol{X}_{.1}^{\star^{\top}}}{\boldsymbol{X}_{.2}^{\star^{\top}} }\boldsymbol{Y} \\[10pt]
& =\frac{1}{1-r^2}\left(\begin{array}{cc}
1 & -r \\
-r & 1
\end{array}\right)\binom{\boldsymbol{X}_{.1}^{\star^{\top}} \boldsymbol{Y}}{\boldsymbol{X}_{.2}^{\star^{\top}} \boldsymbol{Y}}.
\end{aligned}
\] Para diminuir el número de subíndices, denotamos como \(s_1=s_{_{\boldsymbol{X}_{.1}}}\) y \(s_2=s_{_{\boldsymbol{X}_{.2}}}\).
Existe más de una técnica para transformar las covariables con diferentes objetivos. Las dos secciones anteriores se refieren a la estandarización pero también la normalización busca transformar las covariables para llevarlas a una escala o rango común, independiente de las unidades de medición.
Min-Max. Es una forma simple de escalar valores en una columna. Pero, trata de mover los valores hacia la media de la columna. Es el resultado de la resta del valor menos el valor mínimo entre la diferencia entre el valor máximo y el mínimo de la columna, según la siguiente fórmula \[
X_{i,\operatorname{nueva}}=\frac{X_i−\operatorname{mín}(\boldsymbol{X})}{\max(\boldsymbol{X})−\operatorname{mín}(\boldsymbol{X})}
\] Es un método para normalizar una variable en el sentido que se escalan los datos desde su valores originales a un rango entre 0 y 1.
Z score. Es el resultado de la restar cada valor menos la media poblacional y luego dividirlo entre la desviación estándar, como se aprecia en la siguiente fórmula \[
X_{i,\operatorname{nueva}}=\frac{X_i−\overline{\boldsymbol{X}}}{s_{_{\boldsymbol{X}}}}
\] Mín-Máx intenta acercar los valores a la media, pero cuando hay datos atípicos que son importantes y no se quiere perder su impacto, se opta por la normalización Z score. Z score es un método para estandarizar una variable, de tal forma que la variable modificada tenga media (promedio) igual a 0 y desviación estándar (error estándar) igual a 1.
NotaEjemplo: Normalizacion vs estandarización.
Para comprender las diferencias entre normalización y estandarización, es útil ver sus efectos visualmente y en términos de rendimiento del modelo. Primero visualizamos la modificación de datos bajo la transformación Mín-Máx y Z score usando los diagramas de caja.
Código
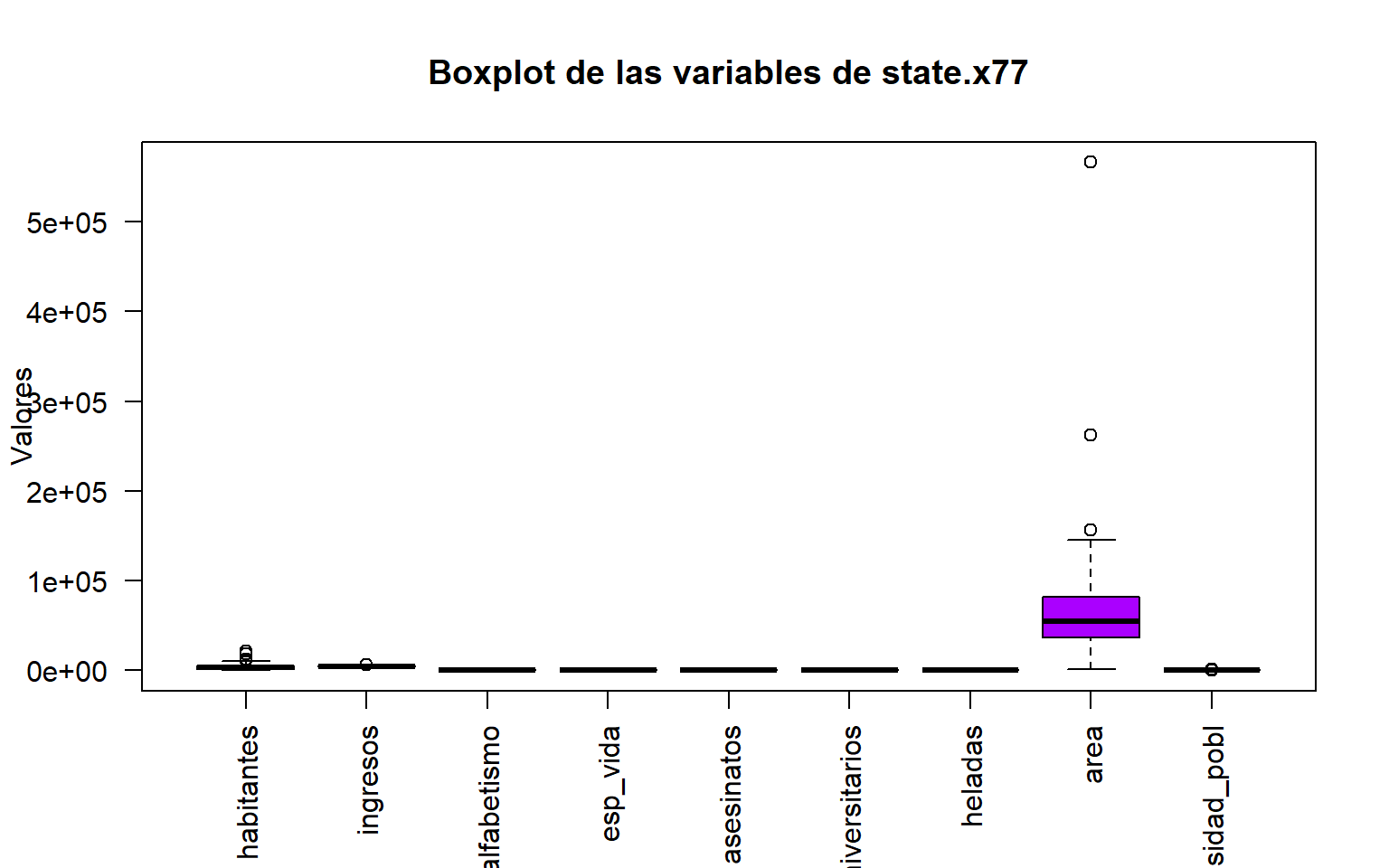
