Apéndice D — Distribuciones Fundamentales
Además de las distribuciones básicas que se introducen en un primer curso de probabilidad y estadística (como Bernoulli, Binomial, Poisson, Uniforme, Exponencial, Normal -Gaussiana- y Gamma), presentamos algunas funadmentales para el cálculo de intervalos y la prueba de hipótesis de algunos modelos estadísticos. Esta se derivan a partir del Teorema de Cambio de Variable (univariado o multivariado)
Teorema D.1 (Teorema de cambio de variable) Sea \(X_1,\ldots,X_n\) v.a.’s continuas con fd conjunta \(f_{X_1,\ldots, X_n}\left(x_1,\ldots, x_n\right)\). Sea \(\mathfrak{X}=\left\{\boldsymbol{x}\in \mathbb{R}^n: f_{X_1,\ldots, X_n}\left(\boldsymbol{x})\right)>0\right\}\). Asumimos que:
- \(\{y_i=g_i\left(\boldsymbol{x}\right)\}_{i=1,\ldots,n}\) definen una transformación 1 a 1 de \(\mathfrak{X}\) a \(\mathfrak{Y}\).
- Las primeras derivadas parciales de \(x_i=g_i^{-1}\left(\boldsymbol{y}\right)\) son continuas en \(\mathfrak{Y}\).
- El Jacobiano de la transformación no se anula para \(\boldsymbol{y} \in \mathfrak{Y}\).
Entonces la fd conjunta de \(\{Y_1=g_1\left(\boldsymbol{x}\right)\}_{i=1,\ldots,n}\) es \[ f_{Y_1,\dots, Y_n}\left(y_1,\ldots, y_n\right)= f_{X_1,\ldots, X_n}\left(g_1^{-1}\left(y_1, \ldots, y_n\right),\ldots, g_n^{-1}\left(y_1,\ldots, y_n\right)\right) |J|I_{\mathfrak{V}}\left(y_1,\ldots, y_n\right), \] donde \[ \mid J\mid \ =\left|\begin{array}{lcl} \frac{\partial x_1}{\partial y_1} &\cdots& \frac{\partial x_1}{\partial y_n} \\ \frac{\partial x_2}{\partial y_1} &\cdots& \frac{\partial x_2}{\partial y_n} \\ \vdots &\ddots&\vdots\\ \frac{\partial x_n}{\partial y_1} &\cdots& \frac{\partial x_n}{\partial y_n} \end{array}\right|. \]
D.1 Distribución Ji cuadrada
Definición D.1 (\(\chi^2(k)\)) La v.a. \(X\) tiene distribución \(\chi^2(k)\) ssi tiene fd \[ f_X(x)=\frac{1}{2^{k/2}\Gamma(k / 2)} x^{k / 2-1} \exp\left(-\frac{1}{2}x\right) I_{(0, \infty)}(x),\ \ k\in \mathbb{N}. \]
Proposición D.1 (FGM Ji cuadrada) La función generadora de momentos de \(X \sim \chi^2(k)\), \(m_X(s)=\mathbb{E}\left[\exp\{sX\}\right]\), es igual a \[ m_X(s)= (1-2 s)^{-k / 2}, \qquad \text{para } s<\frac{1}{2}. \]
De la FGM tenemos que si \(X\sim \chi^2(k)\),
- \(\mathbb{E}(X)=m_X^{\prime}(0)=k\)
- \(\text{Var}(X)=m_X^{\prime\prime}(0)-k^2=2k\).
Teorema D.2 Si \(X_i, i=1,2, \ldots, m\), son v.a. independientes y tal que \(X_i\sim N(\mu_i,\sigma_i^2)\), entonces \[ U:=\sum_{i=1}^m\left(\frac{X_i-\mu_i}{\sigma_i}\right)^2 \sim \chi^2(m) \]
Para demostrar Teorema D.4, primero demostramos el siguiente teorema
Teorema D.3 Sea \(X_1, \ldots, X_{m}\) una m.a. de una población con distribución \(N(\mu,\sigma^2)\), entonces \(\overline{\boldsymbol{X}}\) es independiente de \((X_1-\overline{\boldsymbol{X}},\ X_2-\overline{\boldsymbol{X}},\ \ldots, X_m-\overline{\boldsymbol{X}}\ )^{\top}\).
Para demostrar esto, tenemos que mostrar que \(\overline{X}\) y \(X_1-\overline{X}, X_2-\overline{X},\ldots, X_m-\overline{X}\) tienen distribución conjunta Normal multivariada y que \(\operatorname{Cov}(\overline{X},X_i−\overline{X})=0\) para \(i=1,\ldots,m\).
Teorema D.4 Sea \(X_1, \ldots, X_{m}\) una m.a. de una población con distribución \(N(\mu,\sigma^2)\), entonces \[ \frac{1}{\sigma^2} \sum_1^{m}\left(X_i-\overline{\boldsymbol{X}}\right)^2 \sim \chi^2(m-1) \]
La demostración la presentaremos posteriormente como la aplicación de un teorema.
D.1.1 No centrada
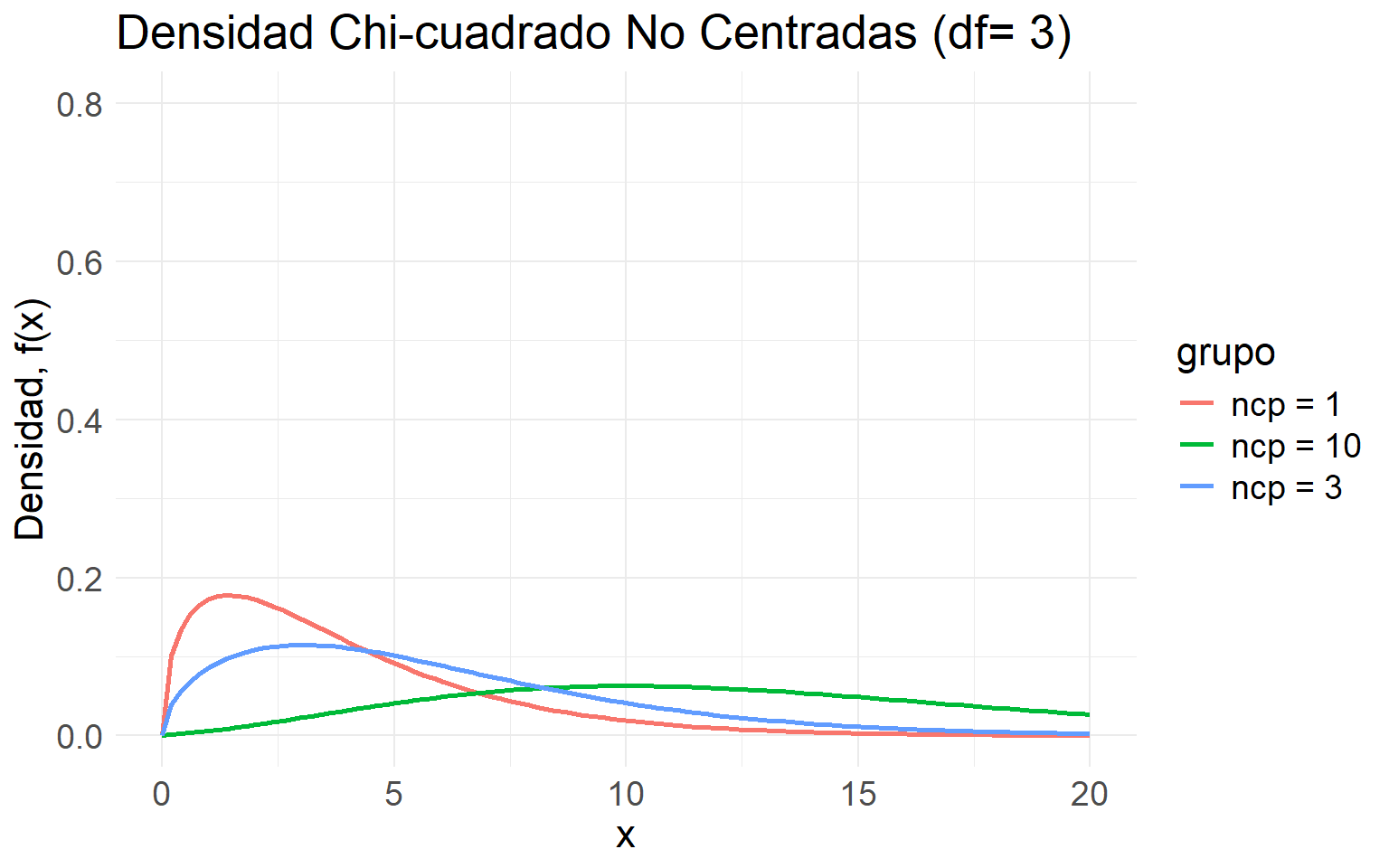
Definición D.2 (Ji cuadrada no centrada) Sean \(X_1, \ldots, X_n\) v.a.’s independientes, tales que \(X_i \sim N\left(\mu_i, 1\right)\). Entonces \[ W=\sum_{i=1}^n X_i^2 \] tiene distribución Ji cuadrada no centrada con \(n\) grados de libertad y parametro de no centralidad \(\gamma=\sum_{i=1}^n \mu_i^2 / 2=\boldsymbol{\mu}^{\top}\boldsymbol{\mu}/2\). Denotamos \(W \sim \chi^2(n, \gamma)\).
