Hasta ahora hemos supuesto que tenemos una muy buena idea de la forma básica del modelo y que conocemos todos (o casi todos) los regresores que deberían utilizarse.
La estrategia hasta ahora ha sido:
Ajustar el modelo completo (el modelo con todos los regresores).
Realizar un análisis exhaustivo de este modelo, incluyendo un análisis completo de los residuales.
Determinar si hay algún problema de multicolinearidad y modificar el modelo.
Determinar si son necesarias transformaciones de la variable respuesta o de algunos de los regresores.
Utilizar las pruebas de hipótesis para modificar el modelo por algunas covariables no significativas.
Realizar un análisis exhaustivo del modelo modificado, especialmente un análisis de residuales, para determinar la adecuación del modelo.
En el problema de pruebas de hipótesis y multicolinearidad hemos abordado el problema de selección y covariables (o su modificación), pero en problemas prácticos hay una gran cantidad de covariables candidatas para incluirse en el modelo. Encontrar el subconjunto apropiado de covariables es un problema que puede ser de alta dimensionalidad y se conoce comúnmente como el problema de selección del modelo.
Los métodos para realizar una buena selección de modelo es muy importante pero algunos existentes no garantizan la eliminación de la multicolinearidad de las covariables incluidas. Sin embargo el uso de buenas técnicas de selección de modelo aumenta la confianza en los resultados que se puedan obtener del modelo seleccionado.
Construir un modelo de regresión que incluya solo un subconjunto de los regresores disponibles implica dos objetivos conflictivos:
Por un lado, se busca incluir la mayor cantidad de regresores posible para que la información contenida en estos factores pueda influir en el valor de la variable de interés \(Y\).
Por otro lado, se desea incluir la menor cantidad de regresores posible, ya que la varianza de la predicción \(\hat{Y}\) aumenta con el número de regresores. Además, cuantos más regresores tenga un modelo, mayores serán los costos de recopilación de datos y mantenimiento del modelo.
El proceso de encontrar un modelo que logre un equilibrio entre estos dos objetivos se denomina selección de la ‘mejor’ ecuación de regresión. Sin embargo, no existe una definición única de ‘mejor’.
Hay varios algoritmos disponibles para la selección de variables, y estos métodos a menudo identifican diferentes subconjuntos de regresores candidatos como los ‘mejores’.
Los criterios de selección de variables son muy comunes en la práctica estadística y científica, especialmente en proyectos que implican análisis predictivos o explicativos. El uso de herramientas como AIC y BIC es estándar en software como R y Python. En entornos académicos y profesionales, los métodos stepwise son frecuentemente utilizados debido a su facilidad de implementación, aunque tienen algunas críticas sobre su estabilidad y generalización. En problemas más complejos, se utilizan métodos más modernos como el LASSO (Least Absolute Shrinkage and Selection Operator) para la selección de variables.
4.1 Criterios para la selección de subconjuntos
Los criterios para la selección de variables en modelos de regresión son herramientas matemáticas y estadísticas diseñadas para evaluar y comparar diferentes combinaciones de variables dentro de un modelo. Su propósito principal es ayudar a identificar el conjunto de variables regresoras (covariables) que mejor explican la relación entre ellas y la variable de interés, mientras se evita el exceso de complejidad.
Estos criterios se basan en métricas estadísticas que consideran el ajuste del modelo, la penalización por la complejidad (número de variables), y otras características relacionadas con la precisión y la interpretabilidad.
Algunos de los más importantes son:
\(R^2\) y \(R^2\) ajustado,
AIC,
BIC,
pruebas \(F\) parciales,
FIVs.
Además de que estos criterios simplifican el modelo, hemos abordado ya el último, con el fin de mitigar el problema de multicolinearidad.
El plantear un modelo parsimonioso puede mejorar la interpretabilidad de las relaciones entre variables y pueden reducir los costos de recolección de datos y la complejidad coputacional sin sacrificar demasiado la precisión de resultados.
4.1.1\(R^2\) y \(R^2\) ajustado,
Estos coeficientes también se conocen como coeficientes de determinación múltiple y los hemos abordado ya en Sección 1.6.3.2 .
En particular, \(R_p^2\) es el coeficiente de determinación múltiple para un modelo de regresión de subconjuntos con \(p\) términos, es decir, \(k=p-1\) regresores y un término de intersección \(\beta_0\). Formalmente, \[
R_p^2 = \frac{\text{SS}_{\mathrm{R}}(p)}{\text{SS}_{\mathrm{T}}} = 1 - \frac{\text{SS}_{\mathrm{Res}}(p)}{\text{SS}_{\mathrm{T}}},
\] donde \(\text{SS}_{\mathrm{R}}(p)\) representa la suma de cuadrados explicada por el modelo, mientras que \(\text{SS}_{\mathrm{Res}}(p)\) es la suma de cuadrados residuales, ambas para un modelo con \(p\) términos.
Si \(K\) es el total de covariables disponibles, es importante destacar que existen \(\binom{K}{p-1}\) posibles valores de \(R_p^2\) para cada valor de \(p\), uno por cada subconjunto de tamaño \(p\).
El coeficiente \(R_p^2\) aumenta conforme se incrementa \(p\), alcanzando su valor máximo cuando \(p = K + 1\). Por ello, el analista utiliza este criterio añadiendo regresores al modelo hasta el punto en el que una variable adicional no aporte un aumento significativo en \(R_p^2\). Normalmente, se ajustan modelos con diferentes \(p\)’s para identificar el “codo” en la curva como el punto óptimo para determinar el número adecuado de regresores.
Como hemos comentado antes, un problema de \(R^2\) es que siempre incrementa con \(p\) por lo que no siempre es muy claro cuando el aporte del aumento es significativo. El coeficiente \(R^2_{\text {Ajus.}}\) trata de resolver este problema penalizando la complejidad del modelo: \[
R_{\mathrm{Ajus.}}^2=1-\frac{\text{SS}_{\mathrm{Res}} /(n-p)}{\text{SS}_{\mathrm{T}} /(n-1)}.
\] El valor \(R^2_{\mathrm{Ajus.}}\) es siempre menor que \(R^2\), e incluso puede ser negativo.
4.1.2 AIC
Akaike propuso un criterio de información, el AIC, basado en maximizar la entropía esperada del modelo, construida en la medida de información de Kullback-Leibler. Esencialmente, el AIC es una medida de verosimilitud logarítmica penalizada. El Criterio de Información de Akaike (AIC) se define como: \[
\mathrm{AIC} = 2p - 2\log\left[L(\widehat{\boldsymbol{\beta}},\widehat{\sigma}^2)\right]
\] donde \(p\) representa el número de parámetros del modelo, y \(L(\widehat{\boldsymbol{\beta}},\widehat{\sigma}^2)\) es la función de verosimilitud evaluada en los EMVs. Los modelos “buenos” son aquellos que tienen un AIC pequeño, ya que esto indica un mejor balance entre la complejidad del modelo y su capacidad de ajuste.
Si \(\varepsilon_i\) son iid con distribución \(N(0, \sigma^2)\), la función de log verosimilitud para nuestro modelo es:
\[
\begin{aligned}
\log L(\beta, \sigma^2; X, \boldsymbol{Y}) &= -\frac{n}{2}\log(2\pi\sigma^2) - \frac{\left(\boldsymbol{Y} - X\boldsymbol{\beta}\right)^{\top}\left(\boldsymbol{Y} - X\boldsymbol{\beta}\right)}{2\sigma^2}.
\end{aligned}
\] como el EMV de \(\sigma^2\) es \[
\hat{\sigma}_{\mathrm{EMV}}^2= \frac{\left(\boldsymbol{Y} - X\widehat{\boldsymbol{\beta}}\right)^{\top}\left(\boldsymbol{Y} - X\widehat{\boldsymbol{\beta}}\right)}{n},
\] entonces \[
\begin{align}
\mathrm{AIC} & =2 p+2\left[\frac{n}{2} \log \left(2 \pi \hat{\sigma}_{\mathrm{EMV}}^2\right)+\frac{n\hat{\sigma}_{\mathrm{EMV}}^2}{2\hat{\sigma}_{\mathrm{EMV}}^2}\right] \\[2pt]
& = 2 p+n \log (2 \pi \hat{\sigma}_{\mathrm{EMV}}^2)+n \\[7pt]
& = 2 p+n \log \left(\frac{\text{SS}_{\mathrm{Res}}}{n}\right)+n + n \log (2 \pi)\\
& = 2 p+n \log \left(\frac{\text{SS}_{\mathrm{Res}}}{n}\right)+C,
\end{align}
\] donde \(C\) es una constante que solo depende del tamaño de la muestra pero no del modelo. Esta constante se ignora comúnmente, así que diferentes programas pueden reportar diferentes valores de AIC.
La idea clave del AIC es similar al \(R_{\mathrm{Ajus.}}^2\). A medida que agregamos regresores al modelo, \(\text{SS}_{\mathrm{Res}}\) no puede aumentar. La cuestión radica en si la disminución en \(\text{SS}_{\mathrm{Res}}\) justifica la inclusión de los términos adicionales.
NotaEjemplo
Código
#|autompg<-read.table("http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data", quote ="\"", comment.char ="", stringsAsFactors =FALSE)colnames(autompg)<-c("mpg", "cyl", "disp", "hp", "wt", "acc", "year", "origin", "name")autompg<-subset(autompg, autompg$hp!="?")autompg<-subset(autompg, autompg$name!="plymouth reliant")rownames(autompg)<-paste(autompg$cyl, "cylinder", autompg$year, autompg$name)autompg<-subset(autompg, select =c("mpg", "cyl", "disp", "hp", "wt", "acc", "year"))autompg$hp<-as.numeric(autompg$hp)model_list<-as.list(rep(0,5))model_list[[1]]<-lm(mpg~wt, data =autompg)model_list[[2]]<-lm(mpg~wt+year, data =autompg)model_list[[3]]<-lm(mpg~wt+year+cyl, data =autompg)model_list[[4]]<-lm(mpg~wt+year+cyl+hp, data =autompg)model_list[[5]]<-lm(mpg~wt+year+cyl+hp+acc, data =autompg)R2<-R2ajus<-aic<-c(0,0,0,0,0)for(iin1:5){R2[i]<-summary(model_list[[i]])$r.squaredR2ajus[i]<-summary(model_list[[i]])$adj.r.squaredaic[i]<-AIC(model_list[[i]])}par(mfrow=c(1,3))plot(R2,t="o",pch=19,main="R2")plot(R2ajus,t="o",pch=19, main="R2 Ajustada")plot(aic,t="o",pch=19, main="AIC")
Figura 4.1: Criterios para selección de modelo: \(R^2\), \(R^2_{Ajus.}\) y AIC
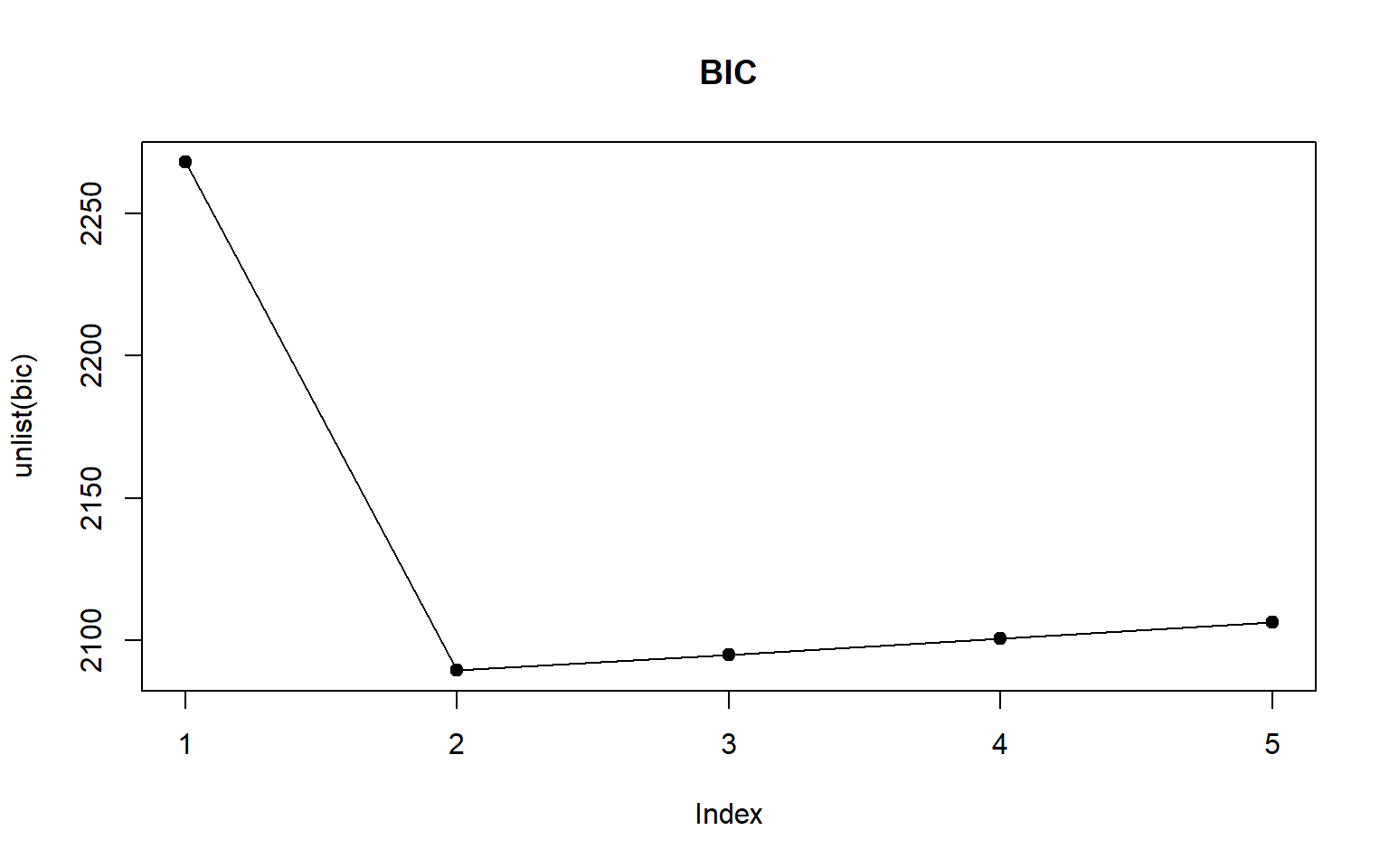
4.1.3 BIC
Bayesian information criterion (BIC) o Criterio de información de Schwarz (también conocido como SIC, SBC, SBIC) es un criterio para la selección de modelo entre un conjunto finito de ellos.