library(dplyr)library(datasets)datos<-as.data.frame(state.x77)datos<-rename(habitantes =Population, analfabetismo =Illiteracy, ingresos =Income, esp_vida =`Life Exp`, asesinatos =Murder, universitarios =`HS Grad`, heladas =Frost, area =Area, .data =datos)datos<-mutate(.data =datos, densidad_pobl =habitantes*1000/area)#par(oma=c(3,2,2,1), bg = rgb(.9,.9,.9))boxplot(datos, main ="Boxplot de las variables de state.x77", las =2, col =rainbow(ncol(datos)), ylab ="Valores", xlab ="")
Figura F.2: Diagrama de Cajas de variables sin modificar
Código
# Normalizar las variables usando Min-Maxdatos_normalizados<-as.data.frame(lapply(datos, function(x)(x-min(x))/(max(x)-min(x))))# Crear un boxplot para las variables normalizadasboxplot(datos_normalizados, main ="Boxplot de las variables normalizadas (Min-Max)", las =2, col =rainbow(ncol(datos_normalizados)), ylab ="Valores Normalizados", xlab ="")
Figura F.3: Diagrama de Cajas de variables normalizadas (Mín-Max)
Código
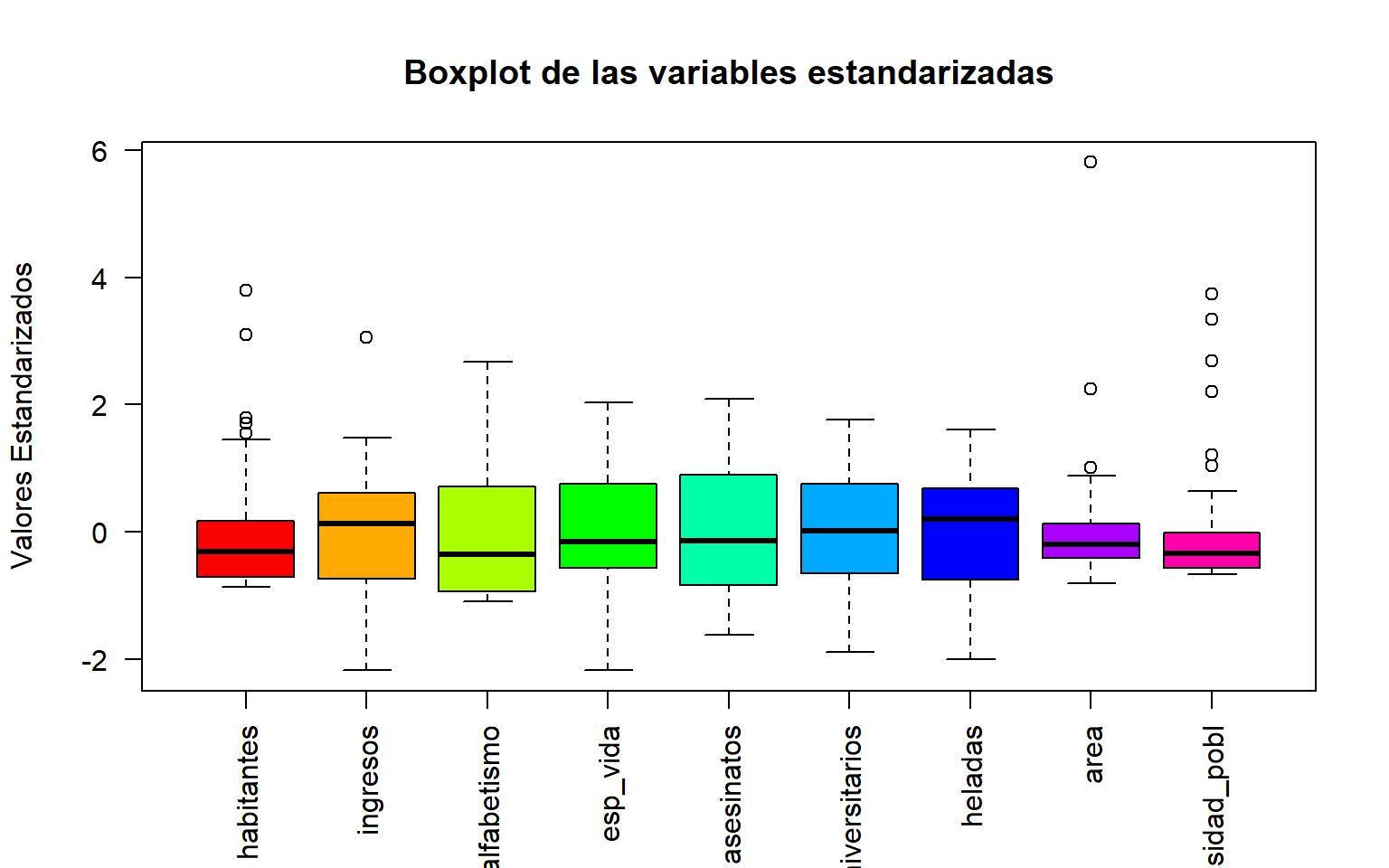
# Estandarizar las variables (media 0, desviación estándar 1)datos_estandarizados<-as.data.frame(scale(datos))# Crear un boxplot para las variables estandarizadasboxplot(datos_estandarizados, main ="Boxplot de las variables estandarizadas", las =2, col =rainbow(ncol(datos_estandarizados)), ylab ="Valores Estandarizados", xlab ="")
Figura F.4: Diagrama de Cajas de variables estandarizadas (Z score)
Ya que la variable de interés no se modifica, la copiamos en los data frames antes de ajustar los modelos.
Código
datos$Y<-datos$esp_vidadatos_normalizados$Y<-datos$Ydatos_estandarizados$Y<-datos$Ymodelo1<-lm(Y~ingresos+habitantes+area, data =datos)modelo2<-lm(Y~ingresos+habitantes+area, data =datos_normalizados)modelo3<-lm(Y~ingresos+habitantes+area, data =datos_estandarizados)summary(modelo1)
#>
#> Call:
#> lm(formula = Y ~ ingresos + habitantes + area, data = datos)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -2.59353 -0.89552 -0.02576 1.00822 2.35224
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 6.680e+01 1.338e+00 49.921 < 2e-16 ***
#> ingresos 1.035e-03 3.163e-04 3.274 0.00202 **
#> habitantes -4.826e-05 4.057e-05 -1.190 0.24023
#> area -4.340e-06 2.228e-06 -1.948 0.05753 .