De la definición de Ji cuadrada no centrada tenemos que si \(X \sim \chi^2(r, \gamma)\) y \(Y \sim \chi^2(s, \delta)\) con \(X\) y \(Y\) independendientes, entonces \((X+Y) \sim \chi^2(r+s, \gamma+\delta)\).
Proposición D.2 (FGM Ji cuadrada no centrada) Si \(W\sim \chi^2(n, \gamma)\), \[ m_W(s)=\mathbb{E}\left[\exp\{sX\}\right]=(1-2s)^{-n/2} \exp\left\{-\gamma\left[1-\frac{1}{1-2s}\right]\right\}. \]
Proposición D.3 La función de densidad de \(W\sim \chi^2(n, \gamma)\) es \[ f_W(w)=\sum_{i=0}^{\infty}\frac{\gamma^i\exp(-\gamma)}{i!}f_{X_i}(w), \] donde \(f_{X_i}\) es la fd de \(X_i\sim \chi^2(n+2i)\), \(i=0,\cdots\).
Esta proposición nos dice que la distribución Ji cuadrada es equivalente a la mezcla de distribuciones Ji cuadradas independientes, con distribución de mezcla Poisson.
De la FGM tenemos que si \(W\sim \chi^2(n,\gamma)\),
- \(\mathbb{E}(W)=n+2\gamma\)
- \(\text{Var}(W)=2n+8\gamma\).
D.1.2 Percentil
Percentiles y cuartiles son una medida de variación que describe que tan dispersa es una distribución o datos. Los percentiles dividen los datos en 100 partes iguales, así que se describen de 0 a \(100\%\), mientras que los cuartiles los dividen de 0 a 1. Así un percentile de \(\alpha \times 100\%\) equivale al cuartil \(\alpha\), con \(\alpha \in (0,1).\)
El percentil \(\alpha \times 100 \%\) de las distribuciones, centrada \(\chi^2(r)\) o no centrada \(\chi^2(r, \gamma)\) son los valores \(\chi^2(\alpha; r)\) y \(\chi^2(\alpha; r,\gamma)\) que satisface: \[ \mathbb{P}\left(\chi^2(r) \leq \chi^2(\alpha; r)\right) = \alpha \ \ \ \text{y } \ \ \ \mathbb{P}\left(\chi^2(r, \gamma) \leq \chi^2(\alpha; r, \gamma)\right) = \alpha, \] respectivamente.
La fd de \(X \sim \chi^2(n, \gamma)\) se puede también expresar como \[ f_X(x)=\frac{1}{2} \exp\left\{-(x+\gamma) / 2\right\}\left(\frac{x}{\gamma}\right)^{n / 4-1 / 2} \mathbb{I}_{n / 2-1}\left(\sqrt{\gamma\, x}\ \right), \]
donde \(\mathbb{I}_\nu(y)\) es la función de Bessel modificada: \[ \mathbb{I}_\nu(y)=(y / 2)^\nu \sum_{j=0}^{\infty} \frac{\left(y^2 / 4\right)^j}{j!\,\Gamma(\nu+j+1)}. \]
Código
library(ggplot2)