Fue desarrollado por Gideon E. Schwarz y publicado en un artículo de 1978 como una aproximación para muestras grandes al factor de Bayes.
Existen varias extensiones bayesianas del AIC. Schwartz (1978) y Sawa (1978) son dos de las más populares. Ambas se conocen como el criterio de información bayesiano (BIC). Por lo tanto, es importante revisar los detalles específicos del software estadístico que se utiliza.
El criterio de Schwartz \(\left(\mathrm{BIC}_{\text {Sch }}\right)\) se define como: \[
\mathrm{BIC}_{\mathrm{Sch}} = p \log(n) -2 \log(L(\widehat{\boldsymbol{\beta}},\widehat{\sigma}^2))
\]
Este criterio impone una penalización mayor a la inclusión de regresores conforme aumenta el tamaño de la muestra.
\[
\mathrm{BIC}_{\mathrm{Sch}} = p \log(n) + n \log \left(\frac{\text{SS}_{\mathrm{Res}}}{n}\right) +C.
\]
Como el AIC, aquellos modelos con valores pequeños de BIC son los preferidos.
Tanto el AIC como el BIC se utilizan con mayor frecuencia en los procedimientos de selección de modelos que implican situaciones más complejas en comparación con los mínimos cuadrados ordinarios.
Como el AIC, aquellos modelos con valores pequeños de BIC son los preferidos.
Evaluar todas las posibles regresiones puede ser computacionalmente costoso, se han desarrollado diversos métodos para analizar solo un número reducido de modelos de regresión de subconjuntos, ya sea añadiendo o eliminando regresores uno en cada paso de una iteración. Estos métodos fueron desarrollados originalmente como técnicas de selección de variables para modelos de regresión lineal.
Estos métods de selección se conocen generalmente como procedimientos del tipo de pasos (stepwise) y se clasifican en tres categorías principales:
selección hacia adelante,
eliminación hacia atrás, y
selección mixta o regresión stepwise, que es una combinación de 1 y 2.
A menudo, este procedimiento converge en un subconjunto de variables.
Los criterios de entrada y salida suelen basarse pruebas de hipótesis y en un umbral de valor \(p\). Un criterio típico de entrada es que el valor \(p\) debe ser menor a 0.15 para que una variable entre en el modelo, y mayor a 0.15 para que una variable salga del modelo.
El proceso comienza creando \(p\) modelos de regresión lineal, cada uno de los cuales utiliza exactamente una de las variables. Posteriormente, la importancia de las variables se clasifica según su capacidad individual para explicar la variación en el resultado.
4.2.1 Selección hacia adelante
Este procedimiento comienza con la suposición de que no hay covariables en el modelo, excepto el término de intersección.
El primer regresor seleccionado para entrar en la ecuación es aquel que tiene la mayor correlación con la variable \(y\). Supongamos que este regresor es \(x_1\). Este también será el regresor que producirá el valor más alto de la estadística \(F\) al probar la significancia de la regresión. Este regresor se incluye si la estadística \(F\) excede un valor \(F\) preseleccionado, denominado \(F_{\text{IN}}\) (o \(F\)-para-entrar).
El segundo regresor elegido para entrar en el modelo es aquel que ahora tiene la mayor correlación con \(y\) después de ajustar por el efecto del primer regresor incluido, \(\left(x_1\right)\). Estas correlaciones se denominan correlaciones parciales (ver Sección F.4 ). Son las correlaciones entre los residuales de la regresión \(\hat{y}=\hat{\beta}_0+\hat{\beta}_1 x_1\) y los residuales de las regresiones de los otros regresores candidatos sobre\(x_1\), como \(\hat{x}_j=\hat{\alpha}_{0 j}+\hat{\alpha}_{1 j} x_1\), con \(j=2,3,\ldots,K\). Entonces si \(x_2\) es el regresor con la más alta correlación parcial con \(y\) entonces el estadístico parcial \(F\) (ver Sección 1.6.5 ) más grande es \[
F_0=\frac{\text{SS}_{\mathrm{R}}\left(x_2 \mid x_1\right)}{\text{MS}_{\text {Res }}\left(x_1, x_2\right)}=\frac{\text{SS}_{\text {Res, Mod Reducido}}-\text{SS}_{\text {Res, Mod Completo}}/1}{\text{SS}_{\text {Res, Mod Completo }}/(n-3)}\sim F(1,n-3).
\] Si \(F_0 > F_{\text{IN}}\), añadimos a \(x_2\) al modelo (ya que \(H_0:\beta_{X_2}=0\)).
En general, en cada paso el regresor con la correlación parcial con \(y\) más grande se añade si su estad[istico parcial \(F\) es más grande que \(F_{\text{IN}}\). El procedmiento termina en cuanto la \(F\) considerada no es mayor a \(F_{\text{IN}}\) o cuando la última covariable candidata a ser añadida se ha aceptado.
NotaEjemplo: Selección con p valor
Código
library(olsrr)# Inicializamos el modelo con solamente interceptoPrimer_modelo<-lm(mpg~1, data =autompg)Todos_modelo<-lm(mpg~., data =autompg)# Forward stepwise regressionforward_fit<-ols_step_forward_p(Todos_modelo, penter=0.05)forward_fit
#>
#>
#> Stepwise Summary
#> ----------------------------------------------------------------------------
#> Step Variable AIC SBC SBIC R2 Adj. R2
#> ----------------------------------------------------------------------------
#> 0 Base Model 2713.548 2721.480 1603.866 0.00000 0.00000
#> 1 wt 2256.184 2268.083 1147.661 0.69206 0.69127
#> 2 year 2073.468 2089.333 966.770 0.80824 0.80724
#> ----------------------------------------------------------------------------
#>
#> Final Model Output
#> ------------------
#>
#> Model Summary
#> ----------------------------------------------------------------
#> R 0.899 RMSE 3.418
#> R-Squared 0.808 MSE 11.684
#> Adj. R-Squared 0.807 Coef. Var 14.652
#> Pred R-Squared 0.805 AIC 2073.468
#> MAE 2.612 SBC 2089.333
#> ----------------------------------------------------------------
#> RMSE: Root Mean Square Error
#> MSE: Mean Square Error
#> MAE: Mean Absolute Error
#> AIC: Akaike Information Criteria
#> SBC: Schwarz Bayesian Criteria
#>
#> ANOVA
#> -----------------------------------------------------------------------
#> Sum of
#> Squares DF Mean Square F Sig.
#> -----------------------------------------------------------------------
#> Regression 19205.026 2 9602.513 815.55 0.0000
#> Residual 4556.646 387 11.774
#> Total 23761.672 389
#> -----------------------------------------------------------------------
#>
#> Parameter Estimates
#> -------------------------------------------------------------------------------------------
#> model Beta Std. Error Std. Beta t Sig lower upper
#> -------------------------------------------------------------------------------------------
#> (Intercept) -14.638 4.023 -3.638 0.000 -22.548 -6.727
#> wt -0.007 0.000 -0.722 -30.881 0.000 -0.007 -0.006
#> year 0.761 0.050 0.358 15.312 0.000 0.664 0.859
#> -------------------------------------------------------------------------------------------
Otras opciones es basar la introducción paulatina de variables basados en otro de los criterios de selección como el AIC y BIC. En el siguiente ejemplo, la función step de R utiiza el AIC.
NotaEjemplo: Selección con AIC
Código
# Inicializamos el modelo con solamente interceptoPrimer_modelo<-lm(mpg~1, data =autompg)Todos_modelo<-lm(mpg~., data =autompg)# Forward stepwise regressionforward_model<-step(Primer_modelo, direction ="forward", scope =formula(Todos_modelo))
Como lo indica el nombre, la eliminación hacia atrás comienza desde un enfoque opuesto al de la selección hacia adelante.
En lugar de empezar con sin regresores, la eliminación hacia atrás parte de un modelo que incluye todos los \(K\) regresores candidatos. Luego, se calcula la estadística \(F\) parcial para cada regresor, como si fuera la última variable en entrar al modelo.
El valor más pequeño de estas estadísticas \(F\) parciales se compara con un valor preseleccionado, \(F_{\text{OUT}}\). Si este valor más pequeño es menor a \(F_{\text{OUT}}\), el regresor correspondiente se elimina del modelo.
A continuación, se ajusta un modelo con \(K-1\) regresores, se recalculan las estadísticas \(F\) parciales, y se repite el procedimiento.
El algoritmo de eliminación hacia atrás termina cuando el valor más pequeño de las estadísticas \(F\) parciales (o \(t\)) ya no es inferior al valor de corte preseleccionado \(F_{\text{OUT}}\) (o \(t_{\text{OUT}}\)).
La eliminación hacia atrás es frecuentemente vista como un buen procedimiento para la selección de variables. Es especialmente apreciada por analistas que prefieren incluir inicialmente todos los regresores candidatos para asegurarse de no pasar por alto algo “obvio”.
Cabe notar que los modelos resultantes de los modelos de selección hacia adelante y hacia atrás no necesiamente coincidirán.
NotaEjemplo: Selección con p valor
Código
library(olsrr)# Inicializamos modelo con todas los regresoresTodos_modelo<-lm(mpg~., data =autompg)# Forward stepwise regressionbackward_fit<-ols_step_backward_p(Todos_modelo, prem=0.05)backward_fit
#>
#>
#> Stepwise Summary
#> ---------------------------------------------------------------------------
#> Step Variable AIC SBC SBIC R2 Adj. R2
#> ---------------------------------------------------------------------------
#> 0 Full Model 2079.221 2110.950 972.704 0.80934 0.80635
#> 1 hp 2077.223 2104.986 970.670 0.80934 0.80685
#> ---------------------------------------------------------------------------
#>
#> Final Model Output
#> ------------------
#>
#> Model Summary
#> ----------------------------------------------------------------
#> R 0.900 RMSE 3.408
#> R-Squared 0.809 MSE 11.617
#> Adj. R-Squared 0.807 Coef. Var 14.667
#> Pred R-Squared 0.802 AIC 2077.223
#> MAE 2.621 SBC 2104.986
#> ----------------------------------------------------------------
#> RMSE: Root Mean Square Error
#> MSE: Mean Square Error
#> MAE: Mean Absolute Error
#> AIC: Akaike Information Criteria
#> SBC: Schwarz Bayesian Criteria
#>
#> ANOVA
#> -----------------------------------------------------------------------
#> Sum of
#> Squares DF Mean Square F Sig.
#> -----------------------------------------------------------------------
#> Regression 19231.179 5 3846.236 326.003 0.0000
#> Residual 4530.493 384 11.798
#> Total 23761.672 389
#> -----------------------------------------------------------------------
#>
#> Parameter Estimates
#> -------------------------------------------------------------------------------------------
#> model Beta Std. Error Std. Beta t Sig lower upper
#> -------------------------------------------------------------------------------------------
#> (Intercept) -14.815 4.171 -3.552 0.000 -23.015 -6.614
#> cyl -0.352 0.331 -0.077 -1.062 0.289 -1.003 0.299
#> disp 0.008 0.007 0.107 1.111 0.267 -0.006 0.022
#> wt -0.007 0.001 -0.741 -11.352 0.000 -0.008 -0.006
#> acc 0.084 0.079 0.030 1.056 0.292 -0.072 0.239
#> year 0.758 0.051 0.357 14.725 0.000 0.657 0.860
#> -------------------------------------------------------------------------------------------
NotaEjemplo: Selección con AIC
Código
# Inicializamos el modelo con solamente interceptoTodos_modelo<-lm(mpg~., data =autompg)# Eliminación hacia atrásbackward_model<-step(Todos_modelo, direction ="backward")
Los dos procedimientos mencionados sugieren diversas combinaciones posibles. La regresión stepwise es una modificación de la selección hacia adelante, donde en cada paso se reevalúan todos los regresores previamente incluidos en el modelo mediante sus estadísticas parciales \(F\). Un regresor que fue añadido en una etapa anterior puede volverse redundante debido a las relaciones entre él y otros regresores ahora presentes en la ecuación. Si la estadística parcial \(F\) para una variable es menor que \(F_{\text{OUT}}\) (o \(t_{\text{OUT}}\)), esa variable se elimina del modelo.
La regresión stepwise requiere dos valores de corte: uno para la inclusión de variables y otro para su eliminación. Algunos analistas prefieren usar el mismo valor para \(F_{\text{IN}}\) y \(F_{\text{OUT}}\), aunque esto no es obligatorio. Con frecuencia, se elige \(F_{\text{IN}}\) (o \(t_{\text{IN}}\)) mayor que \(F_{\text{OUT}}\) (o \(t_{\text{OUT}}\)), haciendo que sea relativamente más difícil añadir un regresor al modelo que eliminar uno.
NotaEjemplo: Selección con p valor
Código
library(olsrr)# Inicializamos modelo con todas los regresoresTodos_modelo<-lm(mpg~., data =autompg)# Forward stepwise regressionboth_fit<-ols_step_both_p(Todos_modelo, pent=0.05, prem=0.05)both_fit
#>
#>
#> Stepwise Summary
#> ----------------------------------------------------------------------------
#> Step Variable AIC SBC SBIC R2 Adj. R2
#> ----------------------------------------------------------------------------
#> 0 Base Model 2713.548 2721.480 1603.866 0.00000 0.00000
#> 1 wt (+) 2256.184 2268.083 1147.661 0.69206 0.69127
#> 2 year (+) 2073.468 2089.333 966.770 0.80824 0.80724
#> ----------------------------------------------------------------------------
#>
#> Final Model Output
#> ------------------
#>
#> Model Summary
#> ----------------------------------------------------------------
#> R 0.899 RMSE 3.418
#> R-Squared 0.808 MSE 11.684
#> Adj. R-Squared 0.807 Coef. Var 14.652
#> Pred R-Squared 0.805 AIC 2073.468
#> MAE 2.612 SBC 2089.333
#> ----------------------------------------------------------------
#> RMSE: Root Mean Square Error
#> MSE: Mean Square Error
#> MAE: Mean Absolute Error
#> AIC: Akaike Information Criteria
#> SBC: Schwarz Bayesian Criteria
#>
#> ANOVA
#> -----------------------------------------------------------------------
#> Sum of
#> Squares DF Mean Square F Sig.