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 1.238 on 46 degrees of freedom
#> Multiple R-squared: 0.2018, Adjusted R-squared: 0.1497
#> F-statistic: 3.876 on 3 and 46 DF, p-value: 0.01492
Los coeficientes del modelo lineal representan el cambio esperado en la variable de respuesta (variable dependiente) por cada unidad de cambio en el predictor (variable independiente).
Por ejemplo, si tienes un predictor en kilogramos y el coeficiente es 2.5, esto significa que por cada kilogramo adicional, la variable de respuesta aumenta en 2.5 unidades (en las mismas unidades de la variable de respuesta).
La interpretación es directa porque los coeficientes están en las unidades originales de las variables.
Sin embargo, si las variables tienen escalas muy diferentes (por ejemplo, una variable en metros y otra en pesos), los coeficientes no son comparables directamente. Un coeficiente grande en una variable puede deberse simplemente a que la escala de esa variable es mayor, no necesariamente a que tenga un mayor impacto en la variable de respuesta.
Si las variables tienen escalas muy diferentes, puede haber problemas numéricos en la estimación de los parámetros, especialmente en algoritmos que dependen de cálculos matriciales (como la inversión de matrices en mínimos cuadrados).
Además, en modelos que incluyen regularización (como Ridge o Lasso), las variables con escalas mayores pueden dominar el proceso de optimización, lo que puede sesgar los resultados.
Variables normalizadas (Mín-Máx)
La normalización Mín-Máx transforma las variables para que estén en un rango entre 0 y 1. Así que los coeficientes ahora representan el cambio esperado en la variable de respuesta por cada cambio proporcional en el rango del predictor.
La interpretación de los coeficientes ya no está en las unidades originales, sino en términos del rango de la variable. Por ejemplo, si un predictor tiene un rango de 0 a 100 y el coeficiente es 0.5, esto significa que un cambio de 0 a 100 en el predictor está asociado con un cambio de 0.5 unidades en la variable de respuesta.
Por otro lado el modelo ajustado a las covariables transformadas con Mín-Máx facilita la comparación de coeficientes entre variables con escalas muy diferentes, ya que todas están en el mismo rango (0 a 1).
Es importante enfatizar que esta transformación no afecta la bondad del ajuste del modelo (\(R^2\), \(p\)-valores, etc.), ya que la relación subyacente entre las variables no cambia.
Sin embago, la interpretación de los coeficientes puede ser menos intuitiva, ya que no están en las unidades originales y si hay valores atípicos en los datos, la normalización Mín-Máx puede verse afectada, ya que los valores extremos influyen en el cálculo del mínimo y el máximo.
Los coeficientes de las variables modificasas representan el cambio esperado en la variable de respuesta por cada cambio de una desviación estándar en el predictor.
Los coeficientes no están en las unidades originales, pero están en una escala común (desviaciones estándar), lo que facilita la comparación de la importancia relativa de los predictores.
Por ejemplo, si un predictor tiene un coeficiente de 0.7, esto significa que un aumento de una desviación estándar en ese predictor está asociado con un aumento de 0.7 unidades en la variable de respuesta. Una ventaja es entonces que facilita la comparación de la importancia relativa de los predictores, ya que todos están en la misma escala.
Por otro lado ayuda a evitar problemas numéricos en la estimación de los parámetros, especialmente cuando las variables tienen escalas muy diferentes. Esto es especialmente útil en modelos que incluyen regularización (como Ridge o Lasso), ya que la estandarización asegura que todos los predictores contribuyan de manera equitativa al proceso de optimización.
Las transformaciones de normalización o estandarización no afectan la bondad del ajuste del modelo. Métricas como \(R^2\), \(p\)-valores, y errores de predicción no cambian, ya que estas transformaciones no alteran las relaciones subyacentes entre las variables.
Al igual que con la normalización, la estandarización puede verse afectada por valores atípicos, ya que la media y la desviación estándar son sensibles a estos valores.
La elección entre normalización y estandarización depende del contexto y los objetivos del análisis. Si la interpretación en las unidades originales es importante, es mejor no transformar las variables. Si la comparación de coeficientes o la estabilidad numérica son prioritarias, la estandarización suele ser la opción preferida.
Más comentarios
Es importante notar que si ajustas un modelo con variables transformadas (normalizadas o estandarizadas), debes aplicar la misma transformación a los nuevos datos antes de hacer predicciones. Esto es crucial para garantizar que las predicciones sean consistentes con el modelo entrenado.
Como la normalización como la estandarización son sensibles a valores atípicos, se puede optar por métodos robustos de escalamiento, como el uso de la mediana y el rango intercuartílico (IQR) en lugar de la media y la desviación estándar.
En modelos con variables estandarizadas, los coeficientes pueden usarse para comparar la importancia relativa de los predictores. Sin embargo, esto no siempre es suficiente para determinar la importancia causal, especialmente si hay multicolinealidad entre las variables.
Además de la normalización y la estandarización, en algunos casos puede ser útil aplicar transformaciones no lineales (como logaritmos o raíces cuadradas) para mejorar la linealidad de las relaciones entre las variables. Estos temas se abordan en Sección 3.3.1 .
En resumen, la decisión de usar variables originales, normalizadas o estandarizadas depende del contexto del análisis, las escalas de las variables y los objetivos del modelo. Cada enfoque tiene sus ventajas y limitaciones, y es importante considerar estos factores al ajustar y interpretar un modelo lineal.