# Generar datos
df <- data.frame(
x = c(
rep(seq(0, 20, length.out = 100),3)
),
densidad = c(
dchisq(seq(0, 20, length.out = 100), df = 1),
dchisq(seq(0, 20, length.out = 100), df = 3),
dchisq(seq(0, 20, length.out = 100), df = 10)
),
grupo = factor(rep(c("df = 1", "df = 3", "df = 10"), each = 100))
)
# Crear primer gráfico
ggplot(df, aes(x = x, y = densidad, color = grupo)) +
geom_line(size = 1) +
labs(title = "Densidad distribución Ji-cuadrada",
x = "x",
y = "Densidad, f(x)") +
theme_minimal() +
theme(
plot.title = element_text(size = 20),
axis.title = element_text(size = 17),
axis.text = element_text(size = 17),
legend.title = element_text(size = 17),
legend.text = element_text(size = 17)
)
# Generar datos
df_nc <- data.frame(
x = rep(seq(0, 20, length.out = 100), 3),
densidad = c(
dchisq(seq(0, 20, length.out = 100), df = 3, ncp = 1),
dchisq(seq(0, 20, length.out = 100), df = 3, ncp = 3),
dchisq(seq(0, 20, length.out = 100), df = 3, ncp = 10)
),
grupo = factor(rep(c("ncp = 1", "ncp = 3", "ncp = 10"), each = 100))
)
# Crear segundo gráfico
ggplot(df_nc, aes(x = x, y = densidad, color = grupo)) +
geom_line(size = 1) +
labs(title = "Densidad Chi-cuadrado No Centradas (df= 3)",
x = "x",
y = "Densidad, f(x)") +
theme_minimal() +
theme(
plot.title = element_text(size = 20),
axis.title = element_text(size = 16),
axis.text = element_text(size = 14),
legend.title = element_text(size = 16),
legend.text = element_text(size = 14)
) +
ylim(0, 0.8)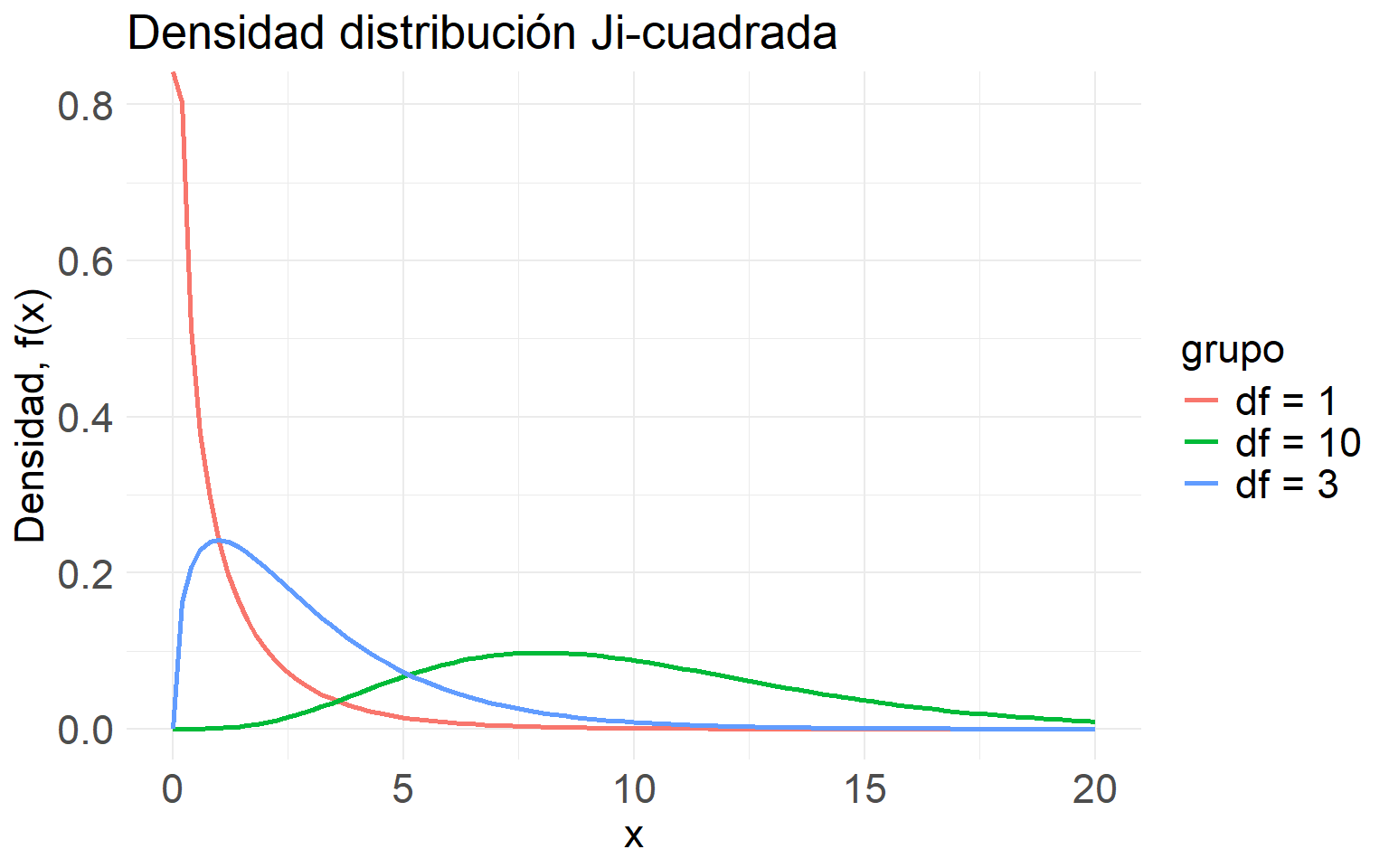
Código
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import chi2
from scipy.stats import ncx2
# Generar datos
x = np.linspace(0, 20, 100)
df = pd.DataFrame({
'x': np.tile(x, 3),
'densidad': np.concatenate([
chi2.pdf(x, df=1),
chi2.pdf(x, df=3),
chi2.pdf(x, df=10)
]),
'grupo': np.repeat(['df = 1', 'df = 3', 'df = 10'], 100)
})
# Crear primer gráfico
plt.figure(figsize=(10, 6))
for label, df_group in df.groupby('grupo'):
plt.plot(df_group['x'], df_group['densidad'], label=label)
plt.title('Densidad distribución Ji-cuadrada', fontsize=20)
plt.xlabel('x', fontsize=17)
plt.ylabel('Densidad, f(x)', fontsize=17)