#> -----------------------------------------------------------------------
#> Regression 19205.026 2 9602.513 815.55 0.0000
#> Residual 4556.646 387 11.774
#> Total 23761.672 389
#> -----------------------------------------------------------------------
#>
#> Parameter Estimates
#> -------------------------------------------------------------------------------------------
#> model Beta Std. Error Std. Beta t Sig lower upper
#> -------------------------------------------------------------------------------------------
#> (Intercept) -14.638 4.023 -3.638 0.000 -22.548 -6.727
#> wt -0.007 0.000 -0.722 -30.881 0.000 -0.007 -0.006
#> year 0.761 0.050 0.358 15.312 0.000 0.664 0.859
#> -------------------------------------------------------------------------------------------
NotaEjemplo: Selección con AIC
Código
# Inicializamos el modelo con solamente interceptoTodos_modelo<-lm(mpg~., data =autompg)# Eliminación hacia atrásboth_model<-step(Todos_modelo, direction ="both")
Una forma de resolver un problema de multicolinealidad consiste en identificar variables involucradas en dependencias y eliminar algunas de ellas. En ocasiones, puede no ser aceptable “desperdiciar’’ información, sobre todo si se ha invertido tiempo y esfuerzo en obtenerla. Una alternativa es usar Regresión Ridge el cual es un método de estimación que aminora los efectos de colinealidades.
La regresión Ridge (Tikhonov regularization) introduce un término de regularización que penaliza los valores grandes de los coeficientes, alentando coeficientes más pequeños y reduciendo la sensibilidad del modelo a las variables predictoras correlacionadas.
Esta regularización aporta varias ventajas:
Mayor estabilidad: Los coeficientes del modelo son menos propensos a sufrir grandes variaciones debido a la multicolinealidad. En este sentido la inferencia se vuelve más “robusta”.
Mejor interpretación: Los coeficientes ajustados tienden a ser más consistentes y comprensibles.
Mejor desempeño: El modelo puede ofrecer resultados más fiables, especialmente en presencia de variables predictoras altamente correlacionadas.
Proposición 4.1 (Regularización) Suponga que se tiene el problema de minimización siguiente \[
\min _{\boldsymbol{\beta} \in \mathbb{R}^p}\left\{\|\boldsymbol{Y}-X \boldsymbol{\beta}\|^2+\boldsymbol{\beta}^{\top} Q \boldsymbol{\beta}\right\}
\] en donde \(Q \in \mathbb{R}^{p \times p}\) es una matriz simétrica definida positiva. Esto es equivalente al problema de optimización convexa \[
\min _{\boldsymbol{\beta} \in \mathbb{R}^p}\left(\boldsymbol{Y}-X \boldsymbol{\beta}\right)^{\top}\left(\boldsymbol{Y}-X \boldsymbol{\beta}\right) \qquad \text{sujeto a }\ \boldsymbol{\beta}^{\top} Q \boldsymbol{\beta}\leq t, \ \text{ para una }\ t>0.
\] El argumento que minimiza la función anterior es \[
\widehat{\boldsymbol{\beta}}_{\text{Regul}}=\left(X^{\top} X+Q\right)^{-1} X^{\top} \boldsymbol{Y}.
\]
ImportanteDemostración
Puede verse considerando la función \(\phi(\boldsymbol{\beta})=\|\boldsymbol{Y}-X \boldsymbol{\beta}\|^2+\boldsymbol{\beta}^{\top} Q \boldsymbol{\beta}\), la cual es cuadrática en \(\boldsymbol{\beta}\). Se tiene \[
\begin{aligned}
\phi(\boldsymbol{\beta}) & =\|\boldsymbol{Y}-X \boldsymbol{\beta}\|^2+\boldsymbol{\beta}^{\top} Q \boldsymbol{\beta} \\[10pt]
&=\left(\boldsymbol{Y}-X \boldsymbol{\beta}\right)^{\top}\left(\boldsymbol{Y}-X \boldsymbol{\beta}\right)+\boldsymbol{\beta}^{\top} Q \boldsymbol{\beta} \\[10pt]
\phi^{\prime}(\boldsymbol{\beta}) & =-2 X^{\top} \boldsymbol{Y}+2\left(X^{\top} X+Q\right) \boldsymbol{\beta}
\end{aligned}
\] y al hacer \(\phi^{\prime}(\boldsymbol{\beta})=0\) tenemos \[
\begin{aligned}
-2 X^{\top} \boldsymbol{Y}+2\left(X^{\top} X+Q\right) \boldsymbol{\beta} & =0 \\
\widehat{\boldsymbol{\beta}}_{\text{Regul}}& =\left(X^{\top} X+Q\right)^{-1} X^{\top} \boldsymbol{Y}.
\end{aligned}
\] Al ver que \(\phi^{\prime \prime}(\boldsymbol{\beta})=X^{\top} X+Q\) es simétrica definida positiva, se tiene que en efecto \(\widehat{\boldsymbol{\beta}}\) es el mínimo global que buscamos.
4.3.1 Regresión Ridge
El estimador ridge es un caso especial del estimador regularizado cuando \(Q=\alpha I_p\).
Definición 4.1 (Estimador Ridge) En la regresión lineal múltiple, el estimador ridge para el parámetro \(\boldsymbol{\beta}\) es \[
\begin{align}
\widehat{\boldsymbol{\beta}}^{(\alpha)}&= \underset{\boldsymbol{\beta}}{\arg \min }\left(\sum_{i=1}^n\left(y_i-(X \boldsymbol{\beta})_i\right)^2+\alpha\|\boldsymbol{\beta}\|^2\right)\\[10pt]
&=\left(X^{\top} X+\alpha I_p\right)^{-1} X^{\top} \boldsymbol{Y}
\end{align}
\] donde \(\|\boldsymbol{\beta}\|^2=\sum_{j=0}^k \beta_j^2\).
El parámetro \(\alpha \geq 0\) se denomina parámetro de regularización.
Hay una dependencia directa que tiene estimador ridge con en el hiperparámetro \(\alpha\).
La elección de \(\alpha\) como tal es un punto crítico en el proceso de modelación.
El estimador tiene mucha coincidencia con el estimador de mínimos cuadrados, salvo una especie de perturbación que se efectúa en \(X^{\top} X\) antes de invertirla. Esto viene a resolver el problema de una varianza inflada cuando la matriz \(X\) presenta colinealidad.
Se puede verificar que el estimador ridge se puede también al obtener el estimador de mínimos cuadrados del modelo aumentado \[
\boldsymbol{Y}^*=X^* \boldsymbol{\beta}+\boldsymbol{\epsilon}^*,
\] donde \(\boldsymbol{\epsilon}^*\) es un vector de longitud \((n+p)\) de v.a.i.i.d. y \[
X^*=\left[\begin{array}{c}
X \\
\sqrt{\alpha}\ I_p
\end{array}\right], \qquad \boldsymbol{Y}^*=\left[\begin{array}{c}
\boldsymbol{Y} \\
\mathbf{0}
\end{array}\right] .
\] Ya que \(\boldsymbol{\epsilon}^*\) is an \((n+p)\)-vector de va’s i.i.d. Entonces el estimador de mínimos cuadrados de \(\boldsymbol{\beta}\) es \[
\begin{align}
\widehat{\boldsymbol{\beta}}_n^*&=\underset{\boldsymbol{\beta}}{\arg \min } \left\{\left(\boldsymbol{Y}^*-\boldsymbol{X}^* \boldsymbol{\beta}\right)^{\top}\left(\boldsymbol{Y}^*-\boldsymbol{X}^* \boldsymbol{\beta}\right)\right\}\\
&=\left(X^{* \top} X^*\right)^{-1} X^{* \top} \boldsymbol{Y}^* \\
& =\left(X^{\top} X+\alpha I_p\right)^{-1} X^{\top} \boldsymbol{Y} \\
& =\widehat{\boldsymbol{\beta}}^{(\alpha)}.
\end{align}
\]
en donde \[
Z=\left(I_p+\alpha\left(X^{\top} X\right)^{-1}\right)^{-1}.
\] Ahora, del hecho que \[
\left(X^{\top} X+\alpha I_p\right)^{-1}\left(X^{\top} X+\alpha I_p\right)=I_p
\] tenemos \[
\left(X^{\top} X+\alpha I_p\right)^{-1} X^{\top} X=I_p-\alpha\left(X^{\top} X+\alpha I_p\right)^{-1}.
\tag{4.1}\]
Esta expresión nos ayudará a encontrar el sesgo. Tenemos \[
\begin{aligned}
\widehat{\boldsymbol{\beta}}^{(\alpha)} & =\left(X^{\top} X+\alpha I_p\right)^{-1} X^{\top} \boldsymbol{Y} \\
& =\left(X^{\top} X+\alpha I_p\right)^{-1}\left(X^{\top} X\right)\left(X^{\top} X\right)^{-1} X^{\top} \boldsymbol{Y}\\
& =\left(X^{\top} X+\alpha I_p\right)^{-1}\left(X^{\top} X\right) \widehat{\boldsymbol{\beta}} \\
& =\left(I_p-\alpha\left(X^{\top} X+\alpha I_p\right)^{-1}\right) \widehat{\boldsymbol{\beta}} \\
& =\widehat{\boldsymbol{\beta}}-\alpha\left(X^{\top} X+\alpha I_p\right)^{-1} \widehat{\boldsymbol{\beta}},
\end{aligned}
\] donde en la penúltima ecuación hemos usado la parte derecha de (4.1). Entonces \[
\begin{aligned}
& \mathbb{E}\left(\widehat{\boldsymbol{\beta}}^{(\alpha)}\right)=\boldsymbol{\beta}-\alpha\left(X^{\top} X+\alpha I_p\right)^{-1} \boldsymbol{\beta}. \\[5pt]
&\text{Var}\left(\widehat{\boldsymbol{\beta}}^{(\alpha)}\right)=\sigma^2 Z\left(X^{\top} X\right)^{-1} Z^{\top}.
\end{aligned}
\] Para la expresión de la varianza hemos usado \(\widehat{\boldsymbol{\beta}}^{(\alpha)}=Z \widehat{\boldsymbol{\beta}}.\)
Proposición 4.2 El error cuadrático medio del estimador ridge de parámetro \(\alpha\) está dado por \[
\operatorname{ECM}\left(\widehat{\boldsymbol{\beta}}^{(\alpha)} \right) = \sum_{j=1}^p \frac{\alpha^2 \gamma_j^2}{\left(\lambda_j+\alpha\right)^2}+\sigma^2 \sum_{j=1}^p \frac{\lambda_j}{\left(\lambda_j+\alpha\right)^2},
\]
donde los \(\lambda_i\) son los eigenvalores de \(\left(X^{\top}X\right)\ \ \ \text{y}\ \ \ \gamma=T^{\top} \boldsymbol{\beta}\), siendo \(T\) una matriz cuyas columnas son los eigenvectores de \(\left(X^{\top}X\right)\).
ImportanteDemostración
Tarea.
Hints:
Probar que \[
\operatorname{ECM}(\widehat{\theta})=\mathbb{E}\left(\|\widehat{\theta}-\theta\|^2\right)=\|\mathbb{E}(\widehat{\theta})-\theta\|^2+\operatorname{tr}\left[\text{Var}\left(\widehat{\theta}\right)\right]
\]
Usar la descomposición estpectral de \(X^{\top} X = T \Lambda ^{\top}\) con \(\Lambda=\operatorname{diag}\left\{\left(\lambda_1, \ldots, \lambda_p\right)\right\}\).
Observación: El estimador ridge es sesgado. Preocupante, pero introducimos sesgo para buscar la ventaja de reducir la varianza!
Proposición 4.3 Basados en la descomposición espectral de \(X^{\top}X\), las varianzas del estimador de mínimos cuadrados y ridge son, respectivamente \[
\begin{align}
\text{Var}\left(\widehat{\boldsymbol{\beta}}\right) &= \sigma^2 \sum_{j=1}^p \frac{1}{\lambda_j} \boldsymbol{v}_j\boldsymbol{v}_j^{\top}\\[7pt]
\text{Var}\left(\widehat{\boldsymbol{\beta}}^{(\alpha)}\right)& = \sigma^2 \sum_{j=1}^p \frac{\lambda_j}{(\lambda_j+\alpha)^2} \boldsymbol{v}_j\boldsymbol{v}_j^{\top}
\end{align}
\]
La expresión de la varianza del estimador ridge muestra cómo la regularización afecta la contribución de cada componente, reduciendo la sensibilidad a valores propios pequeños. La disminución de la varianza es debida a que los eigenvalores son positivos (ya que \(X^{\top}X\) es definida positiva cuando \(X\) es de rango completo) y si \(\alpha>0\), \[
\begin{align}
\frac{\lambda_j}{\lambda_j+\alpha} < 1.\qquad
\Leftrightarrow \qquad &\left(\frac{\lambda_j}{\lambda_j+\alpha}\right)^2 < 1 \\[5pt]
\Leftrightarrow \qquad &\frac{\lambda_j}{(\lambda_j+\alpha)^2} < \frac{1}{\lambda_j}.
\end{align}
\]
ImportanteDemostración
Para demostrar la expresión de la varianza de \(\widehat{\boldsymbol{\beta}}^{(\alpha)}\), con expresión \[
\widehat{\boldsymbol{\beta}}^{(\alpha)}= \left(X^\top X + \alpha I_p\right)^{-1} X^\top \boldsymbol{Y},
\] usamos \(X^{\top}X=T\Lambda T\), ya que entonces \[
\begin{align}
\left(X^\top X + \alpha I_p\right)^{-1} &= \left(T \Lambda T^\top + \alpha \,T\,T^\top\right)^{-1} \\
&=T \left(\Lambda + \alpha I_p\right)^{-1} T^\top.
\end{align}
\] Así, \[
\widehat{\boldsymbol{\beta}}^{(\alpha)} = T \left(\Lambda + \alpha I_p\right)^{-1} T^\top X^\top \boldsymbol{Y}.