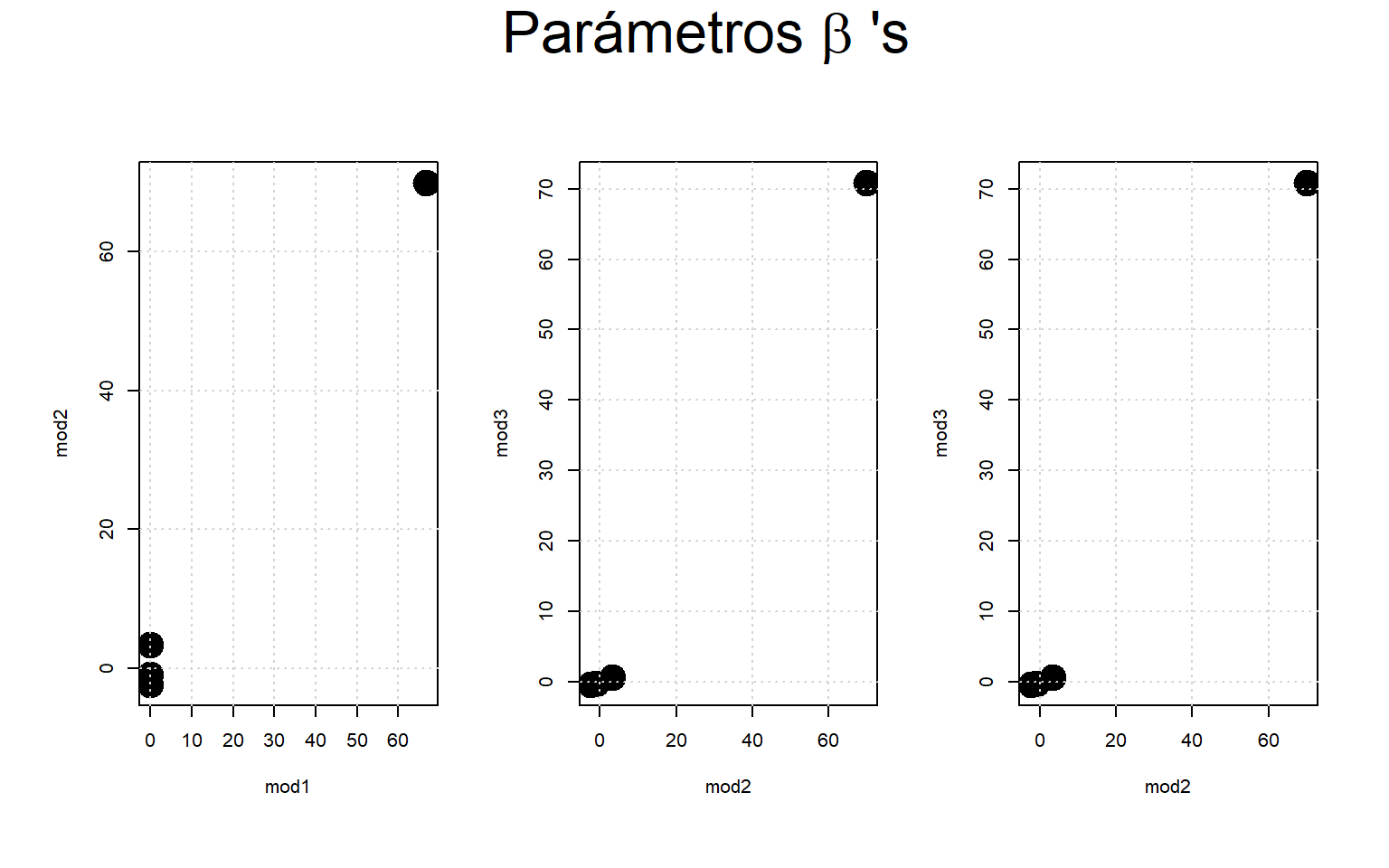
F.3 Análisis de Componentes Principales
De acuerdo con Shlens, J. (2014), con un pequeño esfuerzo adicional, el ACP proporciona una hoja de ruta sobre cómo reducir un conjunto de datos complejo a una dimensión menor para revelar la estructura simplificada, a veces oculta, que los datos pueden evidenciar.
El objetivo del análisis de componentes principales es calcular la base más significativa para reexpresar un conjunto de datos ruidosos. La esperanza es que esta nueva base filtre el ruido y revele la estructura oculta. En otras palabras, el objetivo del ACP es determinar qué dinámicas son importantes, cuáles son redundantes y cuáles son solo ruido.
library(tidyverse)library(plotly)autompg<-read.table("http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data", quote ="\"", comment.char ="", stringsAsFactors =FALSE)colnames(autompg)<-c("mpg", "cyl", "disp", "hp", "wt", "acc", "year", "origin", "name")autompg<-subset(autompg, autompg$hp!="?")autompg<-subset(autompg, autompg$name!="plymouth reliant")rownames(autompg)<-paste(autompg$cyl, "cylinder", autompg$year, autompg$name)autompg<-subset(autompg, select =c("mpg", "cyl", "disp", "hp", "wt", "acc", "year"))autompg$hp<-as.numeric(autompg$hp)auto_pca<-prcomp(autompg[c("mpg", "wt", "hp")], scale=FALSE)# Load scores for individuals (contained in auto_pca$x)data_pca<-autompg[c("mpg", "wt", "hp")]%>%mutate(PC1 =auto_pca$x[, 1], PC2 =auto_pca$x[, 2], PC3 =auto_pca$x[, 3])# Extract centre. This will be used in the plot.pca_center<-auto_pca$centercenter_tibble<-tibble("mpg"=pca_center[[1]],"wt"=pca_center[[2]],"hp"=pca_center[[3]])# Extract loadings.pca_loadings<-auto_pca$rotation# Use the loadings and centre to find where each point sits along PC1 and PC2# when represented in the original 3D space.auto_pca<-data_pca%>%mutate( PC1_mpg =(PC1*pca_loadings[1, 1])+pca_center[[1]], PC1_wt =(PC1*pca_loadings[2, 1])+pca_center[[2]], PC1_hp =(PC1*pca_loadings[3, 1])+pca_center[[3]], PC2_mpg =(PC2*pca_loadings[1, 2])+pca_center[[1]], PC2_wt =(PC2*pca_loadings[2, 2])+pca_center[[2]], PC2_hp =(PC2*pca_loadings[3, 2])+pca_center[[3]], PC3_mpg =(PC3*pca_loadings[1, 3])+pca_center[[1]], PC3_wt =(PC3*pca_loadings[2, 3])+pca_center[[2]], PC3_hp =(PC3*pca_loadings[3, 3])+pca_center[[3]],)# Visualisationfig<-plot_ly( data =auto_pca, x =~mpg, y =~wt, z =~hp, type ="scatter3d", # What kind of plot. mode ="markers", # What kind of marking (something like geom in ggplot) name ="Datos", # This label will go in the legend. marker =list(size =2, opacity =0.9, color ="#006363", lines =list(color ='#006363', width =1), showlegend =FALSE))# Add title and axis labelsfig<-fig%>%layout(margin =list(t =90), title =list(text ="Componentes principales", font =list(size =24, family ="Open Sans")), scene =list(xaxis =list( title ="mpg"), yaxis =list(title ="wt"), zaxis =list( title ="hp")))fig<-fig%>%# Add centre markadd_trace( x =~mpg, y =~wt, z =~hp, data =center_tibble, type ='scatter3d', mode ='markers', marker =list(size =6, opacity =1,color ='red',symbol ="x"), name ="Center", inherit =FALSE)%>%# Add PC1 lineadd_trace( data =auto_pca, x =~PC1_mpg, y =~PC1_wt, z =~PC1_hp, type ='scatter3d', mode ='lines', name ='PC1', line =list(color ="#D55E00", width =6), inherit =FALSE)%>%# Add PC2 line.add_trace( data =auto_pca, x =~PC2_mpg, y =~PC2_wt, z =~PC2_hp, type ='scatter3d', mode ='lines', name ='PC2', line =list(color ="#00517f", width =4), inherit =FALSE)%>%layout( scene =list( xaxis =list(title ="mpg"),yaxis =list(title ="wt"), zaxis =list(title ="hp")))fig<-fig%>%add_trace( data =auto_pca, x =~PC3_mpg, y =~PC3_wt, z =~PC3_hp, type ='scatter3d', mode ='lines', name ='PC3', line =list(color ="#00b299", width =6), inherit =FALSE)fig
Figura F.7: Datos y 2 Componentes Principales.