plt.legend(title='Grupo', fontsize=17, title_fontsize=17)
plt.grid(True)
plt.show()
# Generar datos para distribuciones con loc
df_nc = pd.DataFrame({
'x': np.tile(x, 3),
'densidad': np.concatenate([
ncx2.pdf(x, df=3, nc=1),
ncx2.pdf(x, df=3, nc=3),
ncx2.pdf(x, df=3, nc=10)
]),
'grupo': np.repeat(['nc = 1', 'nc = 3', 'nc = 10'], 100)
})
# Crear segundo gráfico
plt.figure(figsize=(10, 6))
for label, df_group in df_nc.groupby('grupo'):
plt.plot(df_group['x'], df_group['densidad'], label=label)
#plt.ylim(0, 0.8) # Establecer el límite del eje y
plt.title('Densidad Chi-cuadrado Desplazadas (df= 3)', fontsize=20)
plt.xlabel('x', fontsize=16)
plt.ylabel('Densidad, f(x)', fontsize=16)
plt.legend(title='Grupo', fontsize=16, title_fontsize=16)
plt.grid(True)
plt.show()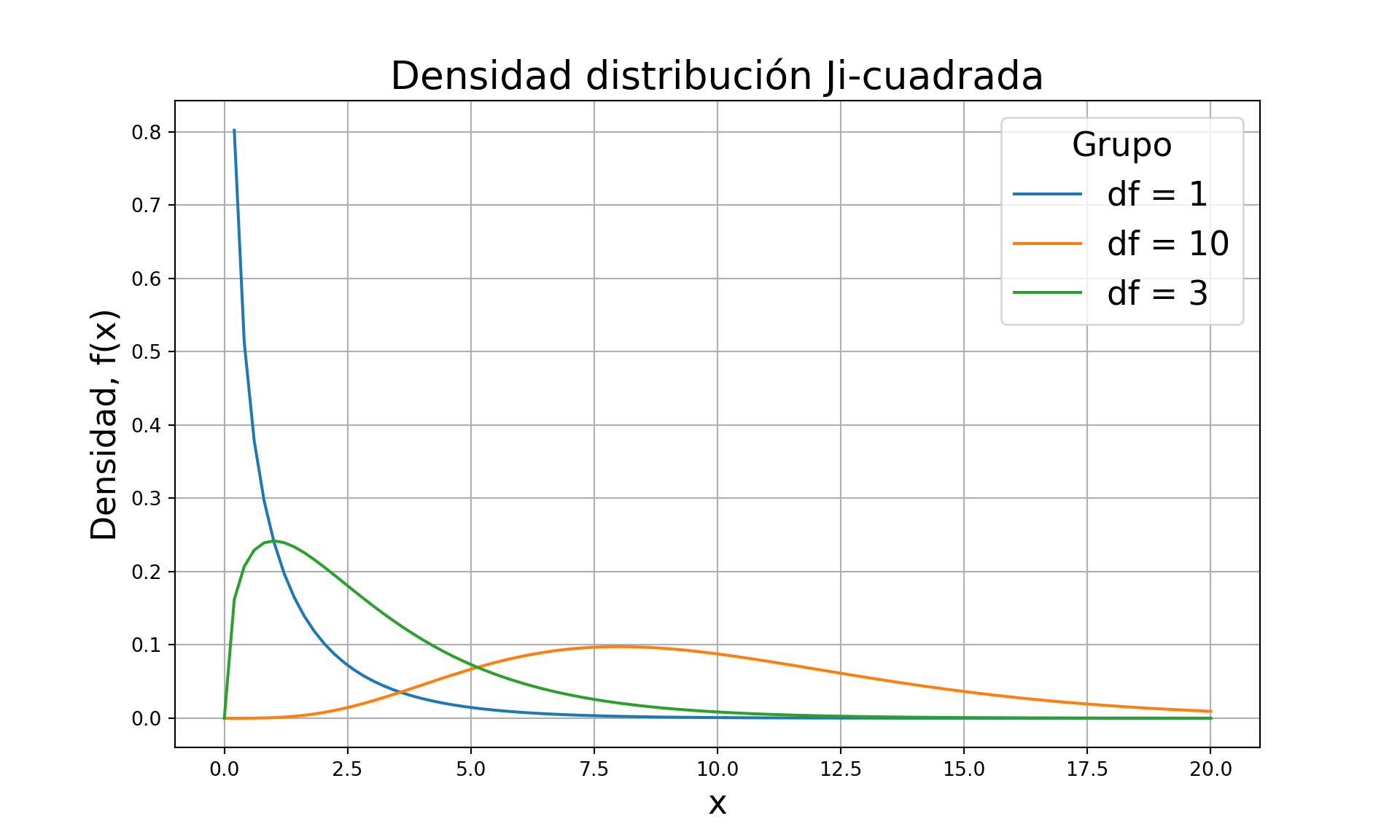
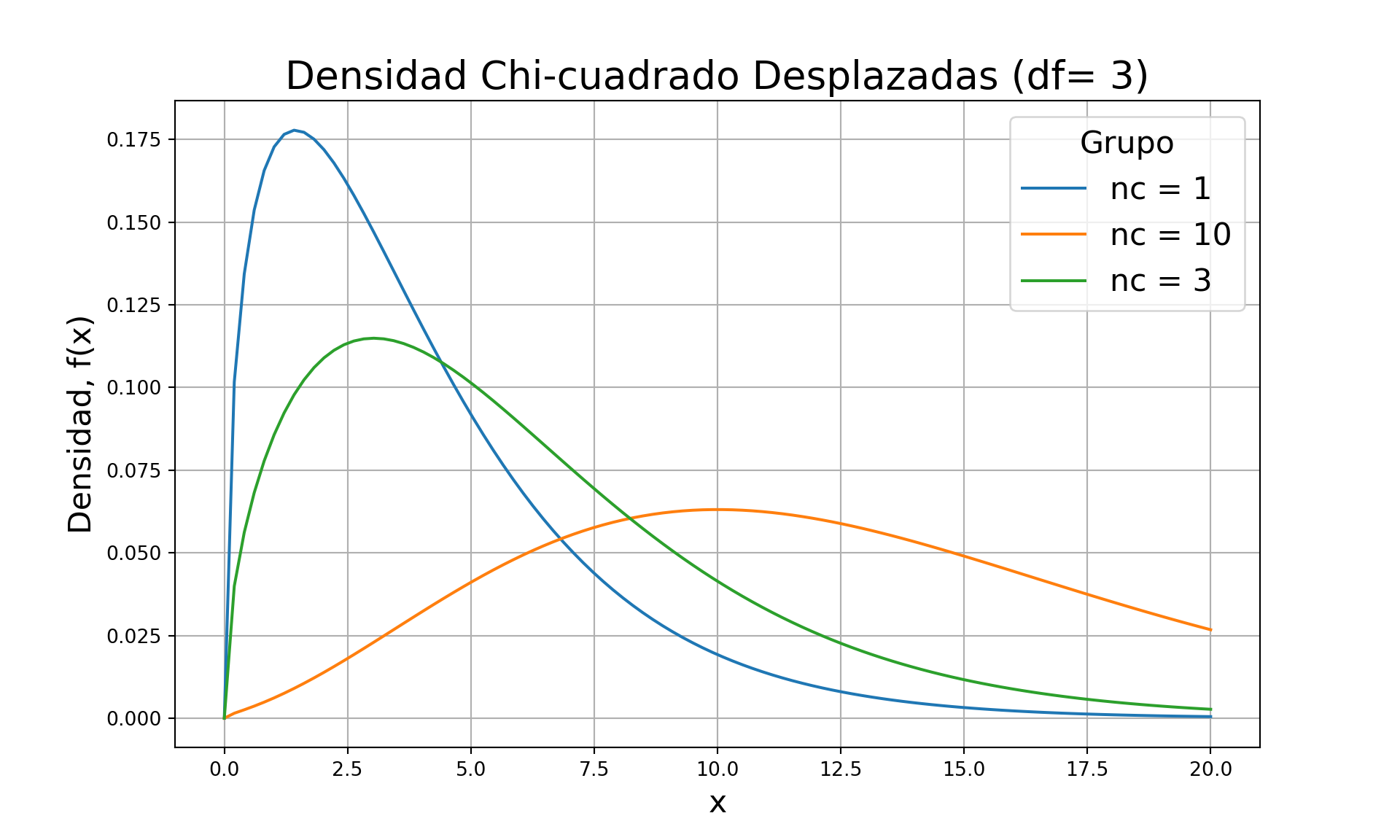
D.2 Distribución \(t\) de Student
Definición D.3 (\(t\) de Student) La v.a. \(X\) tiene distribución \(t\) de Student ssi tiene fd \[ f_X(x)=\frac{\Gamma[(k+1) / 2]}{\sqrt{k \pi}\ \Gamma(k / 2)} \left(1+\frac{x^2}{k}\right)^{-(k+1)/2}I_{\mathbb{R}}(x), \quad k>0. \]
La distribución \(t\) de Student que se puede derivar de la razón de una v.a. Normal Estándar y una función de una v.a Ji cuadrada.
Teorema D.5 Si \(Z\sim N(0,1)\), \(U\sim \chi^2(k)\) y \(Z\) y \(U\) independientes, entonces \[ X:=\frac{Z}{\sqrt{U / k}} \sim t(k) \]
La distribución \(t\) de Student con un grado de libertad \(k=1\) corresponde a la distribución Cauchy con parámetro de localización 0.
Se puede demostrar que si \(X\sim t(k)\) tends to be a Standard Normal distribution as \(k\rightarrow \infty\). En términos prácticos, para \(k\geq 30\) ambas distribuciones son tan similares que las diferencias para producir intervalos o pruebas de hipótesis son despreciables.
D.2.1 No centrada
Definición D.4 (\(t\) de Student no centrada) Sea \(X \sim N(\mu, 1)\) y \(Y \sim \chi^2(n)\) con \(X\) y \(Y\) independientes. Entonces \[ W=\frac{X}{\sqrt{Y / n}} \] tiene una distribución \(t\) de Student no centrada, con \(n\) grados de libertad y parametro de localización \(\mu\). Esto lo denotamos como \(W \sim t(n, \mu)\). Si \(\mu=0\), decimos que la distribución es centrada.