\] Como \[
\text{Var}\left(\widehat{\boldsymbol{\beta}}^{(\alpha)}\right) = \sigma^2 \left(X^\top X + \alpha I\right)^{-1} X^\top X \left(X^\top X + \alpha I\right)^{-1},
\] por simetría y ahora, sustituyendo la descomposición espectral de \(X^\top X\), \[
\begin{align}
\text{Var}\left(\widehat{\boldsymbol{\beta}}^{(\alpha)}\right) &= \sigma^2 \left[T \left(\Lambda + \alpha I\right)^{-1} T^\top \right] T \Lambda T^\top \left[T \left(\Lambda + \alpha I\right)^{-1} T^\top \right]\\[5pt]
&=\sigma^2 \ T \left(\Lambda + \alpha I\right)^{-1} \Lambda\ \left(\Lambda + \alpha I\right)^{-1} T^\top \\[5pt]
&= \sigma^2 \sum_{j=1}^p \frac{\lambda_j}{\left(\lambda_j + \alpha\right)^2} \boldsymbol{v}_j \boldsymbol{v}_j^\top.
\end{align}
\]
Proposición 4.4 (Existencia) Existe un valor de \(\alpha>0\) para el cual \(\text{ECM}( \widehat{\boldsymbol{\beta}}^{(\alpha)})\) es estrictamente menor que el \(\text{ECM}(\widehat{\boldsymbol{\beta}})\).
ImportanteDemostración
Como el estimador de mínimos cuadrados y ridge coinciden para \(\alpha=0\), basta derivar \(\text{ECM}(\widehat{\boldsymbol{\beta}}^{(\alpha)})\) respecto a \(\alpha\) y evaluar en cero para ver que la derivada es negativa. Esto significará que al aumentar \(\alpha\) ligeramente (desde 0), el ECM disminuye inicialmente. Esto implica que existe un \(\alpha > 0\) que reduce el ECM comparado con el caso de mínimos cuadrados.
Usando la expresión en Proposición 4.2, tenemos \[
\left.\frac{\partial \ \text{ECM}\left(\widehat{\boldsymbol{\beta}}^{(\alpha)}\right) }{\partial \alpha} \right|_{\ \alpha=0}=-2\sigma^2 \sum_{j=1}^p \frac{1}{\lambda_j^2} <0.
\]
NotaEjemplo: Modelos para datos de mediciones corporales
Consideremos el conjunto de datos de mediciones corporales de 33 mujeres candidatas a ingresar a un departamento de policía en Estados Unidos (datos de Gunts & Mason). Deseamos construir un modelo para las alturas en términos de las demás mediciones.
La estandarización de variables no necesariamente se tiene que hacer, pero lo haremos en este caso.
Usando un valor razonable para \(\alpha\): \(\alpha=0.03\), obtenemos los siguientes parámetros estimados y los correspondientes VIF’s:
Código
# cargamos datoslibrary(knitr)library(regclass)dat<-read.csv("https://raw.githubusercontent.com/leticiaram/data/refs/heads/main/mediciones.csv", head=FALSE)names(dat)<-c("altura","altsen","brasup", "brainf", "mano", "legsup","leginf","pie", "braq","tibia")dat1<-subset(dat, select =-c(altura))# Estandarizamos covariablesdat1<-scale(dat1)# Regresión Ridge (directamente)W<-dat1#datos escaladosn<-dim(W)[1]k<-dim(W)[2]y<-dat$alturabet<-solve(t(W)%*%W, t(W)%*%y)# bet <- (lm(y~W))$coef # no hay dif. si ponemos intercepto o no# dat2 <- data.frame(T_Height=dat$T_Height, dat1)# mod <- lm(T_Height~., data=dat2)alfa<-0.8betR<-solve(t(W)%*%W+alfa*diag(k), t(W)%*%y)vif<-diag(solve(t(W)%*%W))wwi<-solve(t(W)%*%W+alfa*diag(k))vifR<-diag(wwi%*%t(W)%*%W%*%wwi)kable(round(cbind(bet,vif,betR,vifR),4), col.names =c('hbeta', 'VIF', 'hbeta_R','VIF_R'))
hbeta
VIF
hbeta_R
VIF_R
altsen
2.0912
0.0468
2.0956
0.0371
brasup
3.3752
15.0948
0.0669
0.0473
brainf
-2.9442
12.2935
0.2137
0.0527
mano
0.7507
0.0754
0.7360
0.0637
legsup
-2.0051
27.9411
1.1319
0.0352
leginf
4.7645
27.3144
1.5993
0.0381
pie
0.6078
0.0557
0.5966
0.0488
braq
3.7011
14.4165
0.4143
0.0311
tibia
-1.9062
15.3036
0.4089
0.0373
Recordemos que la ordenada el estimador de la ordenada al origen es \(\bar{y}\).
Los VIF’s asociados al estimador Ridge mostrados en el ejemplo son los elementos diagonales de \(Q\) donde \[
\text{Var}(\widehat{\boldsymbol{\beta}}_R) = \sigma^2 Q = \sigma^2 (W^{\top}W+\alpha I_k)^{-1}\ W^{\top}W \ (W^{\top}W+\alpha I_k)^{-1}
\]
Notamos una reducción en las varianzas de los estimadores Ridge.
Como tenemos en Proposición 4.3 , si hacemos \(\alpha\) grande podemos disminuir tanto como queramos la varianza, sin embargo
Por lo que \(\mathbb{E}\left(\widehat{\boldsymbol{\beta}}^{(\alpha)}\right) \to 0\) cuando \(\alpha \to \infty\).
Se necesita un balance “sesgo-varianza’’. Para ello se puede
Usar validación cruzada
Utilizar una rejilla/ rango de valores de \(\alpha\) y para cada una calcular \(\text{SS}_{\text{Res}}\), \(R^2\), \(\widehat{\text{ECM}}\) y tomar el que minimice.
Existe otras opciones algunas de las cuales son resultados recientes de investigación.
4.3.1.1 Selección del Parámetro Ridge
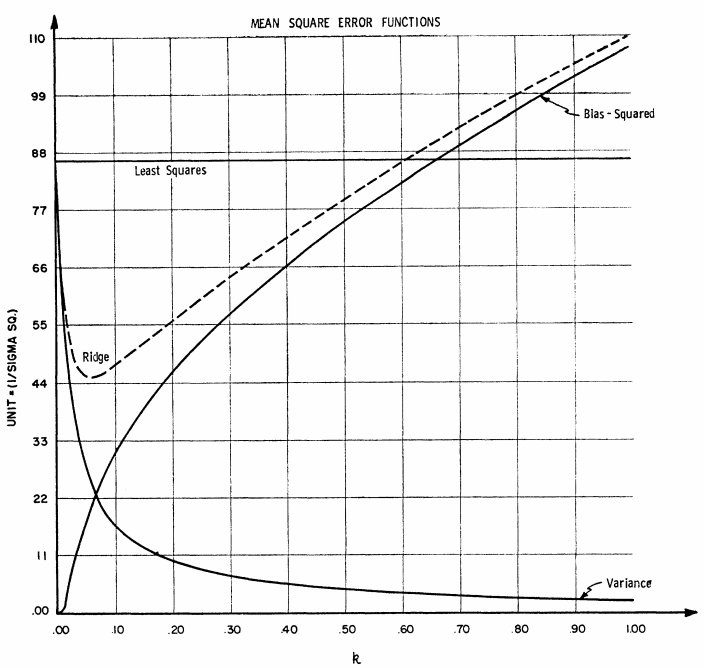
Como hemos comentado, el ECM en Proposición 4.2 se descompone en el sesgo cuadrado más la varianza. Los denotamos repectivamente \(\delta_1(\alpha)\) y \(\delta_2(\alpha)\). Se puede mostrar que \(\delta_1(\alpha)\) es una función monótona y creciente, mientras que \(\delta_2(\alpha)\) es monótona y decreciente.
Figura 4.2: ECM for ridge regression. Hoerl, A. E., & Kennard, R. W. (1970).
De la Proposición 5.1 tenemos también que existe un valor de \(\alpha>0\) para el cual \[
\text{ECM}\left( \widehat{\boldsymbol{\beta}}^{(\alpha)}\right)<\text{ECM}\left( \widehat{\boldsymbol{\beta}}\right)=\sigma^2\sum_{j=1}^{p}\frac{1}{\lambda_j}.
\] Por otro lado, se puede ver que \(\delta_1(\alpha)\) no crece ilimitadamente sino que \[
\begin{align}
\delta_1(\alpha)&=\sum_{j=1}^p \frac{\alpha^2 \gamma_j^2}{\left(\lambda_j+\alpha\right)^2}
=\sum_{j=1}^p \frac{\gamma_j^2}{\left(\frac{\lambda_j+\alpha}{\alpha}\right)^2}\\
&=\sum_{j=1}^p \frac{\gamma_j^2}{\left(\frac{\lambda_j}{\alpha}+1\right)^2}\quad\rightarrow \quad \sum_{j=1}^p \gamma_j^2, \quad \text{cuando }\quad \alpha\rightarrow\infty.
\end{align}
\] Donde \[
\sum_{j=1}^p \gamma_j^2=(T^{\top}\boldsymbol{\beta})^{\top}(T^{\top}\boldsymbol{\beta})=
\boldsymbol{\beta}^{\top}T\ T^{\top}\boldsymbol{\beta}=\boldsymbol{\beta}^{\top}\boldsymbol{\beta}=\|\boldsymbol{\beta}\|^2.
\]
Proposición 4.5 (Cota para \(\alpha\) optima) La \(\alpha\) óptima es tal que \(0< \alpha < \frac{\sigma^2}{ \| \boldsymbol{\beta} \|^2}\).
En la práctica, para definir un valor máximo de \(\alpha\) se puede usar \(\sigma^2/ \|\boldsymbol{ \beta} \|^2 \approx \widehat{\sigma}^2/ \| \widehat{\boldsymbol{\beta}} \|^2\).
ImportanteDemostración
Usando Proposición 4.2 y su representación con \(\delta_1(\alpha)\) y \(\delta_2(\alpha)\), \[
\frac{\partial\operatorname{ECM}\left(\widehat{\boldsymbol{\beta}}^{(\alpha)} \right)}{\partial \alpha} = \frac{\partial\left(\delta_1(\alpha)+\delta_2(\alpha)\right)}{\partial \alpha}=-2\alpha\sum_{j=1}^p \frac{\lambda_j\gamma_j^2}{(\lambda_j+\alpha)^3}-2\sigma^2\sum_{j=1}^p\frac{\lambda_j}{(\lambda_j+\alpha)^3}
\] que es menor a cero si \[
\alpha<\frac{\sigma^2\sum \frac{\lambda_j}{(\lambda_j+\alpha)^3}}{\sum \frac{\lambda_j\gamma_j^2}{(\lambda_j+\alpha)^3}}\leq\frac{\sigma^2}{\|\boldsymbol{\beta}\|^2}.
\]
Con este espíritu, varias cotas y valores iniciales para \(\alpha\) se han propuesto. Algunos de ellos son:
Cota basada en el ruido y diseño: Hoerl, A. E., & Kennard, R. W. (1970). “Ridge regression: Biased estimation for nonorthogonal problems”. Technometrics. \[
\alpha \leq \frac{\sigma^2 n}{\|\boldsymbol{\beta}\|^2\ \text{tr}(X^{\top} X)},
\] donde \(n\) el número de muestras.
Cota basada en autovalores (Análisis espectral): Van Wieringen, W. (2015). “Lecture notes on ridge regression”. arXiv:1509.09169. \[
\alpha \leq \frac{\sigma^2}{\|\boldsymbol{\beta}\|^2 \ \lambda_{\text{min}}(X^{\top} X)},
\] donde \(\lambda_{\text{min}}\) es el autovalor mínimo de \(X^{\top} X\).
Cota basada en riesgo (MSE minimax): Hastie, T., Tibshirani, R., & Friedman, J. (2009). “The Elements of Statistical Learning”. Springer (Sección 3.4.1). \[
\alpha \approx \frac{\sigma^2 \ p}{\|\boldsymbol{\beta}\|^2},
\] donde \(p\) es la dimensión de \(\boldsymbol{\beta}\).
Cota empírica (Regla de oro): Greenland, S. (1993). “Methods for epidemiologic analyses of multiple exposures”. Epidemiology. \[
\alpha = \frac{p \ \text{Var}(y)}{\|\widehat{\boldsymbol{\beta}}_{\text{OLS}}\|^2},
\] donde \(\widehat{\boldsymbol{\beta}}_{\text{OLS}}\) es el estimador mínimos cuadrados ordinarios.
Cota bayesiana (MAP estimation): Bishop, C. M. (2006). “Pattern Recognition and Machine Learning”. Springer (Sección 3.1.4). \[
\boldsymbol{\beta} \sim N(0, \tau^2 I)
\] y \(\epsilon \sim N(0, \sigma^2)\), entonces \(\alpha = \sigma^2 / \tau^2\). La motivación de este valor es la equivalencia entre Ridge y estimación bayesiana bajo previas gaussianas.