Lo que pregunta el ACP es: ¿Existe otra base, que sea una combinación lineal de la base original, que reexpresa mejor nuestro conjunto de datos?
En la búsqueda de esta propuesta, el ACP hace una suposición estricta pero poderosa: la linealidad de las relaciones más importantes en los datos.
La linealidad simplifica enormemente el problema al restringir el conjunto de bases potenciales.
Con esta suposición, el ACP ahora se limita a reexpresar los datos como una combinación lineal de sus vectores base. Sea \(X\) el conjunto de datos original, donde cada columna es una muestra única de nuestro conjunto de una variable. Podemos llegar a conocer si hay una relación lineal de los elementos de la muestra a través de graficar las observaciones por pares de variables, pero es la matriz de covarianza, que mide las relaciones lineales entre cualesquiera par de variables.
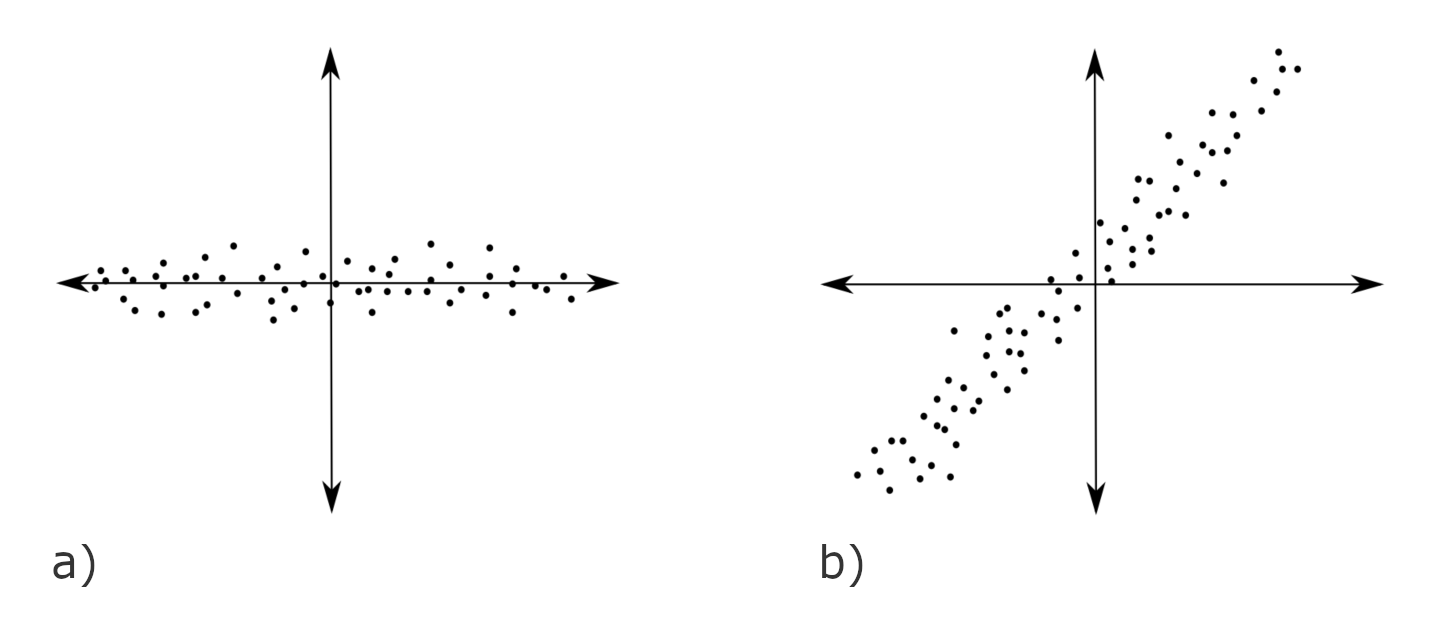
En la siguiente figura de dispersión tenemos dos casos de datos de dos variables. En a) la primera variable tiene una alta dispersión, contraria a la de la segunda variable. También se observa que hay una débil relación lineal entre variables. En b) la dispersión de ambas variables es grande y presentan una fuerte relación lineal.
Figura F.8: Fuente Principal component analysis with linear algebra (Jeff Jauregui)
Estos datos sintéticos tienen matrices de covarianzas \[
S=\frac{X^{\top}(I_n-\frac{1}{n}1_{n\times n})X}{n-1}
\] con valores \[
S=\left[\begin{array}{cc}
95 & 1 \\
1 & 5
\end{array}\right]\qquad \text{ y }\qquad
S=\left[\begin{array}{cc}
50 & 40 \\
40 & 50
\end{array}\right],
\] respectivamente. Los dos conjuntos de datos, en cierto sentido, son muy similares: ambos esencialmente forman una tira rectangular delgada, agrupada a lo largo de una línea. Sin embargo, sus matrices de covarianza son completamente diferentes.