El percentil \(\alpha \times 100 \%\) de esta distribución centrada y no centrada, lo denotamos como \(t(\alpha; n)\) y \(t(\alpha; n, \mu)\), respectivamente.
Código
library(ggplot2)
# Generar datos
df_t <- data.frame(
x = rep(seq(-5, 5, length.out = 100), 3),
densidad = c(
dt(seq(-5, 5, length.out = 100), df = 1),
dt(seq(-5, 5, length.out = 100), df = 3),
dt(seq(-5, 5, length.out = 100), df = 10)
),
grupo = factor(rep(c("df = 1", "df = 3", "df = 10"), each = 100))
)
# Crear el primer gráfico
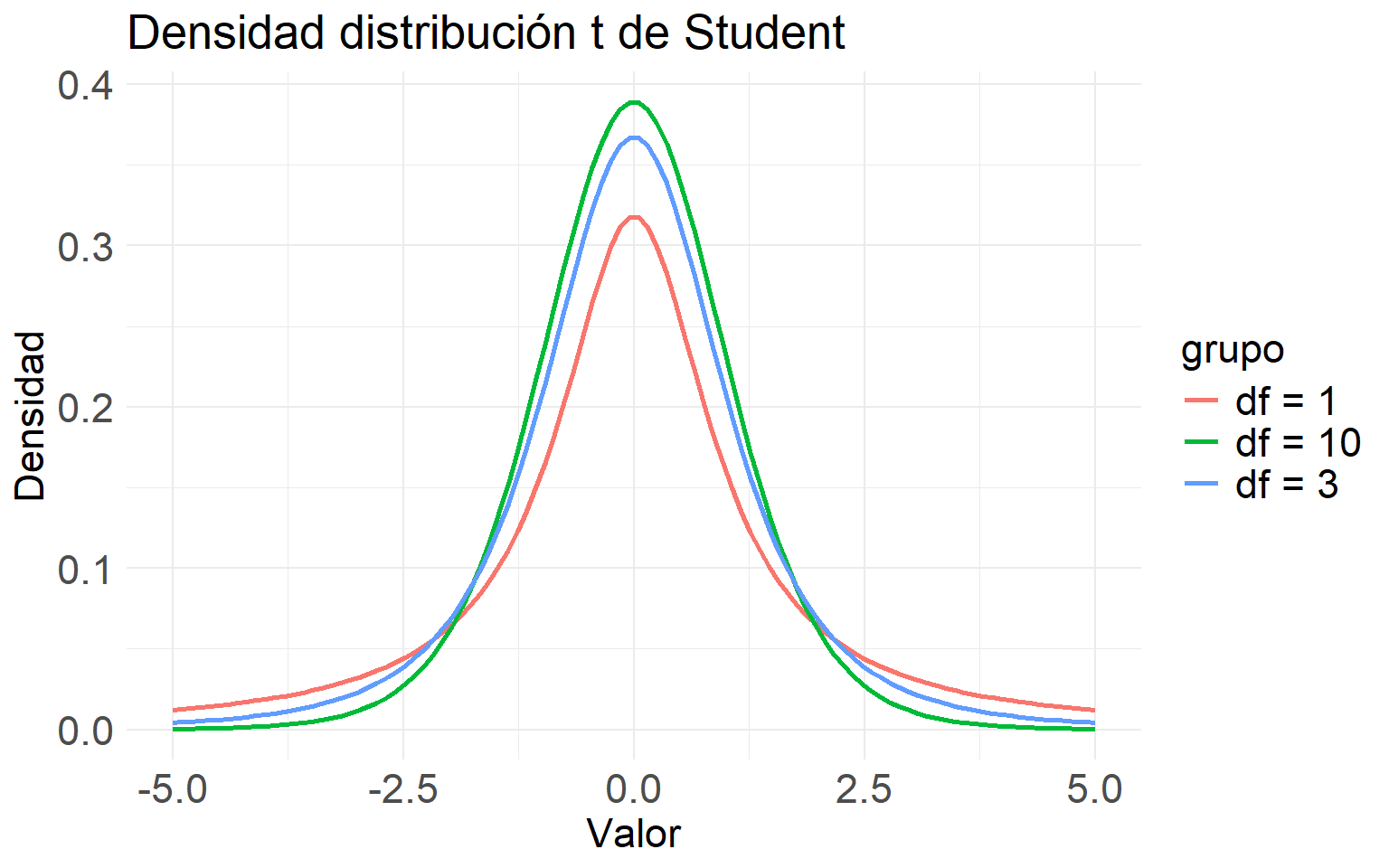
ggplot(df_t, aes(x = x, y = densidad, color = grupo)) +
geom_line(size = 1) +
labs(title = "Densidad distribución t de Student",
x = "Valor",
y = "Densidad") +
theme_minimal() +
theme(
plot.title = element_text(size = 20),
axis.title = element_text(size = 17),
axis.text = element_text(size = 17),
legend.title = element_text(size = 17),
legend.text = element_text(size = 17)
)
# Generar datos
df_t_nc <- data.frame(
x = rep(seq(-5, 15, length.out = 100), 3),
densidad = c(
dt(seq(-5, 25, length.out = 100), df = 3, ncp=1),
dt(seq(-5, 25, length.out = 100), df = 3, ncp=3),
dt(seq(-5, 25, length.out = 100), df = 3, ncp=10)
),
grupo = factor(rep(c("df = 1", "df = 3", "df = 10"), each = 100))
)
# Crear el segundo gráfico
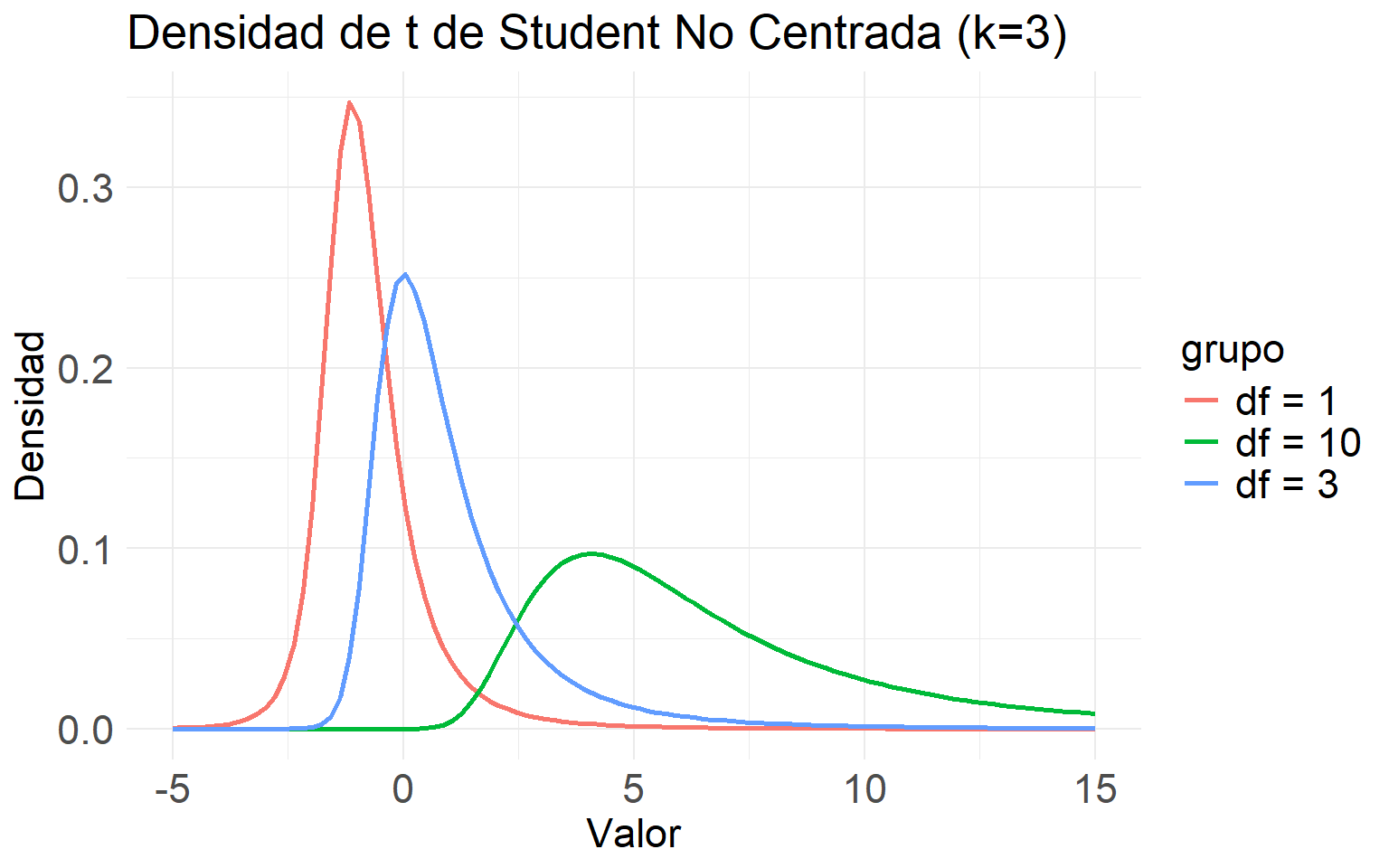
ggplot(df_t_nc, aes(x = x, y = densidad, color = grupo)) +
geom_line(size = 1) +
labs(title = "Densidad de t de Student No Centrada (k=3)",
x = "Valor",
y = "Densidad") +
theme_minimal() +
theme(
plot.title = element_text(size = 20),
axis.title = element_text(size = 17),
axis.text = element_text(size = 17),
legend.title = element_text(size = 17),
legend.text = element_text(size = 17)
)
Código
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import t
from scipy.stats import nct
# Generar datos para la distribución t de Student
x = np.linspace(-5, 5, 100)
df = pd.DataFrame({
'x': np.tile(x, 3),
'densidad': np.concatenate([
t.pdf(x, df=1),
t.pdf(x, df=3),
t.pdf(x, df=10)
]),