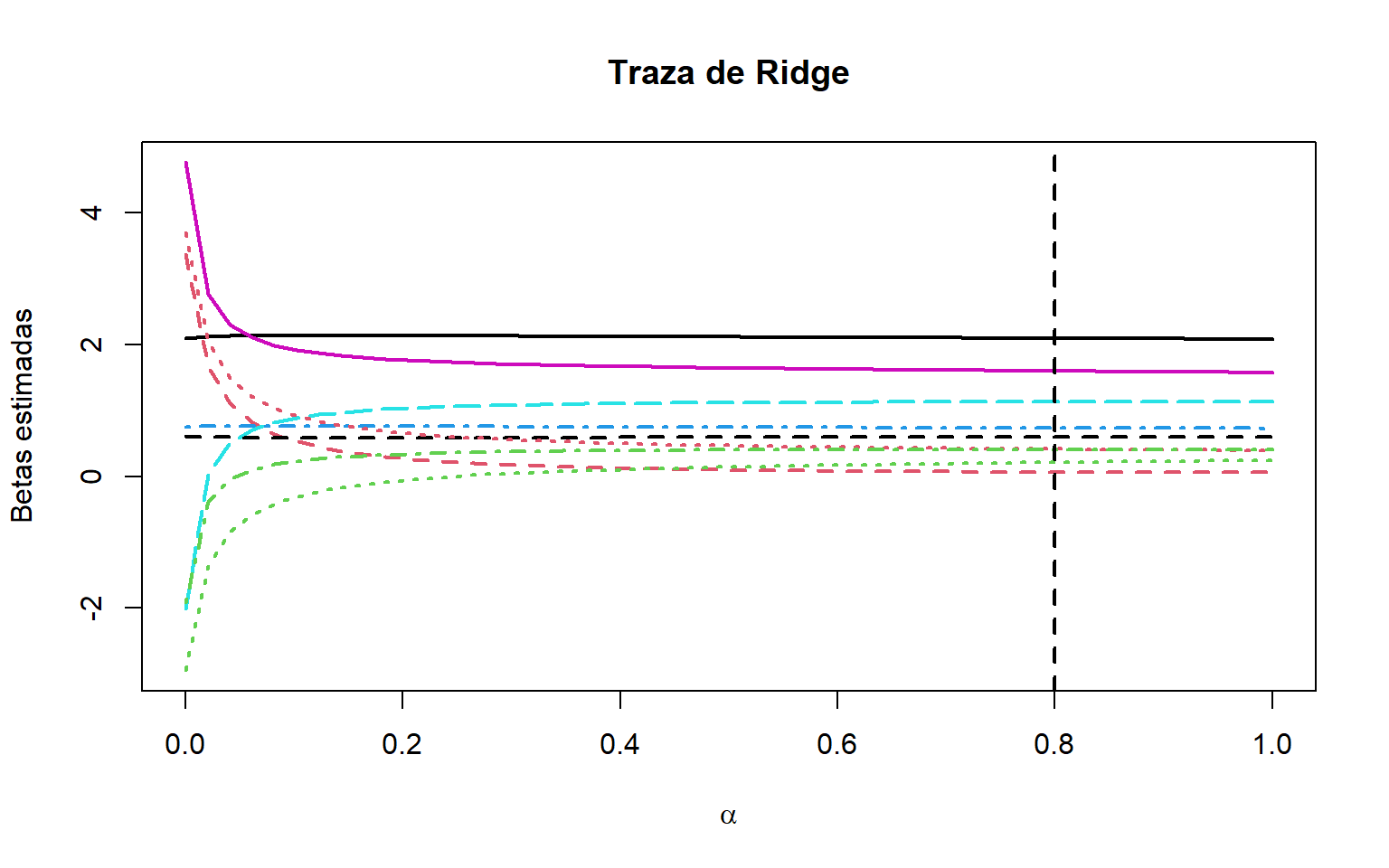
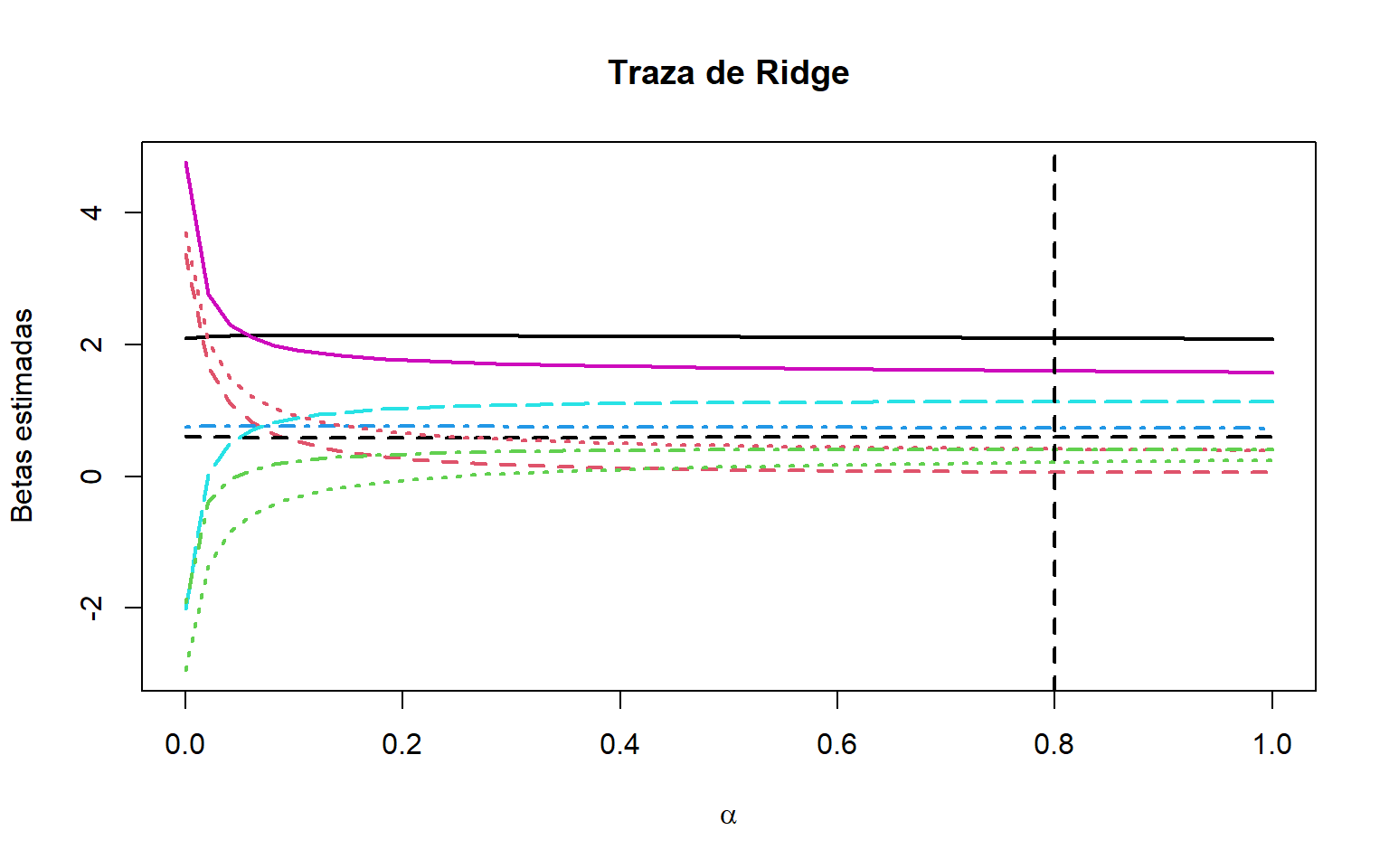
Una forma de lograr el balance “sesgo-varianza” es mediante la traza de Ridge, que consiste en calcular los estimadores de Ridge para un rango de valores de \(\alpha\).
Para valores cercanos a cero tipicamente se observan cambios bruscos en los estimadores (sobre todo en los correspondientes a variables colineales), conforme \(\alpha\) crece observaremos una disminución en la variabilidad y un comportamiento gradual tendiendo a cero.
La recomendación es tomar a \(\alpha\) como algún valor para el cual tengamos una estabilización en los perfiles (traza) de los estimadores Ridge. En el ejemplo escogimos el valor \(\alpha=0.8\) usando este criterio.
NotaEjemplo: Modelos para datos de mediciones corporales (cont.)
Consideremos el conjunto de datos de mediciones corporales de 33 mujeres candidatas a ingresar a un departamento de policía en Estados Unidos (datos de Gunts & Mason). Deseamos construir un modelo para las alturas en términos de las demás mediciones.
La estandarización de variables no necesariamente se tiene que hacer, pero lo haremos en este caso.
Usando un valor razonable para \(\alpha\): \(\alpha=0.03\), obtenemos los siguientes parámetros estimados y los correspondientes VIF’s:
Código
traza_ridge<-function(alfa){solve(t(W)%*%W+alfa*diag(k), t(W)%*%y)}alfa_valores<-seq(0, 1, length =50)mat_est<-sapply(alfa_valores, FUN =traza_ridge)matplot(alfa_valores, t(mat_est), t ="l",lwd =2, xlab =expression(alpha),ylab ="Betas estimadas",main="Traza de Ridge")abline(v =0.8, lty =2, lwd =2)
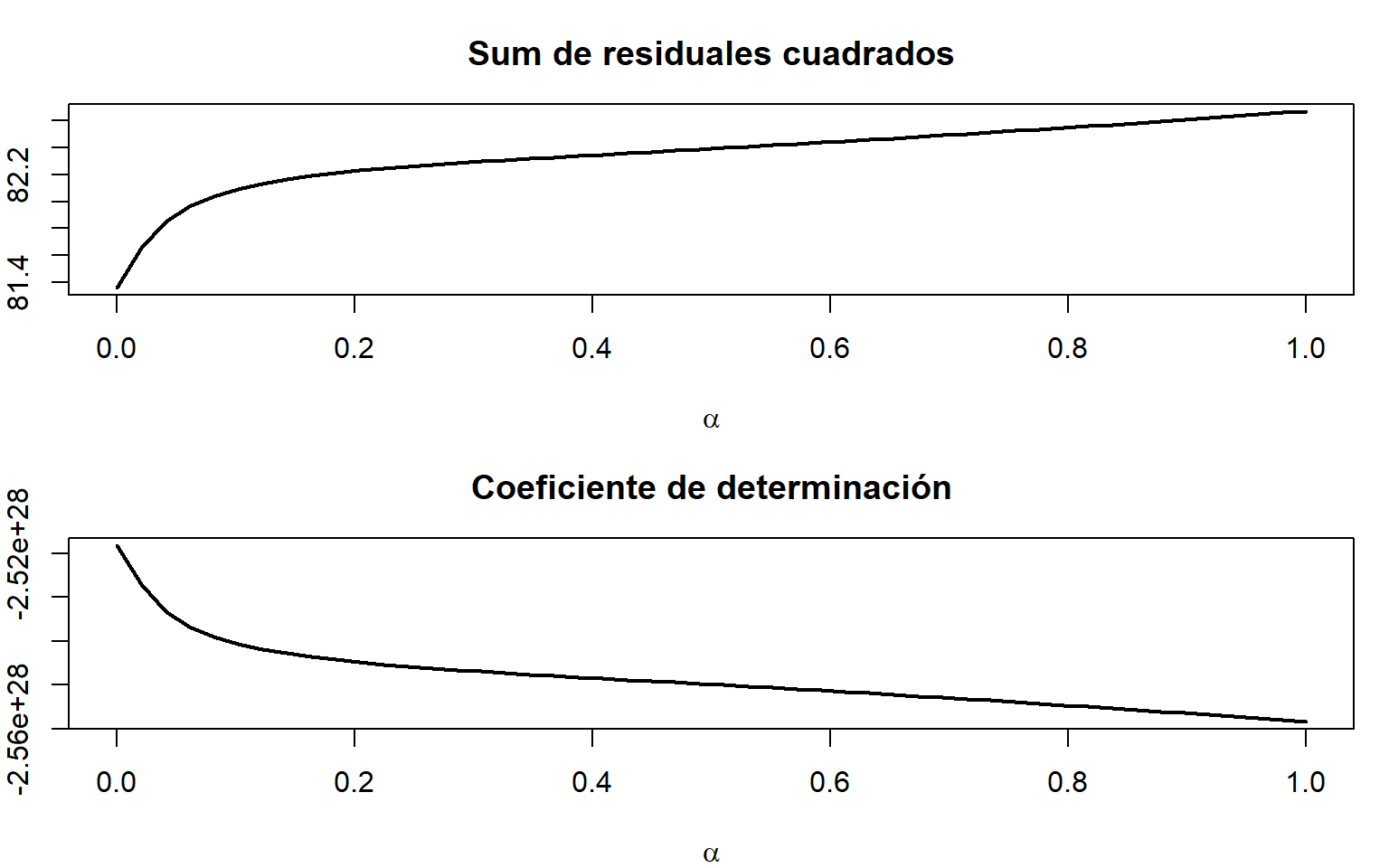
Mostramos también el comportamiento de las sumas de cuadrados del error y de los coeficientes de determinación que se obtendrían para diferentes valores de \(\alpha\); aquí simplemente usaríamos esas gráficas como apoyo en la decisión sobre \(\alpha\), cuidando que no haya cambios bruscos en esos indicadores.
Código
residual_alfa<-function(alfa){betR<-solve(t(W)%*%W+alfa*diag(k), t(W)%*%y)allbetaR<-c(mean(y),betR)#params incluyendo el interceptoXest<-cbind(cte =1, W)hat_y<-Xest%*%allbetaRsum2errores<-sum((y-hat_y)^2)sum2errores}SSres<-sapply(alfa_valores, FUN =residual_alfa)par(mfrow =c(2,1), oma =c(0,0,0,0),mar=c(4,2,3,1))plot(alfa_valores, SSres, t ="l",lwd =2, xlab =expression(alpha),ylab ="",main="Sum de residuales cuadrados")plot(alfa_valores, 1-SSres/sum(y-mean(y))^2, t ="l",lwd =2, xlab =expression(alpha),ylab ="",main="Coeficiente de determinación")
NotaEjemplo: Modelos para datos de mediciones corporales (cont.)