El ACP proporciona un mecanismo para reconocer esta similitud geométrica mediante medios algebraicos. Dado que \(S\) es una matriz simétrica, puede ser diagonalizada ortogonalmente por el teorma de descomposición espectral (Teorema C.5).
Si \(X\) es la matriz de datos para \(k\) variables, sabemos que \(S\) cumple \[
S=T\Lambda T^{\top}
\] con \(\Lambda=\operatorname{diag}(\lambda_1,\lambda_2,\ldots,\lambda_k)\), valores propios de \(S\). Para ACP consideraremos que \(\Lambda\) tiene los valores propios en orden decreciente (\(\lambda_1 \geq \lambda_2 \geq \ldots \geq \lambda_k \geq 0\)) y en ese mismo orden \(T\), matriz ortogonal, tiene como columnas los eigenvalores correspondientes \(\boldsymbol{u}_1, \ldots, \boldsymbol{u}_k\). Estos eigenvectores se llaman los componentes principales del conjunto de datos.
Nota: siempre puedes reemplazar cualquiera de los \(\boldsymbol{u}_i\) por sus negativos.
Como la traza de \(S\) es la suma de las varianzas de todas las \(k\) variables. Llamemos a esto la varianza total (VT) del conjunto de datos. Por otro lado, la traza de una matriz es igual a la suma de sus valores propios, así que \(\text{VT}=\lambda_1+\ldots+\lambda_k\).
La siguiente interpretación es fundamental para el ACP:
La dirección en \(\mathbb{R}^k\) dada por \(\boldsymbol{u}_1\) (la primera dirección principal) “explica” o “representa” una cantidad \(\lambda_1\) de la varianza total: \[
\frac{\lambda_1}{\text{VT}}.
\] De manera similar, la segunda dirección principal \(\boldsymbol{u}_2\) representa la fracción \(\lambda_2/ \text{VT}\) de la varianza total, y así sucesivamente.
Así, el vector \(\boldsymbol{u}_1 \in \mathbb{R}^k\) apunta en la dirección más “significativa” del conjunto de datos.
Entre todas las direcciones que son ortogonales a \(\boldsymbol{u}_1\), es \(\boldsymbol{u}_2\) la que apunta en la dirección más “significativa” del conjunto de datos.
Entre las direcciones ortogonales tanto a \(\boldsymbol{u}_1\) como a \(\boldsymbol{u}_2\), es la del vector \(\boldsymbol{u}_3\) la apunta en la dirección más significativa, y así sucesivamente.
A continuación elaboramos un ejemplo paso a paso. Consideramos dos variables: “mpg” y “wt” de la base de datos de carros. Obtenemos \(S\) y los eigenvalores de \(S\)
NotaEjemplo: Con dos covariables.
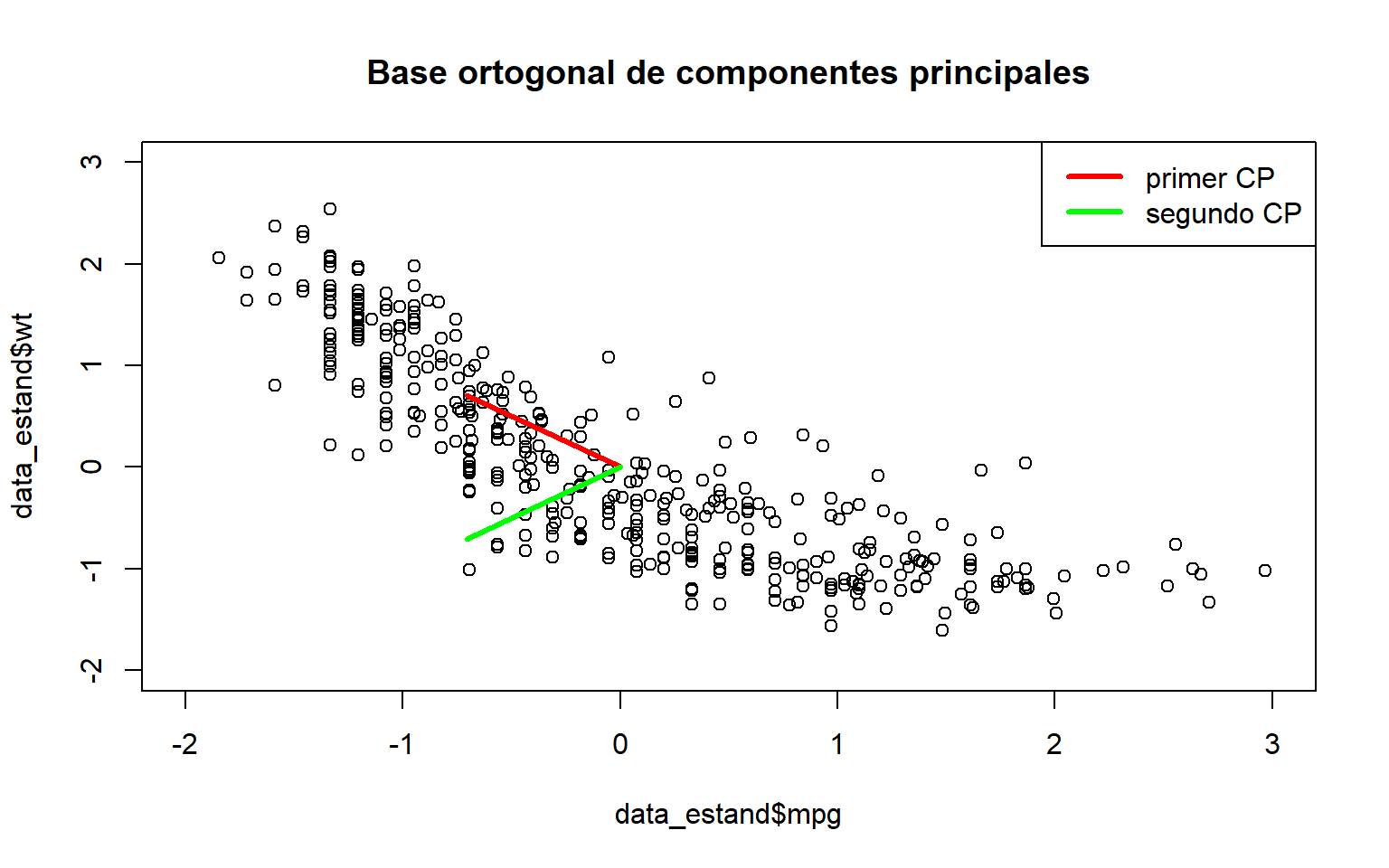
Como quiero graficar directamente los componentes principales de \(T\) junto con los datos y que sean visibles, primero estandarizamos los datos.