'grupo': np.repeat(['df = 1', 'df = 3', 'df = 10'], 100)
})
# Crear el primer gráfico
plt.figure(figsize=(10, 6))
for label, df_group in df.groupby('grupo'):
plt.plot(df_group['x'], df_group['densidad'], label=label)
plt.title('Densidad distribución t de Student', fontsize=20)
plt.xlabel('Valor', fontsize=17)
plt.ylabel('Densidad', fontsize=17)
plt.legend(title='Grupo', fontsize=17, title_fontsize=17)
plt.grid(True)
plt.show()
# Generar datos para la distribución t de Student con loc
x_nc = np.linspace(-5, 15, 100)
df_nc = pd.DataFrame({
'x': np.tile(x_nc, 3),
'densidad': np.concatenate([
nct.pdf(x_nc, df=3, nc=1),
nct.pdf(x_nc, df=3, nc=3),
nct.pdf(x_nc, df=3, nc=10)
]),
'grupo': np.repeat(['nc = 1', 'nc = 3', 'nc = 10'], 100)
})
# Crear el segundo gráfico
plt.figure(figsize=(10, 6))
for label, df_group in df_nc.groupby('grupo'):
plt.plot(df_group['x'], df_group['densidad'], label=label)
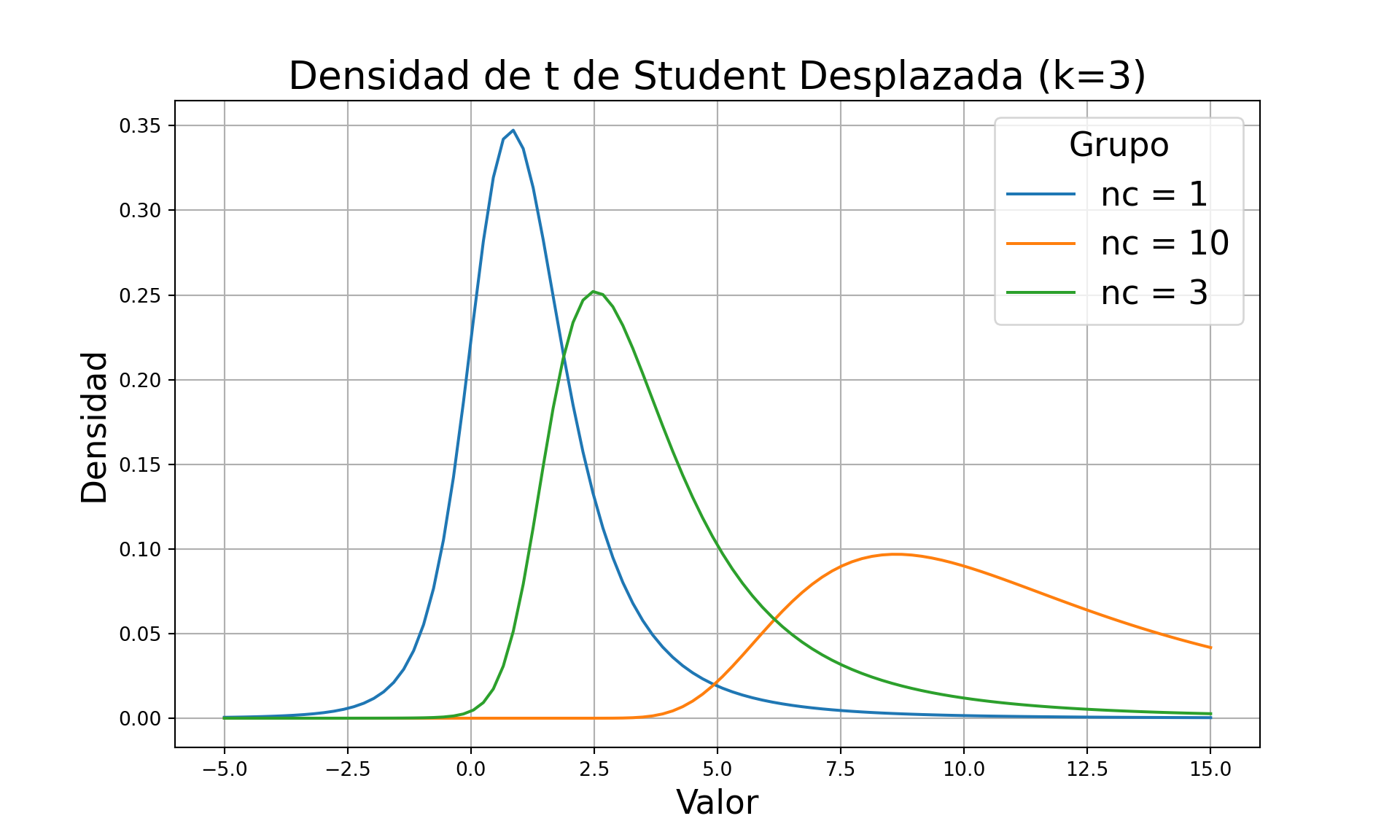
plt.title('Densidad de t de Student Desplazada (k=3)', fontsize=20)
plt.xlabel('Valor', fontsize=17)
plt.ylabel('Densidad', fontsize=17)
plt.legend(title='Grupo', fontsize=17, title_fontsize=17)
plt.grid(True)
plt.show()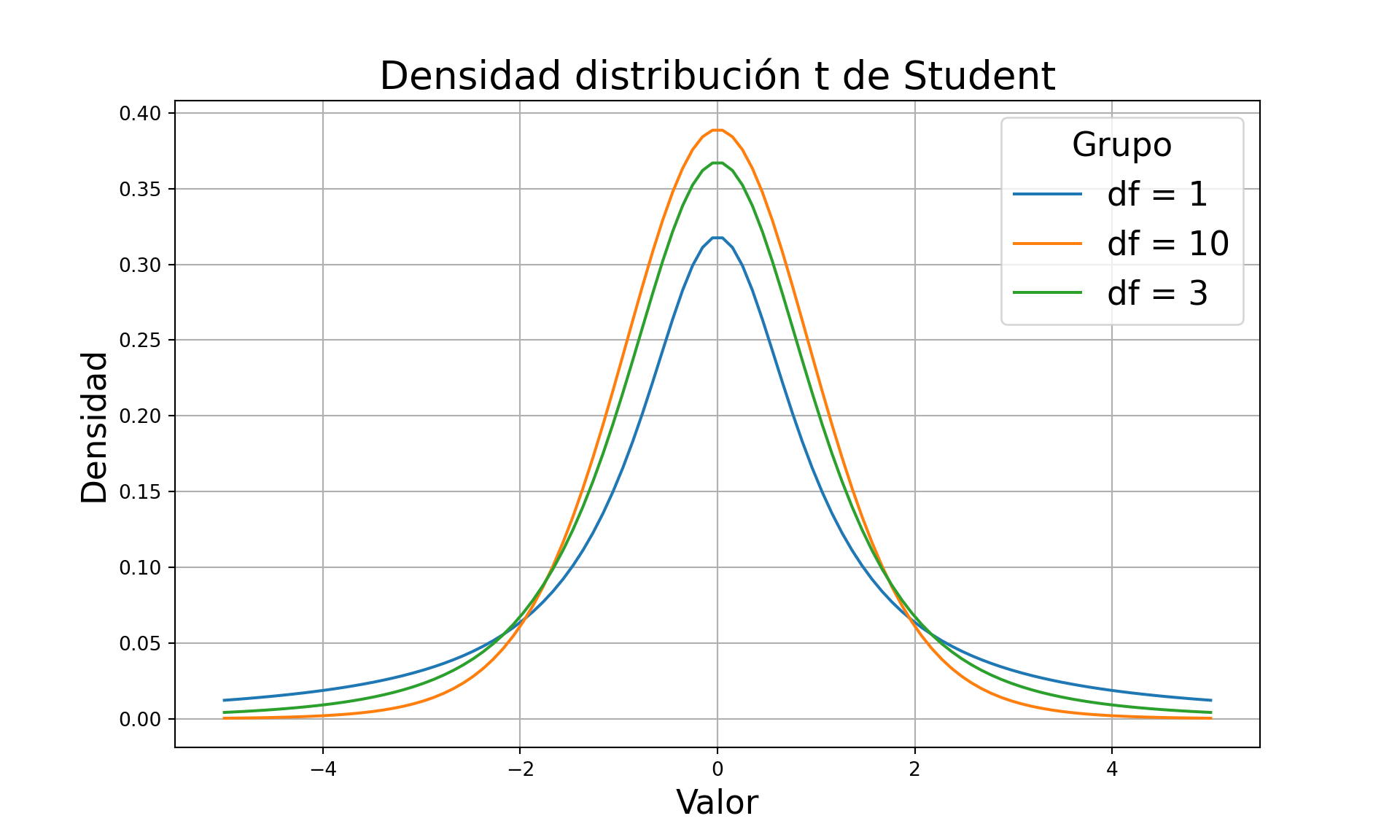
D.3 Distribución \(F\) de Fisher
Definición D.5 (\(F\) de Fisher) La v.a. \(X\) tiene distribución \(F\) de Fisher con parámetros \((m,n)\) ssi tiene fd \[ f_X(x)=\frac{\Gamma[(m+n) / 2]}{\Gamma(m / 2) \Gamma(n / 2)}\left(\frac{m}{n}\right)^{m / 2} \frac{x^{(m-2) / 2}}{[1+(m / n) x]^{(m+n) / 2}} I_{(0, \infty)}(x), \quad m, n>0. \]
Teorema D.6 Si \(U\) y \(V\) son v.a.independientes y \(U\sim \chi^2(m)\), \(U\sim \chi^2(n)\), entonces \[ X:=\frac{U/m}{V/n}\sim F(m,n). \]
Corolario D.1 Sea \(X_1, \ldots, X_{m}\) es una m.a. de una población con distribución \(N(\mu_X,\sigma^2)\) y sea \(Y_1, \ldots, Y_{n}\) una m.a. de una población \(N(\mu_Y,\sigma^2)\). Si las dos muestras son independientes entonces
\[
\frac{1}{\sigma^2} \sum_1^{m}\left(X_i-\overline{X}\right)^2 \sim \chi^2(m-1)\ \ \ \ \ \text{ y } \ \ \ \ \
\frac{1}{\sigma^2} \sum_1^{n}\left(Y_i-\overline{Y}\right)^2 \sim \chi^2(n-1).