Código
library(glmnet)# Definir valores de lambda para probarval_alfas<-seq(0.001, 1, length.out =50)Xest<-cbind(cte =1, W)# Configuración para validación cruzada (10-folds)set.seed(123)k<-5# Número de particiones (folds)folds<-sample(rep(1:k, length.out =n))#pertenencia a gruposECM_cv<-numeric(length(val_alfas))for(jinseq_along(val_alfas)){ECM_folds<-numeric(k)for(iin1:k){test_idx<-which(folds==i)train_idx<-setdiff(1:n, test_idx)X_train<-Xest[train_idx, ]y_train<-y[train_idx]X_test<-Xest[test_idx, ]y_test<-y[test_idx]ridge_model<-glmnet(X_train, y_train, alpha =0, lambda =val_alfas[j])# Medir calidad de predicciones en el cjto validacióny_pred<-predict(ridge_model, X_test)ECM_folds[i]<-mean((y_test-y_pred)^2)}ECM_cv[j]<-mean(ECM_folds)#Promediar ECM sobre los folds}plot(val_alfas, ECM_cv, pch=19)alfa_opt<-val_alfas[which.min(ECM_cv)]# alfa óptimoabline(v =alfa_opt, lty =2, lwd =2)
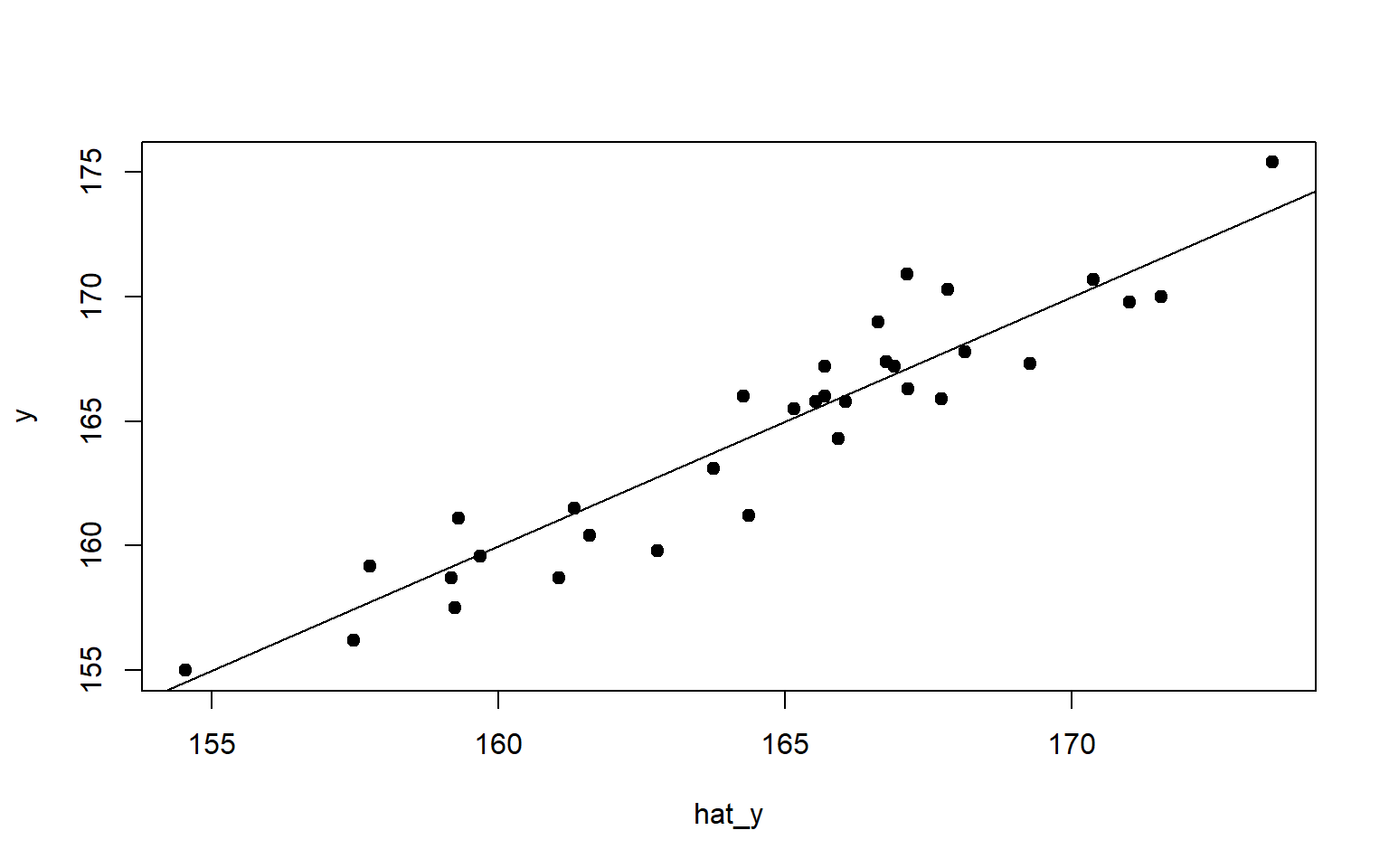
# Modelo final con alfa óptimoridge_final<-glmnet(Xest, y, alpha =0, lambda =alfa_opt)print(ridge_final$beta)
#> 10 x 1 sparse Matrix of class "dgCMatrix"
#> s0
#> cte .
#> altsen 1.9320189
#> brasup 0.1322424
#> brainf 0.4300350
#> mano 0.6627427
#> legsup 1.0729450
#> leginf 1.4123994
#> pie 0.6172333
#> braq 0.3321221
#> tibia 0.3604690
Código
hat_y<-predict(ridge_model, Xest)# igual a hat_y <- Xest %*% c(mean(y),ridge_final$beta[-1])plot(hat_y,y,pch=19)abline(0,1)
4.3.2 Regresión Lasso
4.3.2.1 Otra Motivación para “sparcity”
Consideremos el modelo de Regresión Lineal estándar
\[
\boldsymbol{Y} = X\boldsymbol{\beta} + \boldsymbol{\epsilon}, \qquad \boldsymbol{\epsilon} \sim N_n(0,\sigma^2I).
\] El estimador de mínimos cuadrados es \(\widehat{\boldsymbol{\beta}}=(X^{\top}X)^{-1}X^{\top}\boldsymbol{Y}\).
Consideremos ahora el valor de la respuesta, \(y_0\), correspondiente a un nuevo valor de la covariable \(\boldsymbol{x}_0\). De acuerdo con (1.4 ) el error de predicción es
Esto es, el error de predicción es aproximadamente \[
\mathbb{E}\left[\left(Y_0-\widehat{Y}_0\right)^2\right]\ \approx \ \sigma^2 +
p \, \frac{\sigma^2}{n}.
\]
Una observación interesante es que, por cada variable más que agreguemos al modelo, el error aumenta \(\sigma^2/n\), independientemente de si la variable tiene un coeficiente grande o pequeño .
En aplicaciones de Machine Learning, \(p\) puede ser muy grande y con una alta probabilidad de que sólo un número reducido de variables sean importantes. Tiene sentido entonces, reducir a cero algunos coeficientes pequeños, a sabiendas que potencialmente aumentamos el sesgo (pero también, potencialmente reducimos la varianza de predicción).
Estimación “Dispersa”
Una forma de inducir ceros en la estimación de un modelo de regresión es mediante la regularización como en Proposición 4.1. Diferentes \(Q\) puede forzar con mayor o menor fuerza a cero valores de \(\widehat{\boldsymbol{\beta}}_{\text{Regul}}\). En contraste con el estimador de la regresión Ridge (Definición 4.1), el estimador Lasso introduce la penalización \(L_1\): \[
\begin{align}
\widehat{\boldsymbol{\beta}}_{\text{Lasso}}^{(\alpha)}&= \underset{\boldsymbol{\beta}}{\arg \min }\left(\sum_{i=1}^n\left(y_i-(X \boldsymbol{\beta})_i\right)^2+\alpha\|\boldsymbol{\beta}\|_1\right)\\
&=\underset{\boldsymbol{\beta}}{\arg \min }\left(\sum_{i=1}^n\left(y_i-(X \boldsymbol{\beta})_i\right)^2+\alpha\sum_{j=1}^k|\beta_j|\right)
\end{align}
\] que es equivalente a estimar los coeficientes del modelo de regresión minimizando \[
\| \boldsymbol{Y}-X\boldsymbol{\beta} \|^2, \quad \text{sujeta a} \quad \|\boldsymbol{\beta}\|_1 \le t, \quad t>0.
\]
Nota: Una alternativa más directa para inducir ceros es minimizar \(||y-X\beta||^2\) bajo la restricción de que el número de elementos no nulos en \(\beta\) sea, por ejemplo, \(t\). Pero este es un problema de optimización bastante más complejo que el lasso.
4.3.2.2 Ridge vs Lasso
El método lasso tiene aparentemente una relación estrecha con el método Ridge de estimación, el cual, estima \(\boldsymbol{\beta}\) mediante la minimización de \[
\|\boldsymbol{Y}-X\boldsymbol{\beta}\|^2, \quad \text{sujeta a} \quad \|\boldsymbol{\beta}\|_2^2 \le t, \le t, \quad t>0.
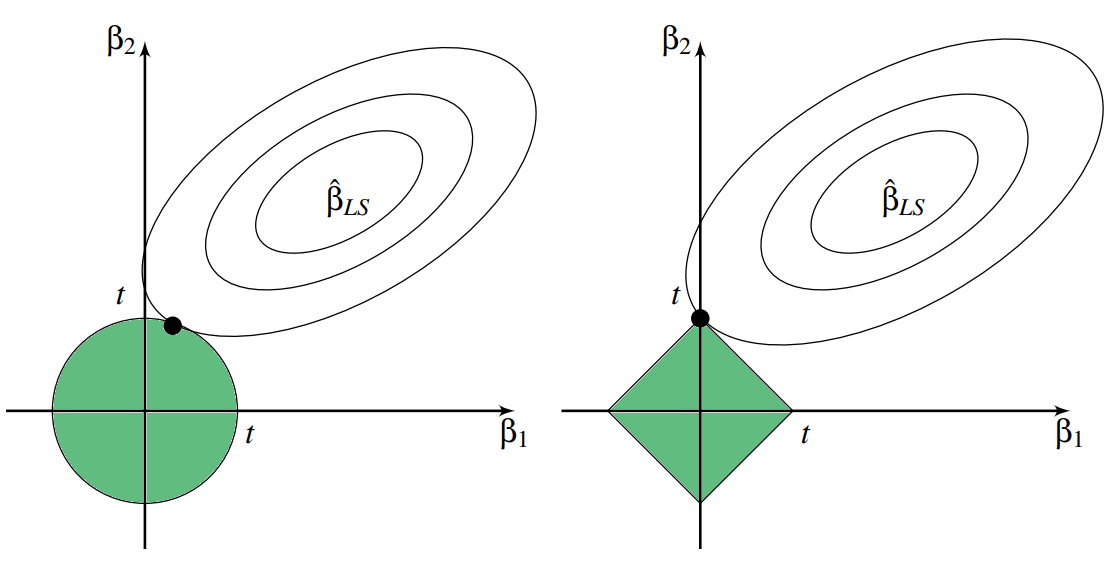
\] donde \(\|\boldsymbol{\beta}\|_2^2 = \sum_j \beta_j^2\). Este método fue introducido para situaciones de multicolinealidades e induce una reducción en la magnitud de los coeficientes (“shrinkage”) disminuyendo la varianza de los estimadores aunque incurriendo en un incremento en sesgo (igual que lasso), pero, a diferencia de lasso, no se induce “dispersidad”, como se ilustra en la Figura 4.3. Ésta representa la estimación para la regresión ridge (izquierda) y la lasso (derecha). Se muestran los contornos de las funciones de error y restricción. Las áreas sólidas en verde representan las regiones de restricción \(\beta_1^2+\beta_2^2 \leq t^2\) y \(\left|\beta_1\right|+\left|\beta_2\right| \leq t\). Las elipses son los contornos de la función de error de mínimos cuadrados.
Figura 4.3: Ilustración de la regresión Ridge y Lasso
4.3.2.3 Lasso con un solo predictor
Supongamos un modelo de regresión lineal simple \[
Y_i = \beta z_i + \epsilon_i, \qquad i=1,\ldots,n
\] con \(\overline{Y}=0, \; \overline{z}=0, \; ||z||^2 = n\) y supuestos usuales en los \(\epsilon_i\)’s. El problema de estimar \(\beta\) usando Lasso, consiste en elegir \(\beta\) que minimice \[
\frac{1}{2n} \sum_{i=1}^n (Y_i-\beta z_i)^2, \quad \text{con} \; |\beta|
\le t.
\] El lagrangiano puede escribirse como \[
L(\beta,\lambda) = \frac{1}{2n} \sum_{i=1}^n (Y_i-\beta z_i)^2
+ \lambda |\beta|
\]
El lagrangiano entonces es \[
L(\beta,\lambda) = \left\{
\begin{array}{lcl}
\frac{1}{2n} \sum_{i=1}^n (Y_i-z_i\beta)^2
+ \lambda \beta & \; & \text{si} \; \beta>0\\[3pt]
\frac{1}{2n} \sum_{i=1}^n (Y_i-z_i\beta)^2
- \lambda \beta & \; & \text{si} \; \beta<0\\[3pt]
\frac{1}{2n} \sum_{i=1}^n Y_i^2 & \; & \text{si} \; \beta=0
\end{array} \right.
\] derivando con respecto a \(\beta\) e igualando a cero, puede verse que el estimador Lasso es \[
\widehat{\boldsymbol{\beta}}_{\text{Lasso}}^{(\lambda)} = \left\{
\begin{array}{ccc}
\frac{1}{n} \sum_{i=1}^n Y_iz_i - \lambda & \text{si} & \sum_{i=1}^n Y_iz_i > \lambda\\[3pt]
0 & \text{si} & \left| \sum_{i=1}^n Y_iz_i \right| < \lambda\\[3pt]
\frac{1}{n} \sum_{i=1}^n Y_iz_i + \lambda & \text{si} & \sum_{i=1}^n Y_iz_i < -\lambda\\[3pt]
\end{array} \right.
\]
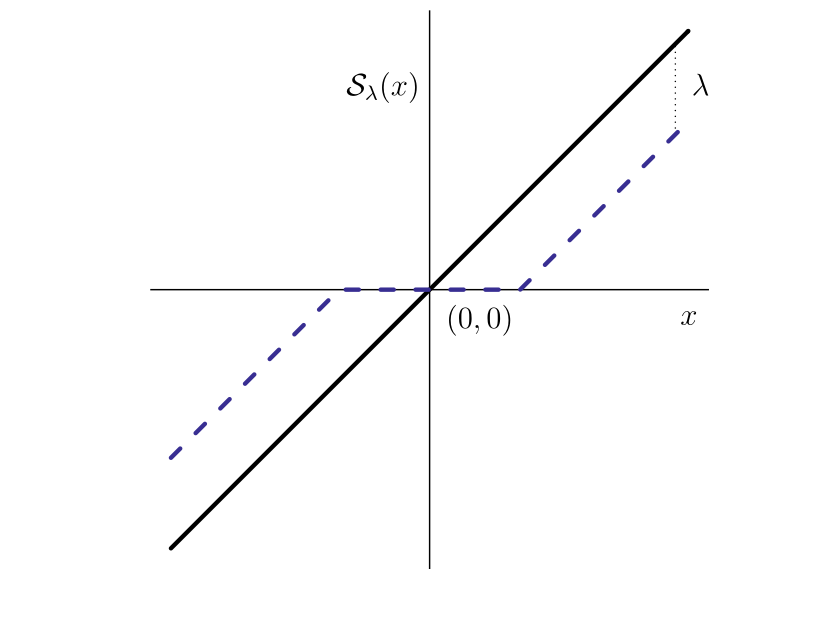
Si definimos la función umbral (Soft thresholding) como \[
S_{\lambda}(x) = \text{signo}(x) \left(|x|-\lambda\right)_{+}
\] La función se muestra en la siguiente figura como la linea punteada azul. La linea identidad se muestra para referencia.