La base con la que queremos transformar los datos es la formada por los eigenvectores, representados por los vectores ortonormales en rojo y verde:
Código
plot(data_estand$mpg,data_estand$wt, main="Base ortogonal de componentes principales", xlim=c(-2,3),ylim=c(-2,3))segments(0,0,ei$vectors[1,1],ei$vectors[2,1],col="red",lwd=3)segments(0,0,ei$vectors[1,2],ei$vectors[2,2],col="green",lwd=3)legend("topright",c("primer CP", "segundo CP"),lwd=3,col=c("red","green"))
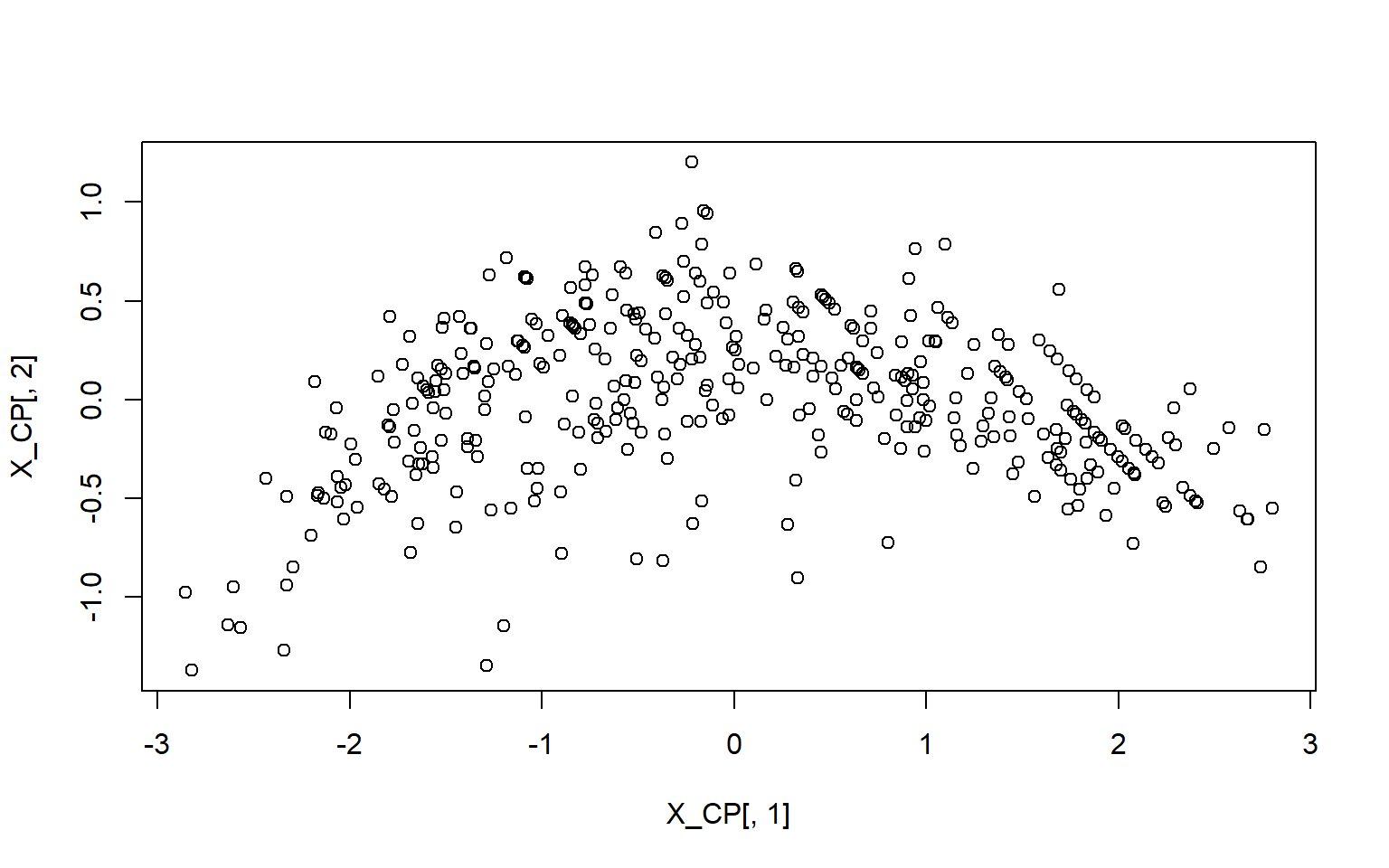
Para realizar la transformación de los datos en la base ortogonal, \[
X_{\text{CP}}= T^{\top}X^{\top}
\] ya que \(T^{-1}=T^{\top}\). La grafica de los datos con esta base es:
Aunque ACP es un método ampliamente aceptado, tiene las limitaciones que se derivan de considerar solo las relaciones de las variables, capturadas a través de sus correlaciones. Sin embargo, de acuerdo con Shlens (2014) también puede presentar limitaciones cuando los datos están lejanos a tener distribución aproximadamente gausiana. Shlens (2014) también discute, pero sin ahondar en las posibles aplicaciones, la extensión de ACP a través de la descomposición de valores singulares (Teorema C.9).
