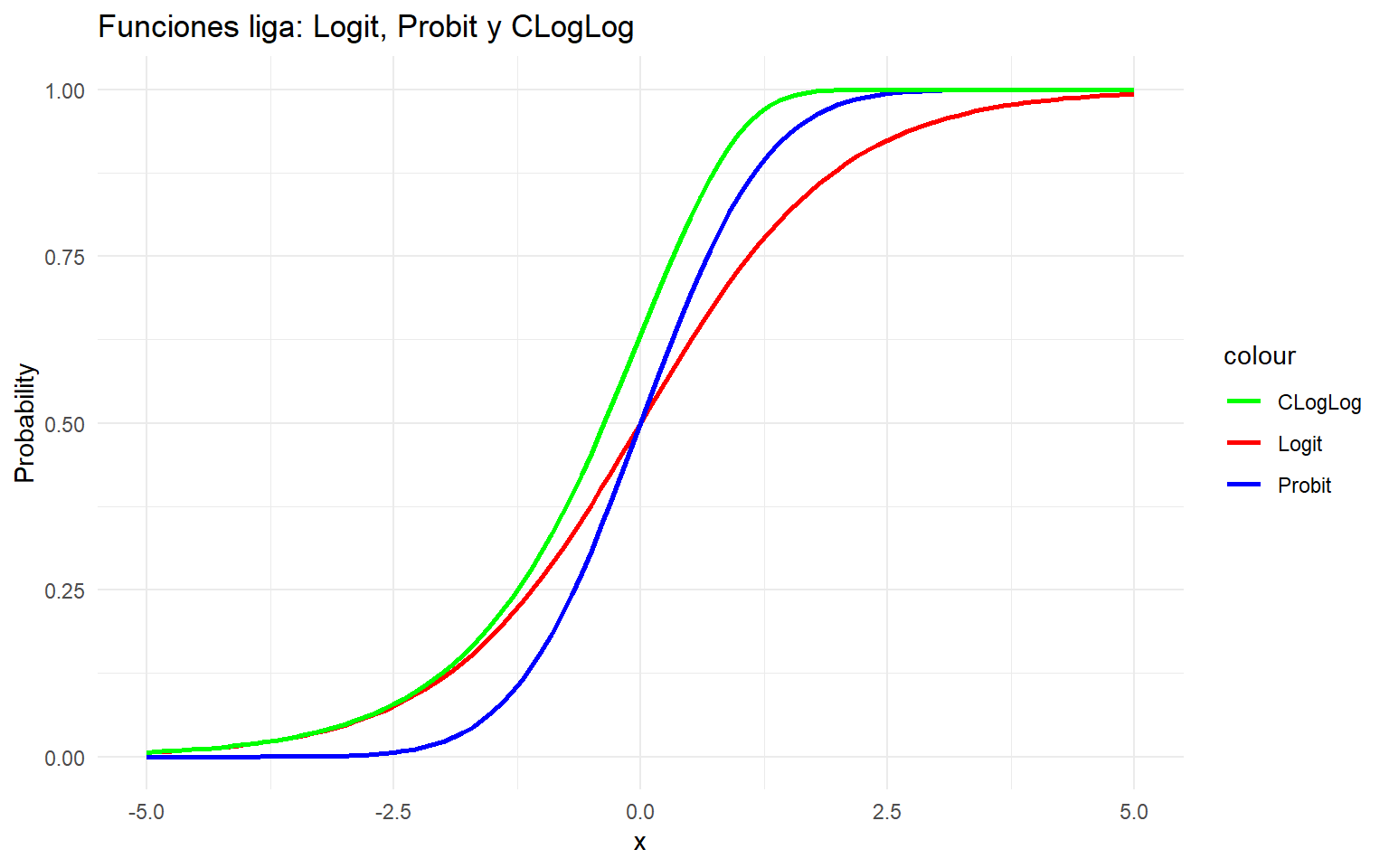
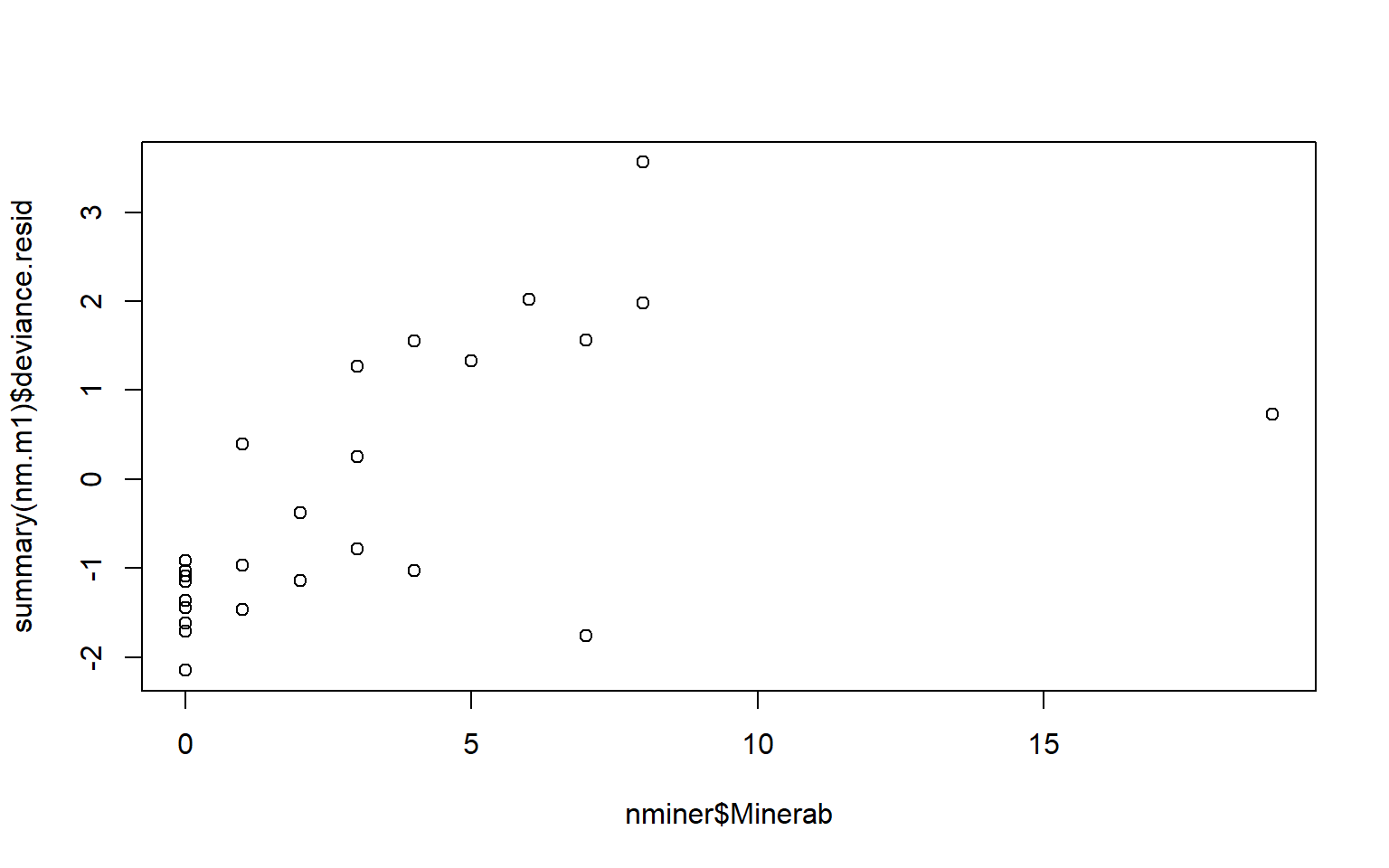
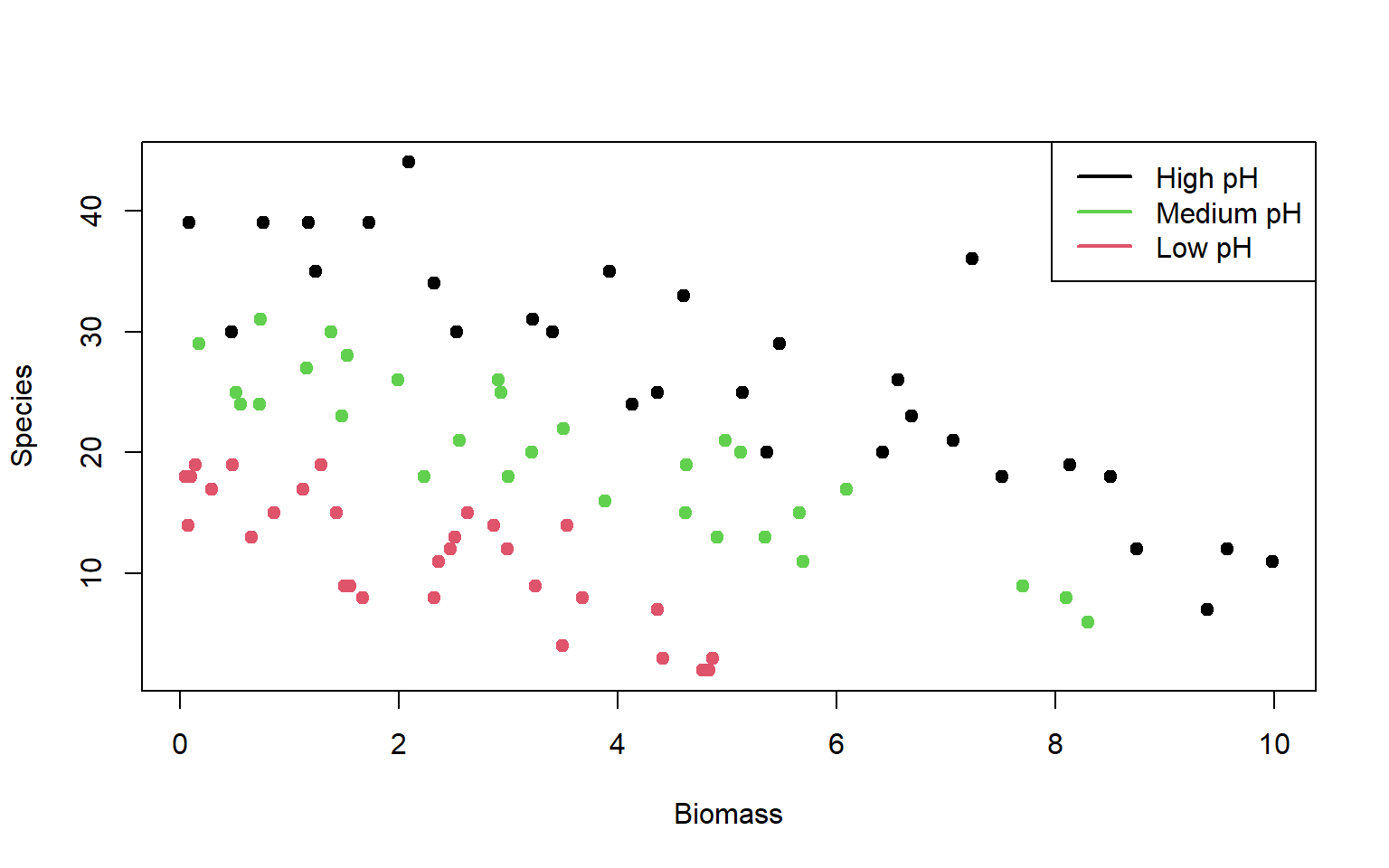
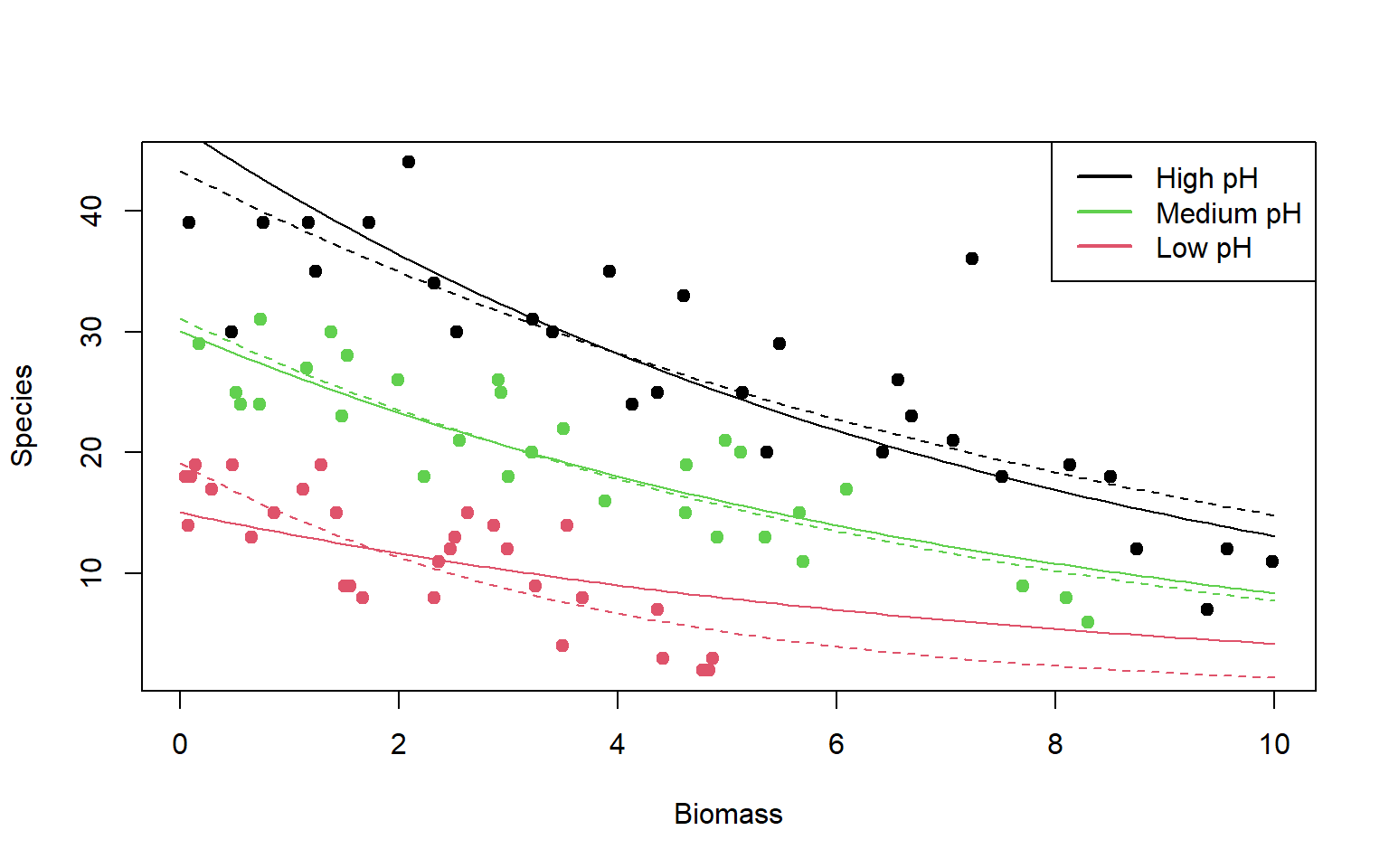