Funcion umbral (Hastie, T., Tibshirani, R., & Wainwright, M.,2016)
Entonces, el estimador Lasso se puede escribir como \[
\widehat{\boldsymbol{\beta}}_{\text{Lasso}}^{(\lambda)} = S_{\lambda}\left(\frac{1}{n} \sum_{i=1}^n Y_iz_i\right)
\]
4.3.2.4 Lasso con Múltiples predictores
En el caso de un modelo de regresión lineal múltiple \[
Y_i = \boldsymbol{x}_i^T \boldsymbol{\beta} + \epsilon_i, \qquad i=1,\ldots,n
\] el estimador Lasso minimiza \[
\frac{1}{2n} \sum_{i=1}^n (Y_i-\boldsymbol{x}_i^{\top}\boldsymbol{\beta})^2, \qquad \text{con} \quad ||\boldsymbol{\beta}||_1 \,\le t
\] El lagrangiano se puede escribir como \[
\begin{align}
L(\beta,\lambda) = & \; \frac{1}{2n} \sum_{i=1}^n (Y_i-\boldsymbol{x}_i^{\top}\boldsymbol{\beta})^2
+ \lambda ||\boldsymbol{\beta}||_1\\
= & \; \frac{1}{2n} \sum_{i=1}^n \left(Y_i-\sum_{j \ne k}x_{ij}\beta_j+x_{ik}\beta_k\right)^2
+ \lambda \sum_{j\ne k}|\beta_j| + \lambda |\beta_k|.
\end{align}
\] Haciendo \[
r_i^{(k)} = Y_i -\sum_{j \ne k}x_{ij}\beta_j \qquad \text{y} \qquad
c = \lambda \sum_{j\ne k}|\beta_j|
\] entonces \[
L(\beta,\lambda) = \frac{1}{2n} \sum_{i=1}^n \left( r_i^{(k)}-x_{ik}\beta_k\right)^2
+ c + \lambda |\beta_k|.
\] Esta expresión se parece a la del lagrangiano para el caso de un solo predictor vista antes que dan lugar a un procedimiento iterativo de solución (Descenso cíclico por coordenadas) usando múltiples veces la solución para un sólo predictor:
Por convexidad (de la función cuadrática objetivo y de la región factible) el problema (en general) el algoritmo de descenso por coordenas converge al óptimo global.
El descenso por coordenadas es un algoritmo de optimización que minimiza sucesivamente en las direcciones de las coordenadas para encontrar el mínimo de una función.
En cada iteración, el algoritmo
determina una coordenada o un bloque de coordenadas mediante una regla de selección de coordenadas y, posteriormente,
minimiza exactamente o de manera aproximada sobre el hiperplano correspondiente de esa coordenada mientras fija todas las demás coordenadas o bloques de coordenadas.
El descenso por coordenadas es aplicable tanto en contextos diferenciables como libres de derivadas.
El descenso por coordenadas se basa en la idea de que la minimización de una función multivariable ( \(F(\boldsymbol{x})\) ) se puede lograr minimizándola en una dirección a la vez, es decir, resolviendo problemas de optimización univariados (o al menos mucho más simples) en un ciclo.
Para más detalles, se puede consultar Wright (2015) o Wu y Lange (2008).
NotaEjemplo: Modelo para criminalidad (Hastie, Tibshirani y Wainwright 2016)
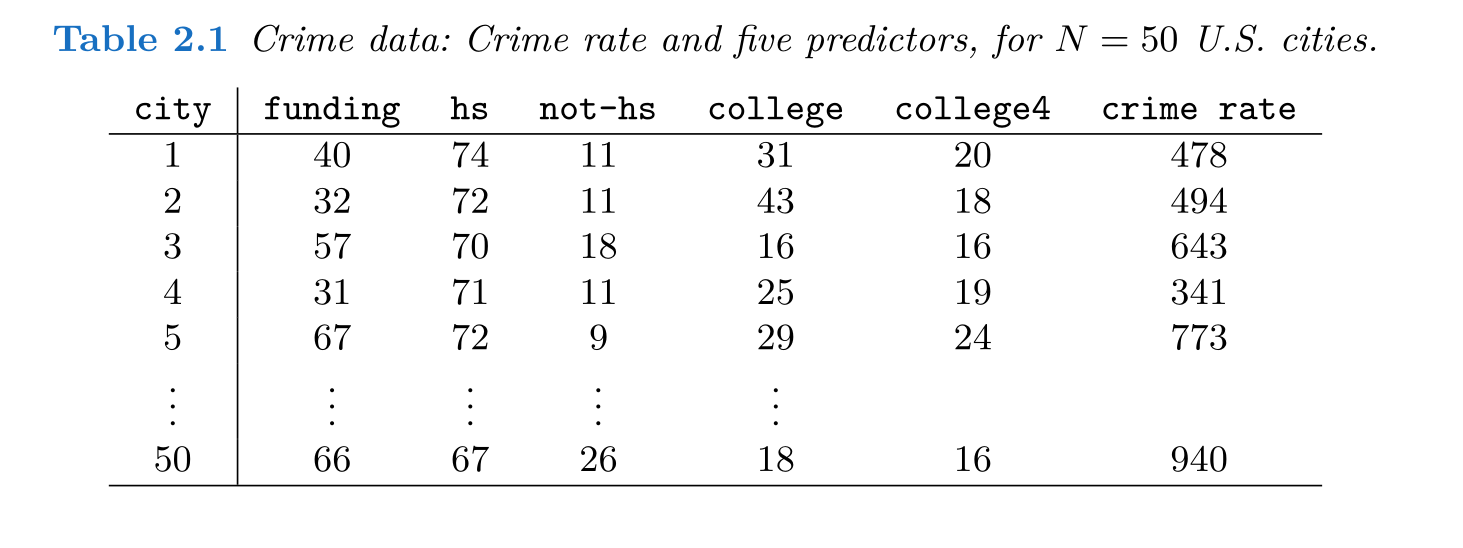
Figura 4.4: Datos HT criminalidad
Queremos un modelo para la tasa de criminalidad en función de factores como
“funding” (presupuesto municipal para seguridad, en $ per cápita),
“hs” (porcentaje de ciudadanos mayores de 25 con preparatoria terminada),
“not-hs” (porcentaje de ciudadanos entre 16 y 19 que no están en preparatoria y no se graduaron de preparatoria),
“college” (porcentaje de ciudadanos entre 18 y 24 cursando estudios universitarios) y
“college4” (porcentaje mayores de 25 con al menos 4 años de universidad).
#datosdat=read.table("data/crime.txt", head=FALSE,sep="\t")# 50 x 7names(dat)<-c("crime_rate","nn","funding", "hs", "not-hs", "college","college4")kable(head(dat[c("crime_rate","funding", "hs", "not-hs", "college","college4")]))#datos sin la segunda columna
crime_rate
funding
hs
not-hs
college
college4
478
40
74
11
31
20
494
32
72
11
43
18
643
57
70
18
16
16
341
31
71
11
25
19
773
67
72
9
29
24
603
25
68
8
32
15
Código
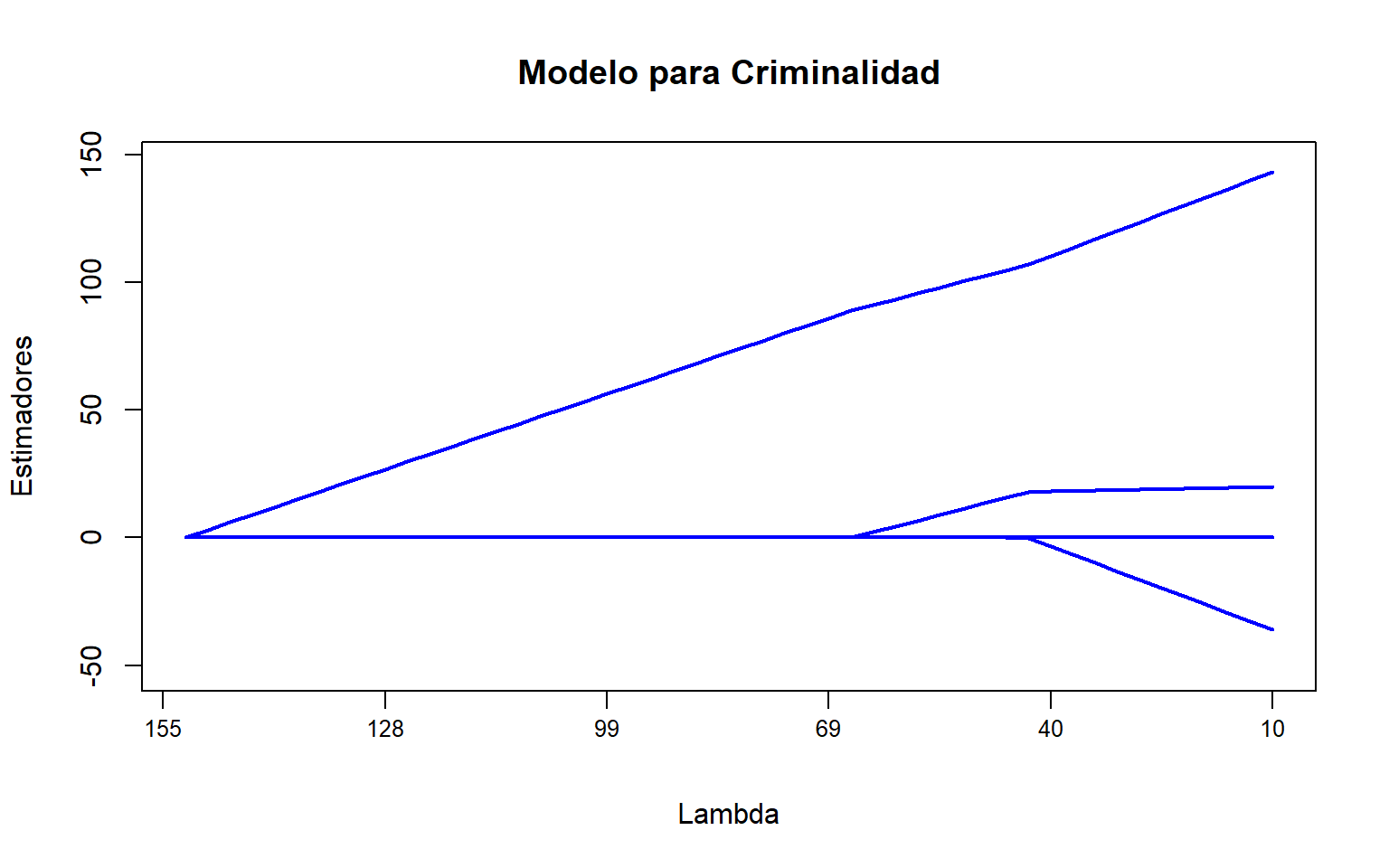
y<-dat[,1]N<-length(y)y<-y-mean(y)X<-dat[,3:7]X<-scale(X, center=TRUE, scale=FALSE)X<-t(t(X)/apply(X,2,function(x)sqrt(sum(x^2)/N)))out<-lm(y~-1+X)beta<-out$coeff#valor inicialbetan<-rep(0,5)betas<-matrix(0,50,5)# matriz donde guardar betas para c/lambdalams<-seq(155,10,length =50)# selección de lambdas (en reversa)slam<-function(x,lambda){# Función umbralsign(x)*(abs(x)-lambda)*(abs(x)>lambda)}for(iin1:50){#diferentes valores de lambdafor(sin1:20){# 20 iteraciones rik=y-X%*%betafor(jin1:5){betan[j]=slam(beta[j]+mean(X[,j]*rik), lams[i])}beta=betan#actualizamos el valor de beta}betas[i,]=beta#guardamos los valores de beta en c/iteración}plot(1:50,betas[,1],type="l",ylim=c(-52,147), lwd=2, col="blue", xaxt="n", xlab="Lambda",ylab="Estimadores", main="Modelo para Criminalidad")axis(1,at =seq(0,50,by=10),labels =round(lams[c(1,seq(0,50,by=10)[-1])]), mgp =c(1.5,.5,0),cex.axis=.8)for(iin2:5){lines(1:50, betas[,i], lwd=2, col="blue")}
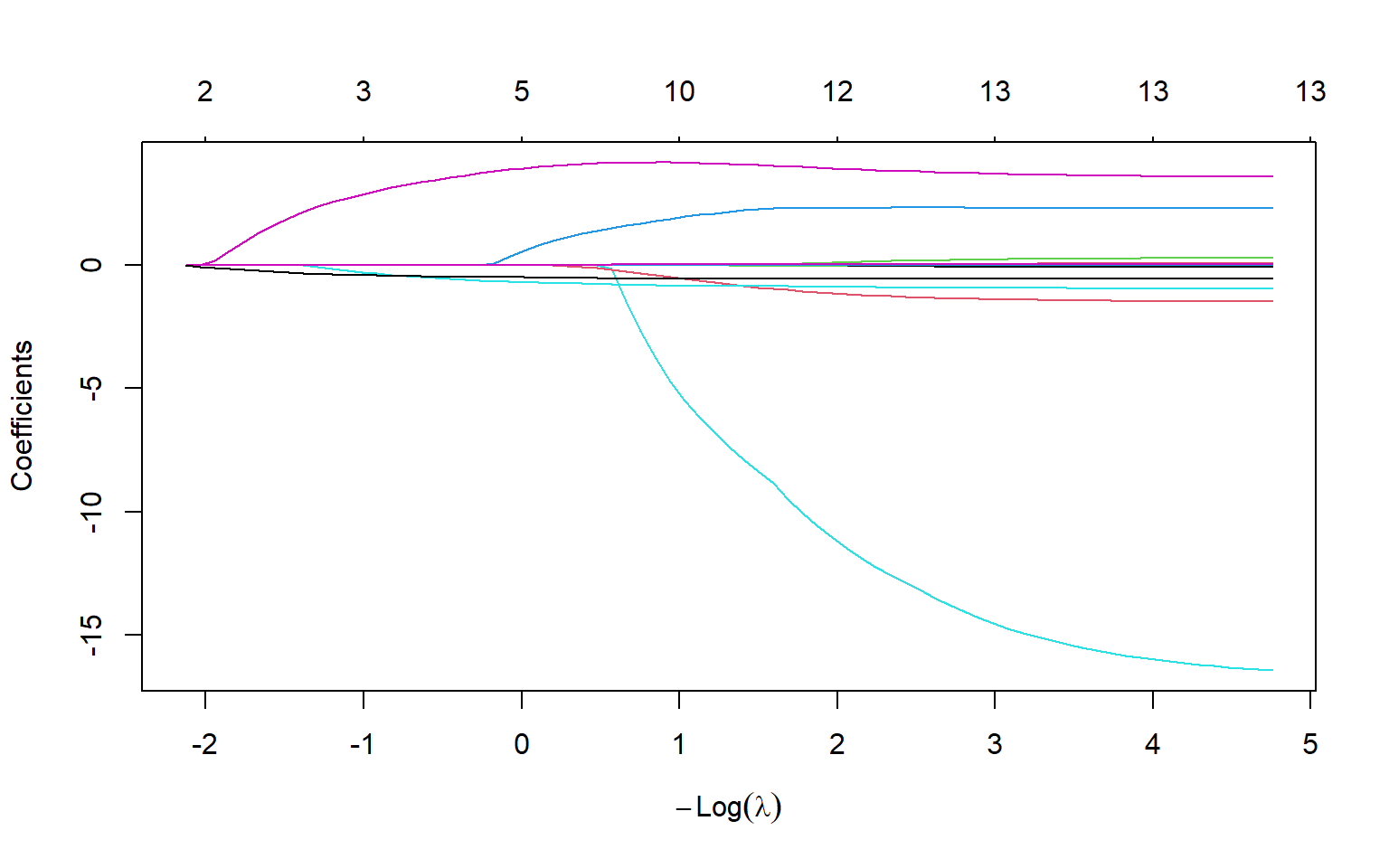
Ajuste Lasso, usando paquetes de R