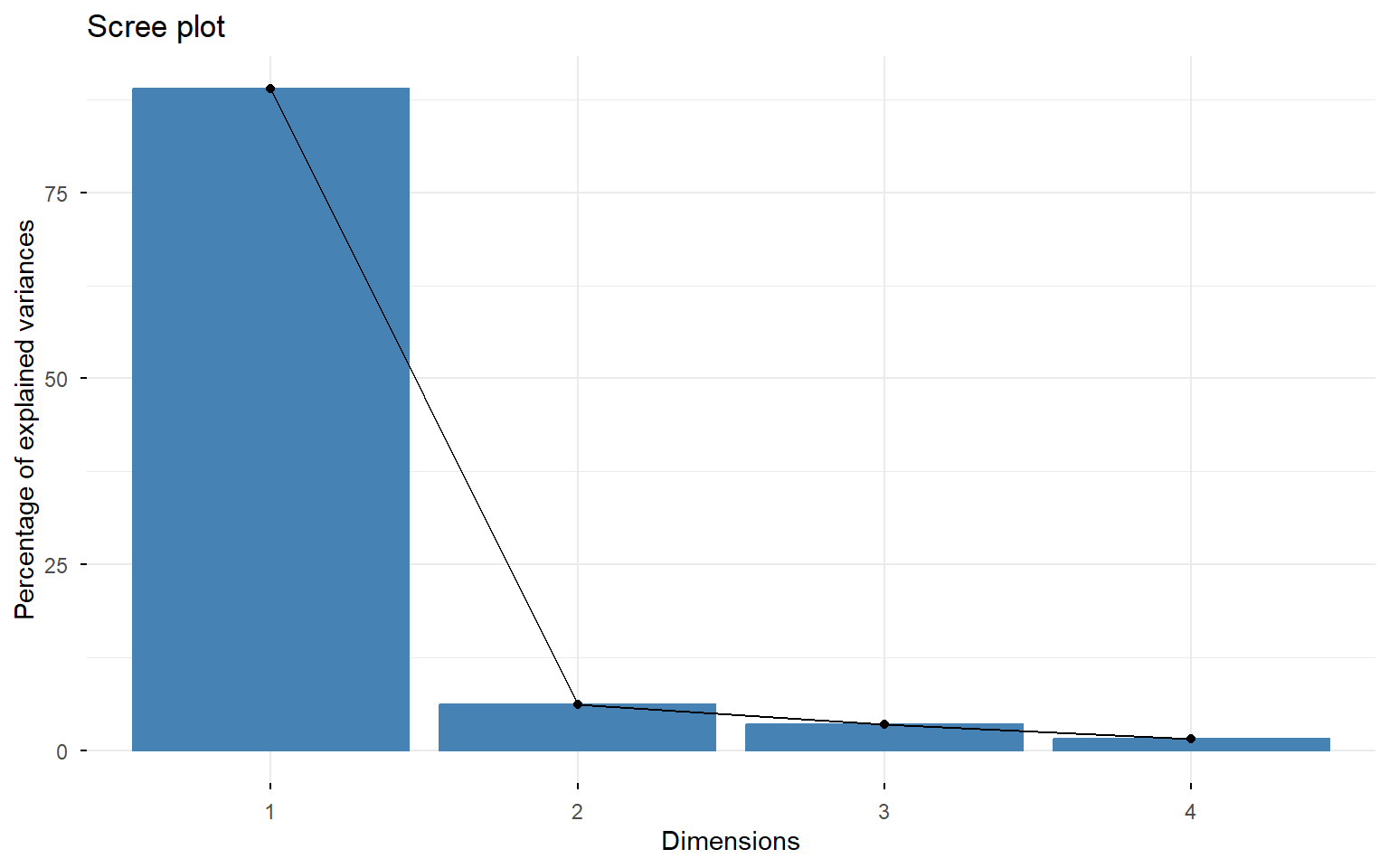
#plot(summary(auto_pca)$importance[2,],pch=19,cex=2,main="Proporción de Varianza Total",xlab="Número de componentes",ylab="%",t="n")#grid()#lines(summary(auto_pca)$importance[2,],pch=19,cex=2,t="p")cumsum(auto_pca$sdev^2)
#compara auto_pca$x con #pca_loadings <- auto_pca$rotation#t(t(pca_loadings)%*%t(scale(autompg[c("mpg", "wt","hp","disp")]))))
Los datos expresados según los dos componentes principales son: \[
\begin{align}
\text{CP}_1&\approx 0.4787\times\text{mpg}-0.5108\times\text{wt}-0.4979\times\text{hp}-0.5117\times \text{disp}\\
\text{CP}_2&\approx -0.8539\times\text{mpg}-0.0958\times\text{wt}-0.4139\times\text{hp}-0.3005\times \text{disp}.
\end{align}
\]
F.4 Coeficiente de Correlación Parcial
La correlación parcial mide la relación entre dos variables mientras se controla el efecto de una o más variables adicionales. En otras palabras, representa la conexión entre estas dos variables después de eliminar la influencia de las variables de control, lo que permite analizar su relación más “pura” o directa.
Si el valor de correlación parcial es cercano a 1 o -1, indica una relación fuerte entre las dos variables incluso después de ajustar por las variables de control.
Si el valor es cercano a 0, significa que las dos variables no están relacionadas directamente cuando se considera el efecto de las otras variables.
Por ejemplo si se está analizando la relación entre el nivel de actividad física (Variable \(X\)) y la salud cardiovascular (Variable \(Y\)), pero deseas eliminar el impacto de la edad (Variable \(Z\)) en esta relación. Usando correlación parcial, podrías obtener una medida que refleje cuánto se relacionan \(X\) y \(Y\) únicamente, sin que la edad influya.
F.4.0.1 Correlación parcial
La correlación parcial \(r_{XY,Z}\) nos dice que tan fuertemente \(X\) y \(Y\) se correlacionan si la correlación de cada una con \(Z\) se elimina. Formalmente, \[
r_{XY,Z}=\frac{r_{XY}-r_{XZ}r_{YZ}}{\sqrt{(1-r_{XZ}^2)(1-r_{YZ}^2)}}
\]
ImportanteDemostración
Sin pérdida de generalidad suponemos que \(X_1,\ldots,X_n\), \(Y_1,\ldots,Y_n\), \(Z_1,\ldots,Z_n\) son las observaciones centradas de \(X\), \(Y\) y \(Z\), respectivamente.
Para definir \(r_{XY,Z}\) consideramos los modelos \[
\begin{align}
X&=b_{XZ}Z+\epsilon_X,\\
Y&=b_{YZ}Z+\epsilon_Y,
\end{align}
\] cuyos residuales son \[
\begin{align}
e_1=X-\hat{X}=X-\hat{b}_{XZ}Z\\
e_2=Y-\hat{Y}=Y-\hat{b}_{YZ}Z.
\end{align}
\] De estos definimos \(r_{XY,Z} := r_{e_1,e_2}\).