\]
Así, el estadístico \[ \frac{\sum\left(X_i-\bar{X}\right)^2 / (m-1)}{\sum\left(Y_j-\bar{Y}\right)^2 / (n-1)}\sim F(m-1,n-1). \]
D.3.1 No centrada
D.3.1.1 \(t\) de Student no centrada
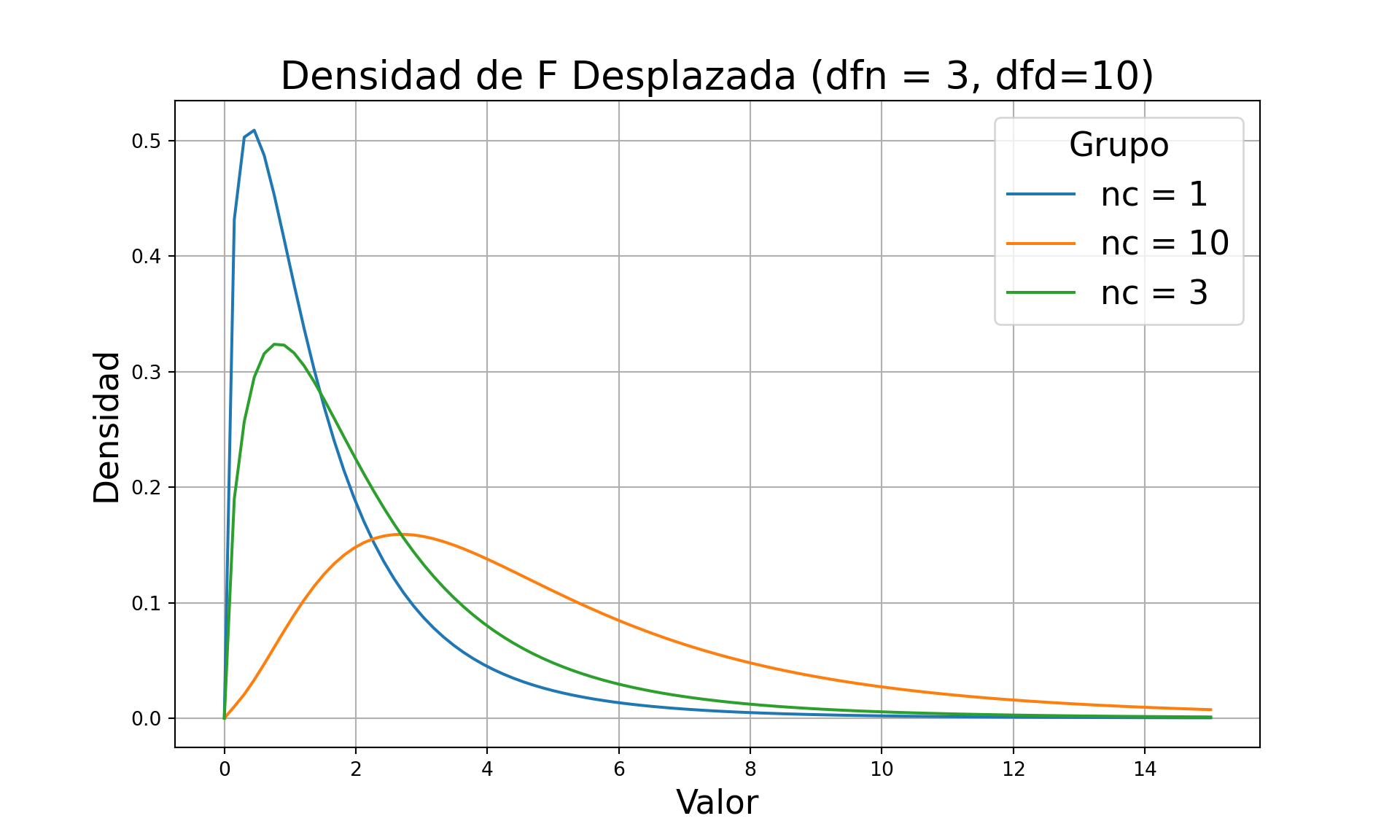
Sea \(X \sim \chi^2(r, \gamma)\) y \(Y \sim \chi^2(s, 0)\) con \(X\) y \(Y\) independientes. Entonces \[ W=\frac{X / r}{Y / s} \] se dice que tiene distribución \(F\) no centrada, con grados de libertad numerador \(r\), denominador \(s\), y parametro de no centralidad \(\gamma\). Denotamos esta distribución como \(W \sim F(r, s, \gamma)\). Si \(\gamma=0\), usamos la notación previamente introducida, \(W \sim F(r, s)\).
D.3.2 Percentil
El percentil \(\alpha \times 100 \%\) de \(F(r, s)\) lo denotamos como \(F(\alpha; r, s)\).
Código
library(ggplot2)
# Generar datos
xval<-seq(0, 6, length.out = 100)
df_f <- data.frame(
x = rep(xval, 5),
densidad = c(
df(xval, df1 = 1, df2=3),
df(xval, df1 = 3, df2=3),
df(xval, df1 = 10, df2=3),
df(xval, df1 = 3, df2=1),
df(xval, df1 = 3, df2=10)
),
grupo = factor(rep(c("df1=1 ,df2=3", "df1=3 ,df2=3", "df1=10,df2=3", "df1=3 ,df2=1","df1=3 ,df2=10"), each = 100))
)
# Crear el primer gráfico
ggplot(df_f, aes(x = x, y = densidad, color = grupo)) +
geom_line(size = 1) +
labs(title = "Densidad t de Student(3,10)",
x = "Valor",
y = "Densidad") +
theme_minimal() +
theme(
plot.title = element_text(size = 20),
axis.title = element_text(size = 17),
axis.text = element_text(size = 17),
legend.title = element_text(size = 17),
legend.text = element_text(size = 17)
)
# Generar datos
xval<-seq(0, 6, length.out = 100)
df_f_nc <- data.frame(
x = rep(xval, 3),
densidad = c(
df(xval, df1 = 3, df2=10, nc=1),
df(xval, df1 = 3, df2=10, nc=3),
df(xval, df1 = 3, df2=10, nc=10)
),
grupo = factor(rep(c("nc=1", "nc=3", "nc=10"), each = 100))
)
# Crear el segundo gráfico
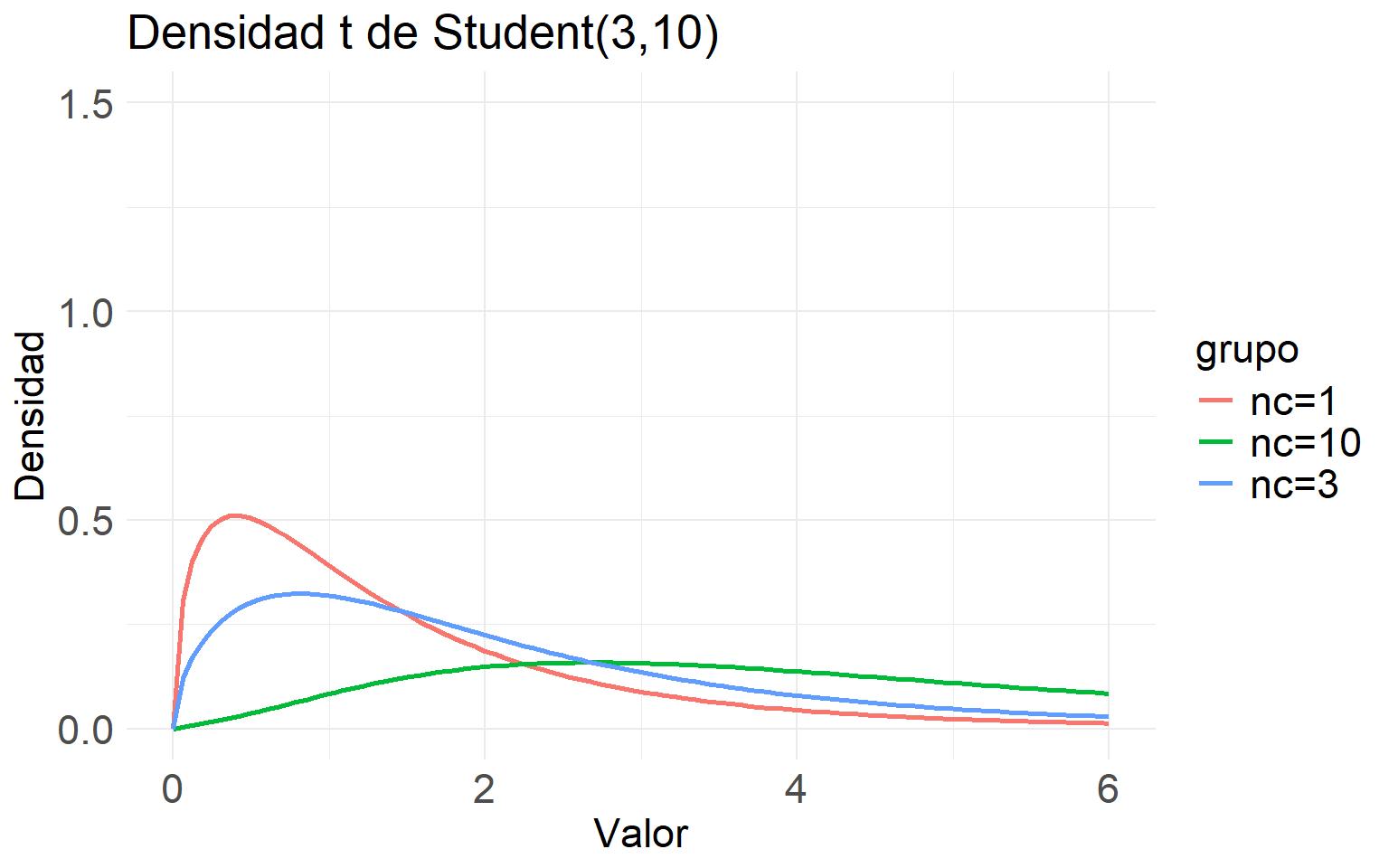
ggplot(df_f_nc, aes(x = x, y = densidad, color = grupo)) +
geom_line(size = 1) +