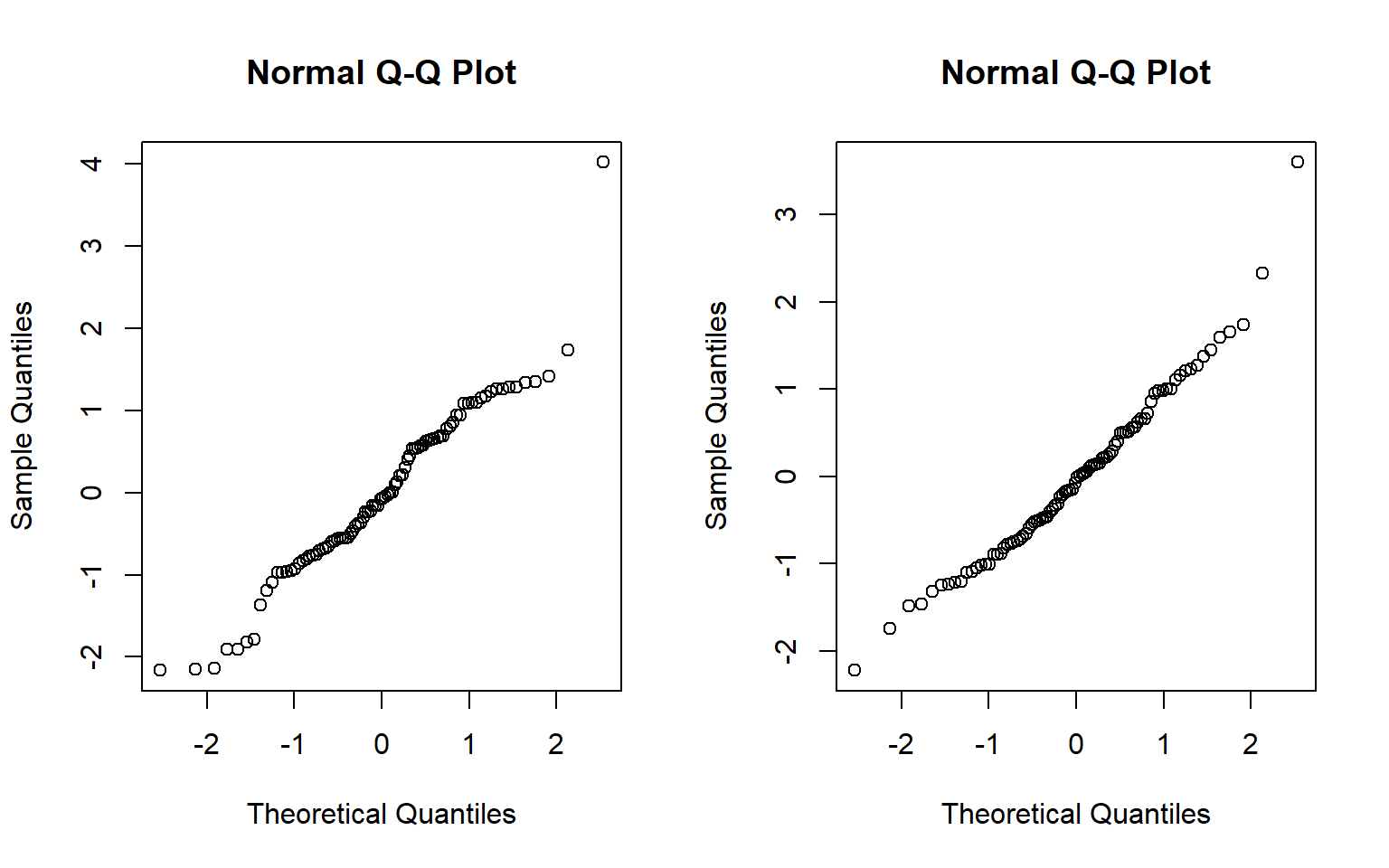
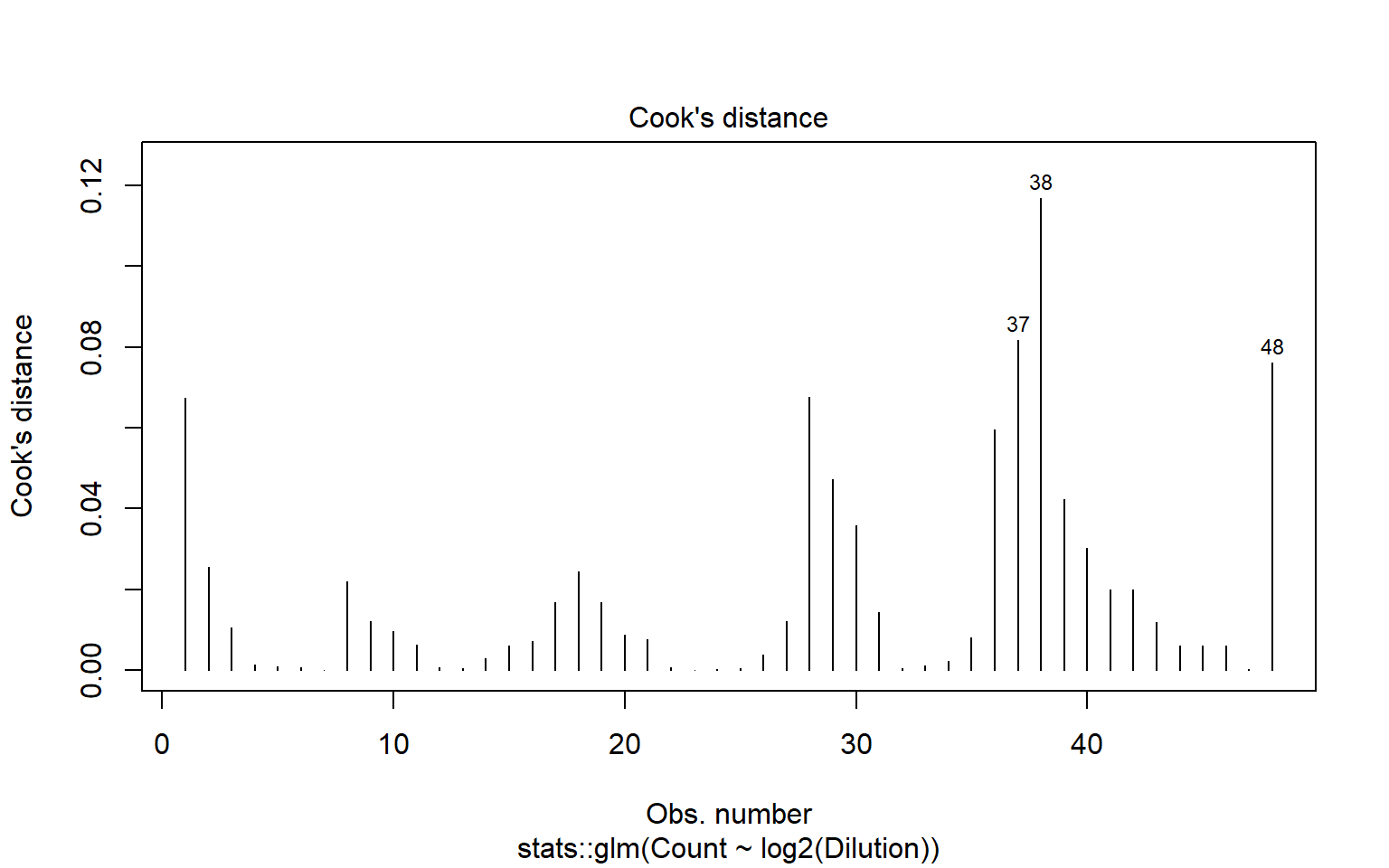
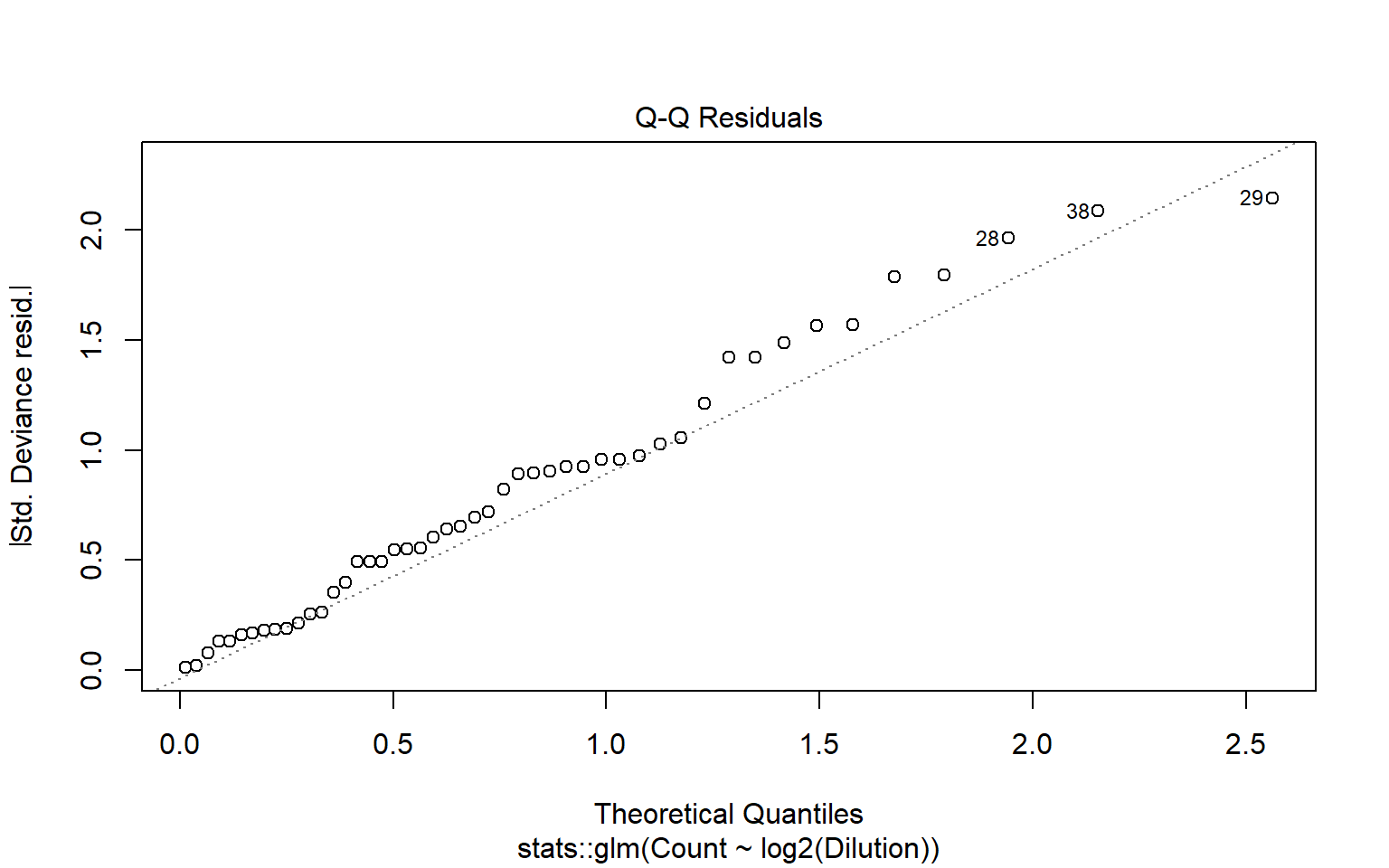
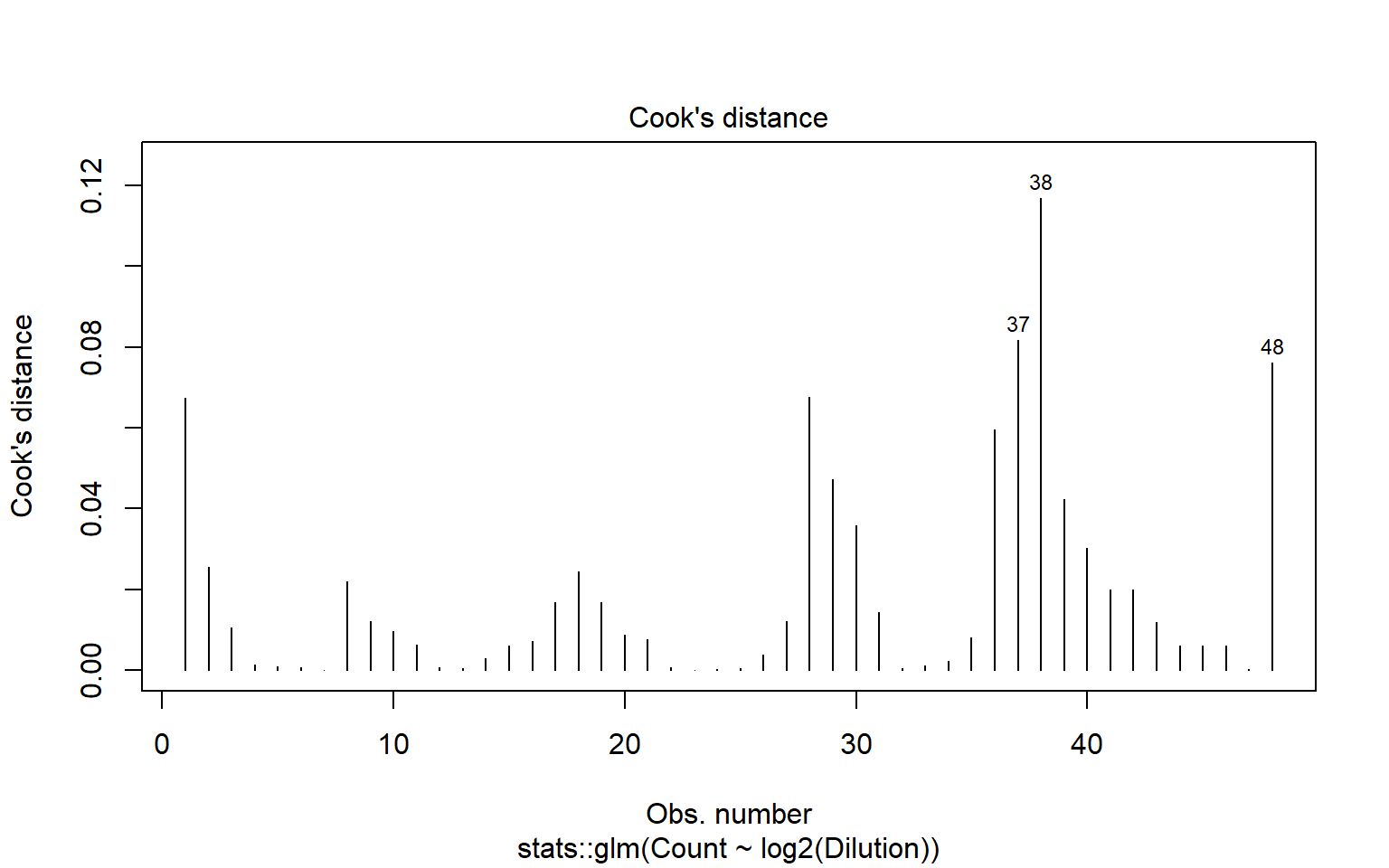
edad <- c(
20, 23, 24, 25, 25, 26, 26, 28, 28, 29, 30, 30, 30, 30, 30, 30, 32, 32, 33, 33,
34, 34, 34, 34, 34, 35, 35, 36, 36, 36, 37, 37, 37, 38, 38, 39, 39, 40, 40, 41,
41, 42, 42, 42, 42, 43, 43, 43, 44, 44, 44, 44, 45, 45, 46, 46, 47, 47, 47, 48,
48, 48, 49, 49, 49, 50, 50, 51, 52, 52, 53, 53, 54, 55, 55, 55, 56, 56, 56, 57,
57, 57, 57, 57, 57, 58, 58, 58, 59, 59, 60, 60, 61, 62, 62, 63, 64, 64, 65, 69)
coro <- c(
0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,1,0,0,0,0,0,1,0,0,1,0,0,0,0,1,0,1,0,
0,0,0,0,1,0,0,1,0,0,1,1,0,1,0,1,0,0,1,0,1,1,0,0,1,0,1,0,0,1,1,1,1,0,1,1,1,1,1,0,
0,1,1,1,1,0,1,1,1,1,0,1,1,1,1,1,0,1,1,1)
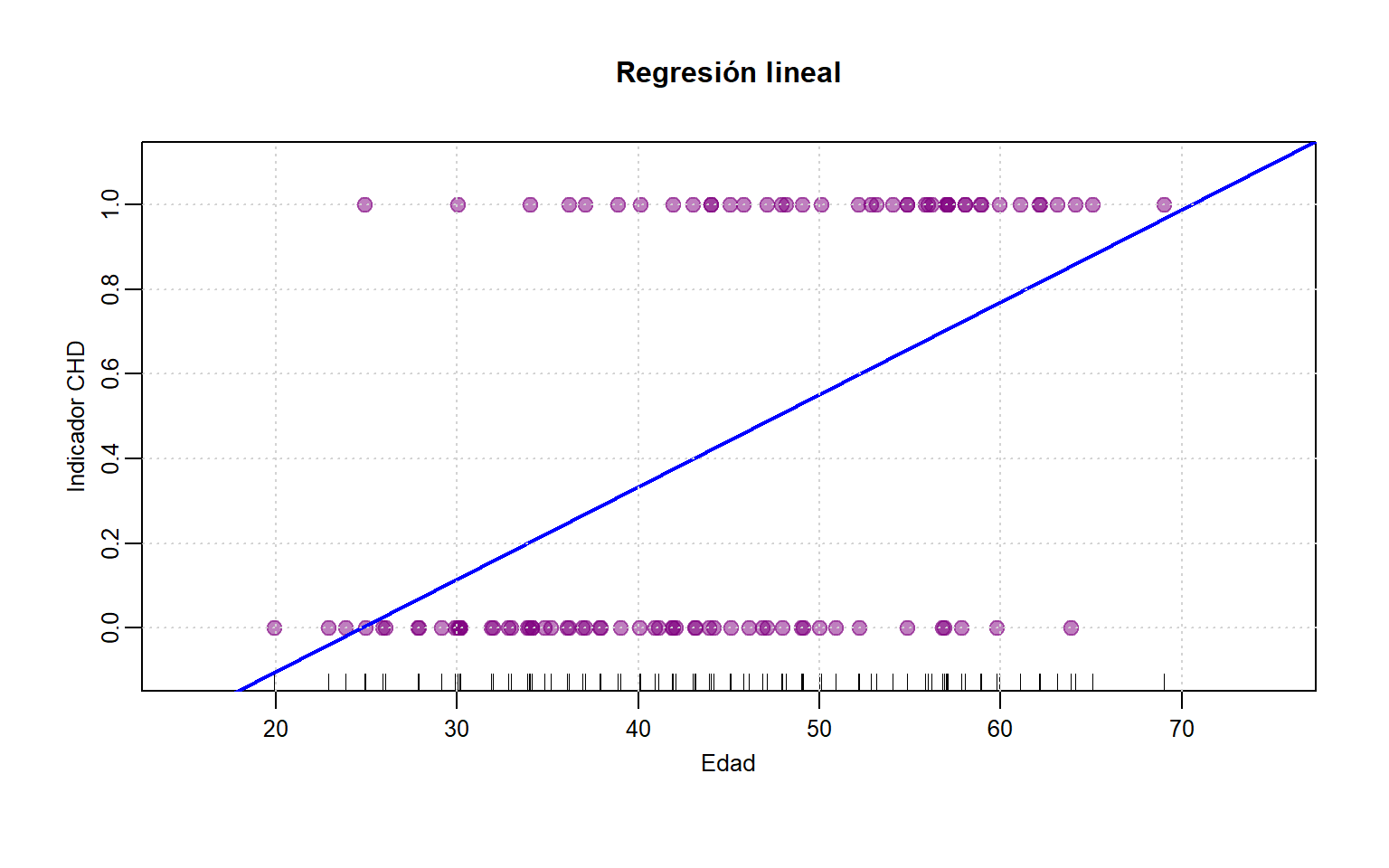
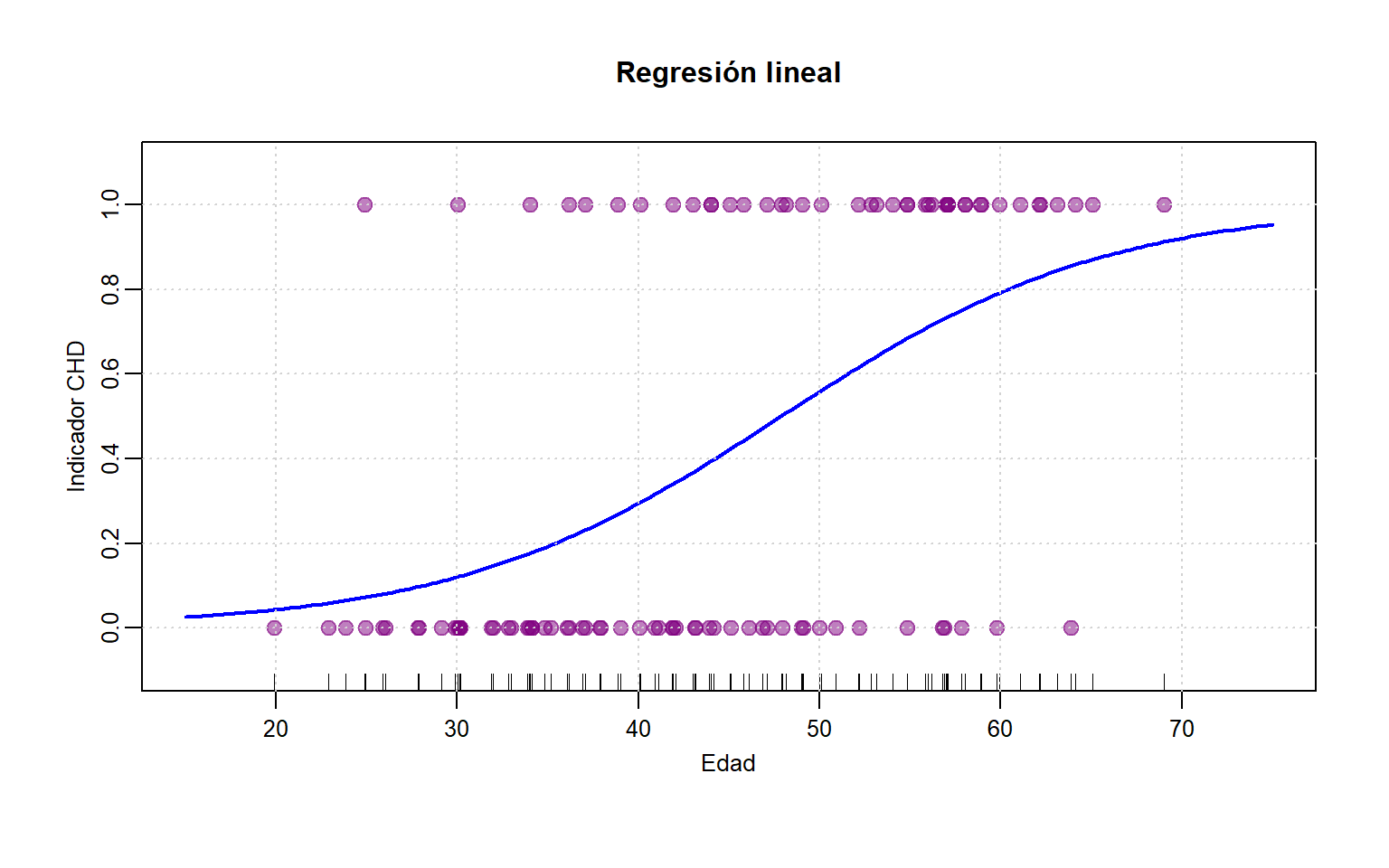
# Gráfica de los datos
edaj <- jitter(edad) # solo con fines de graficación
plot(edaj, coro, xlab="Edad", ylab="Indicador CHD", ylim=c(-.1, 1.1),
mgp=c(1.5,.5,0), cex.axis=.8, cex.lab=.8, cex.main=1, xlim=c(15,75), cex=1.2,
main="Regresión lineal", pch=19,col=rgb(.5,0,.5,.5))
rug(edaj)
out <- lm(coro ~ edad)
abline(out,lwd=2,col="blue")
grid()