labs(title = "Densidad t de Student(3,10)",
x = "Valor",
y = "Densidad") +
theme_minimal() +
theme(
plot.title = element_text(size = 20),
axis.title = element_text(size = 17),
axis.text = element_text(size = 17),
legend.title = element_text(size = 17),
legend.text = element_text(size = 17)
)+ylim(0, 1.5) # Establecer el límite del eje y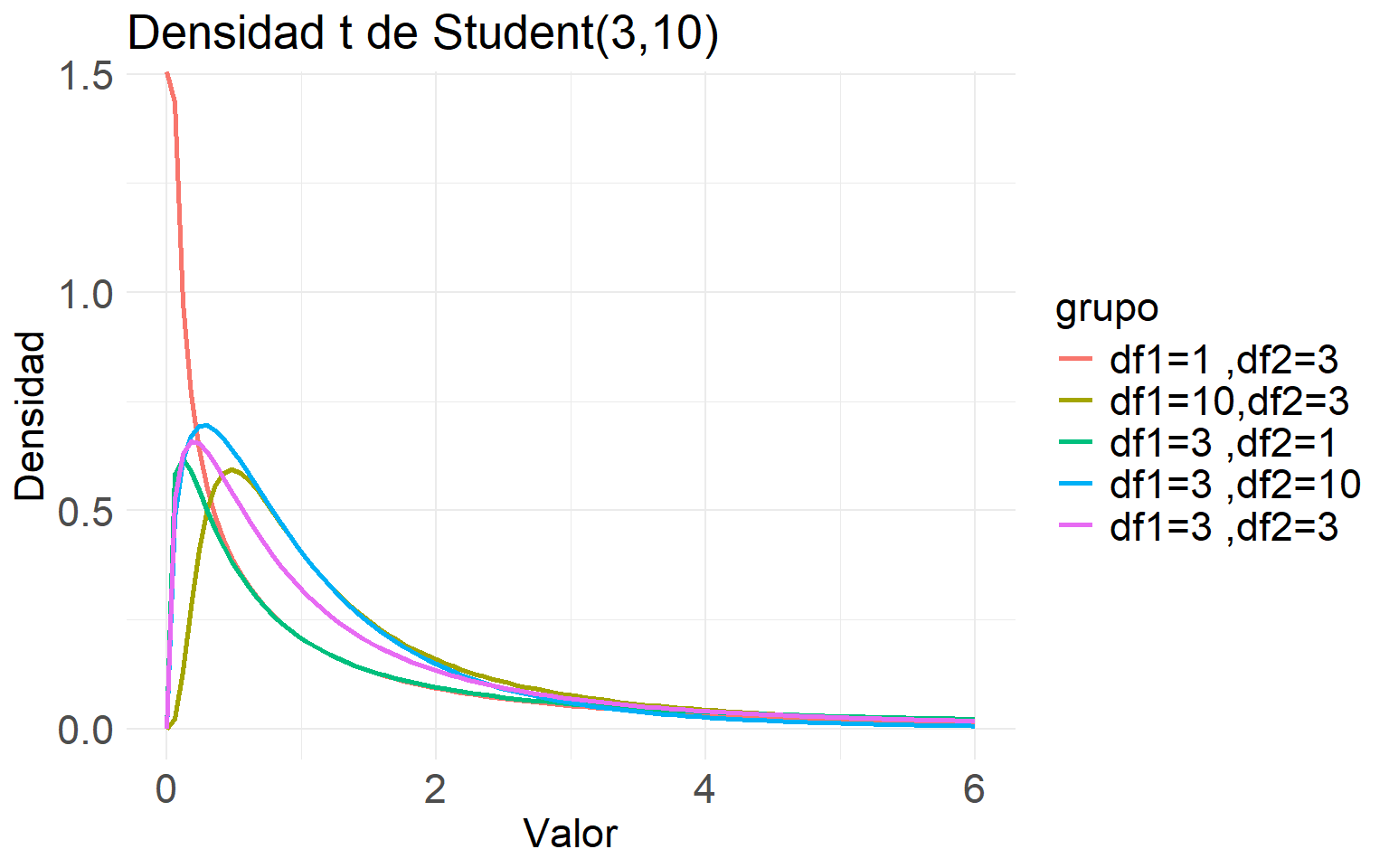
Código
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import f
from scipy.stats import ncf
# Generar datos para la distribución t de Student
xval = np.linspace(0, 6, 100)
df = pd.DataFrame({
'x': np.tile(x, 5),
'densidad': np.concatenate([
f.pdf(xval, dfn = 1, dfd=3),
f.pdf(xval, dfn = 3, dfd=3),
f.pdf(xval, dfn = 10, dfd=3),
f.pdf(xval, dfn = 3, dfd=1),
f.pdf(xval, dfn = 3, dfd=10)
]),
'grupo': np.repeat(['df1=1 ,df2=3', 'df1=3 ,df2=3', 'df1=10,df2=3', 'df1=3 ,df2=1','df1=3 ,df2=10'], 100)
})
# Crear el primer gráfico
plt.figure(figsize=(10, 6))
for label, df_group in df.groupby('grupo'):
plt.plot(df_group['x'], df_group['densidad'], label=label)
plt.title('Densidad distribución t de Student', fontsize=20)
plt.xlabel('Valor', fontsize=17)
plt.ylabel('Densidad', fontsize=17)
plt.legend(title='Grupo', fontsize=17, title_fontsize=17)
plt.grid(True)
plt.show()
# Generar datos para la distribución t de Student con loc
x_nc = np.linspace(0, 15, 100)
df_nc = pd.DataFrame({
'x': np.tile(x_nc, 3),
'densidad': np.concatenate([
ncf.pdf(x_nc, dfn = 3, dfd=10, nc=1),
ncf.pdf(x_nc, dfn = 3, dfd=10, nc=3),
ncf.pdf(x_nc, dfn = 3, dfd=10, nc=10)
]),
'grupo': np.repeat(['nc = 1', 'nc = 3', 'nc = 10'], 100)
})
# Crear el segundo gráfico
plt.figure(figsize=(10, 6))
for label, df_group in df_nc.groupby('grupo'):
plt.plot(df_group['x'], df_group['densidad'], label=label)
plt.title('Densidad de F Desplazada (dfn = 3, dfd=10)', fontsize=20)
plt.xlabel('Valor', fontsize=17)
plt.ylabel('Densidad', fontsize=17)
plt.legend(title='Grupo', fontsize=17, title_fontsize=17)
plt.grid(True)
plt.show()