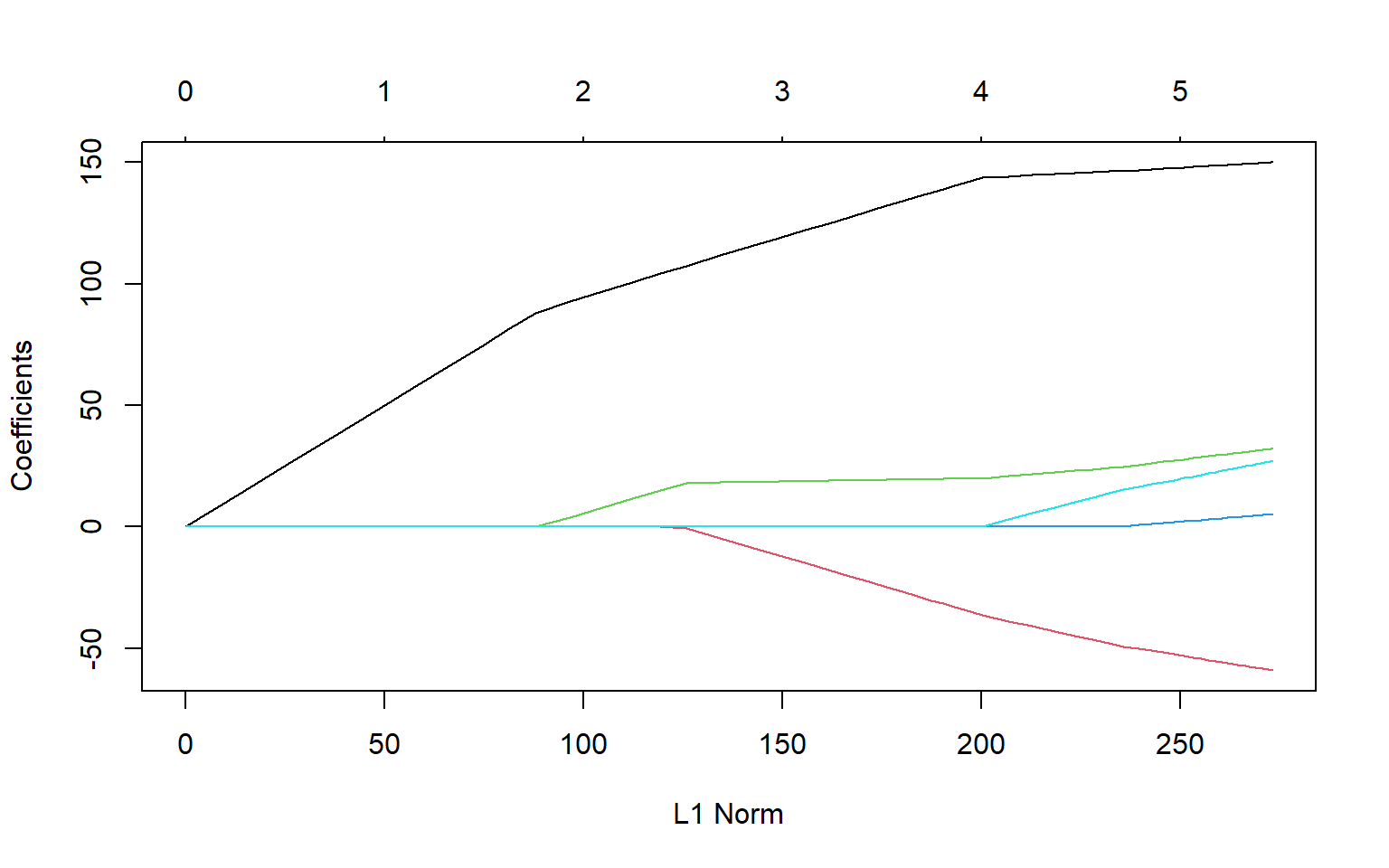
Código
# Usando paquete de R. Ver Hastie, Tibshirani, Wainwright p.11library(glmnet)out<-glmnet(X,y)plot(out)
Código
coef(out, s=50)# extraer coeficientes con un sólo valor de lambda
#> 6 x 1 sparse Matrix of class "dgCMatrix"
#> s=50
#> (Intercept) -5.475424e-14
#> funding 1.013262e+02
#> hs .
#> not-hs 1.228224e+01
#> college .
#> college4 .
Validación Cruzada Los parámetros \(t\) y/o \(\lambda\) controlan la complejidad del modelo, esto es, cuántos parámetros definen el modelo
Condición
Parámetro
Modelo
\(t\) grande
\(\lambda\) pequeña
\(\rightarrow\)
Complejo
\(t\) pequeña
\(\lambda\) grande
\(\rightarrow\)
Disperso
4.3.2.5 Selección del Parámetro Ridge con validación cruzada
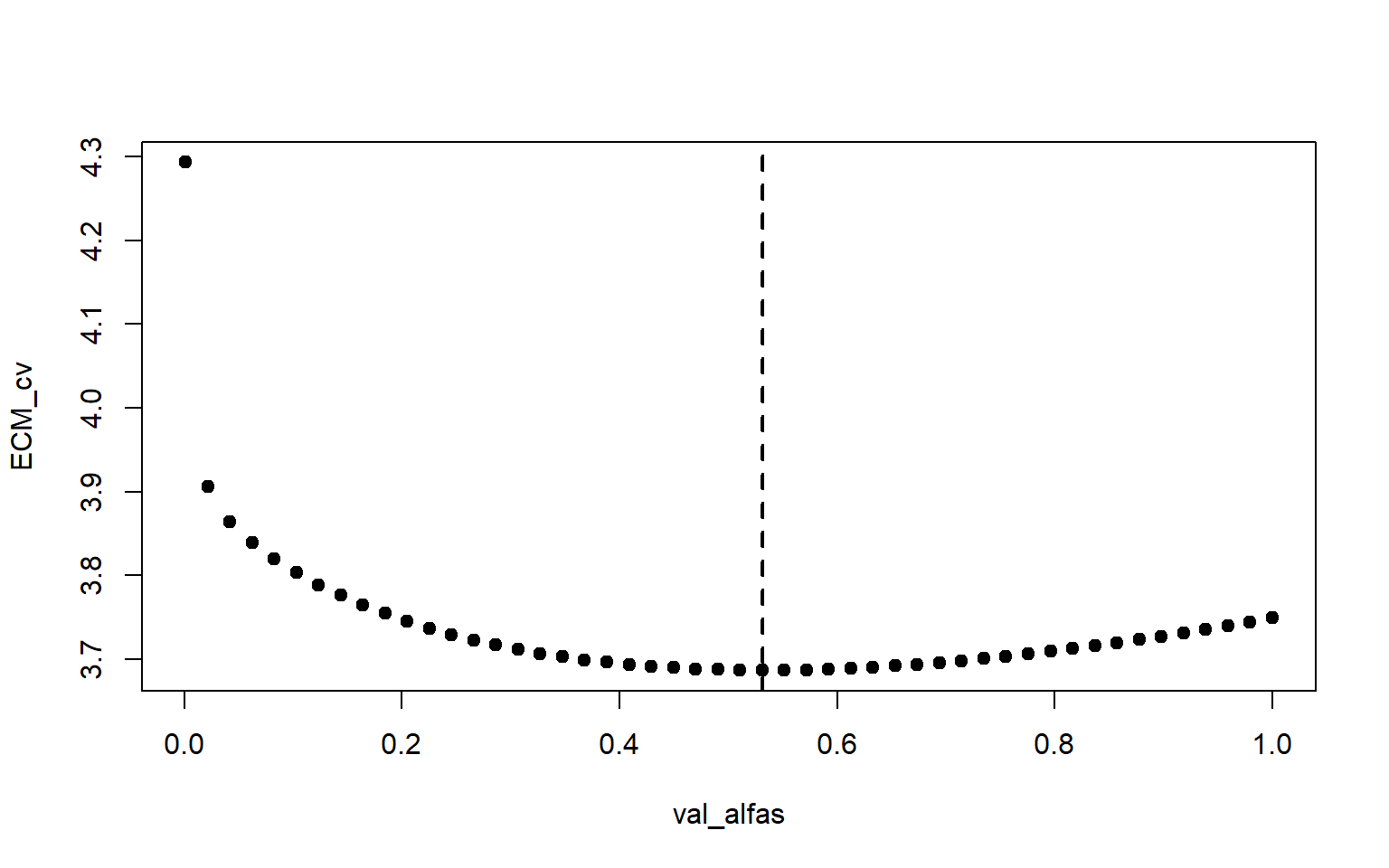
Como hemos visto con Lasso, el procedimiento de Validación Cruzada trata de elegir modelos que tengan buena precisión a la hora de predecir observaciones independientes (nuevas). En nuestro caso, esto se traduce en elegir el valor \(\lambda\) que muestra evidencia de ser óptimo para predicción.
Ilustramos ahora el \(k\)-fold usando la función cv.glmnet
En el ajuste de modelos de regresión lineal o logística, el “Elastic net” (Zou & Hastie, 2005) es un método de regresión regularizada que combina linealmente las penalizaciones \(L_1\) y \(L_2\) de los métodos lasso y ridge, respectivamente.
Formalmente el estimador de elastic net (EN) minimiza la función \[
\operatorname{EN}(\boldsymbol{\beta})=\sum_{i=1}^n\left(y_i-(X \boldsymbol{\beta})_i\right)^2+\lambda_1 \sum_{j=1}^k\left|\beta_j\right|+\lambda_2 \sum_{j=1}^k\left|\beta_j\right|^2 .
\] El término de penalización cuadrática hace que la función de pérdida sea fuertemente convexa, y por lo tanto tiene un mínimo único.
El método elastic net incluye Lasso y ridge regression como casos especiales: \((\lambda_1 = \lambda,\ \lambda_2 = 0)\) y \((\lambda_1 = 0,\ \lambda_2 = \lambda)\), respectivamente.
Una forma de estimar el parametro elastic net es encontrar un estimador mediante un procedimiento de dos etapas: primero, para cada valor fijo de \(\lambda_2\), se obtienen los coeficientes de la regresión ridge, y luego se realiza un tipo de ajuste de encogimiento Lasso.
glmnet : “Modelos lineales generalizados regularizados con lasso y elastic-net” (Hastie, Qian y Tay) es un software implementado como un paquete fuente de R y como una caja de herramientas en MATLAB. Incluye algoritmos rápidos para la estimación de modelos lineales generalizados con \(L_1\) (lasso), \(L_2\) (regresión ridge) y combinaciones de ambas penalizaciones (elastic net), utilizando un descenso de coordenadas cíclico, calculado a lo largo de un camino de regularización.
glmnet resuelve el problema \[
\underset{\boldsymbol{\beta_0, \beta}}{\arg \min }
\frac{1}{N} \sum_{i=1}^N w_i l\left(y_i, \beta_0+\beta^T x_i\right)+\lambda\left[(1-\alpha)\|\beta\|_2^2 / 2+\alpha\|\beta\|_1\right]
\] sobre una malla de valores de \(\lambda\) que cubre el rango de posibles soluciones. Aquí, \(l\left(y_i, \eta_i\right)\) es la contribución de la verosimilitud negativa para la observación \(i\). Por ejemplo, en el caso Gaussiano es \[
l\left(y_i, \eta_i\right)=\frac{1}{2}\left(y_i-\eta_i\right)^2.
\] La penalización del elastic net está controlada por \(\alpha\) y constituye un puente entre la regresión lasso (\(\alpha=1\), el valor de default) y la regresión ridge (\(\alpha=0\)). El parámetro de ajuste \(\lambda\) controla la intensidad general de la penalización.
Se sabe que la penalización ridge reduce los coeficientes de predictores correlacionados entre sí, mientras que la lasso tiende a elegir uno de ellos y descartar los demás.
La penalización elastic net combina ambos enfoques: si los predictores están correlacionados en grupos, un \(\alpha=0.5\) tiende a seleccionar o excluir por completo al grupo entero de características. Este es un parámetro de nivel superior, y los usuarios pueden escoger un valor de antemano o experimentar con varios valores.
Un uso de \(\alpha\) es para la estabilidad numérica; por ejemplo, el elastic net con \(\alpha=1-\epsilon\) para un \(\epsilon>0\) pequeño se comporta de manera similar a lasso, pero elimina cualquier degeneración o comportamiento errático causado por correlaciones extremas.
Los algoritmos glmnet utilizan un descenso de coordenadas cíclico, que optimiza sucesivamente la función objetivo sobre cada parámetro, manteniendo los otros fijos, y recorre el proceso repetidamente hasta la convergencia.
El paquete también utiliza las reglas fuertes para restringir de manera eficiente el conjunto activo.
NotaEjemplo: Lasso, Ridge y Elastic Net
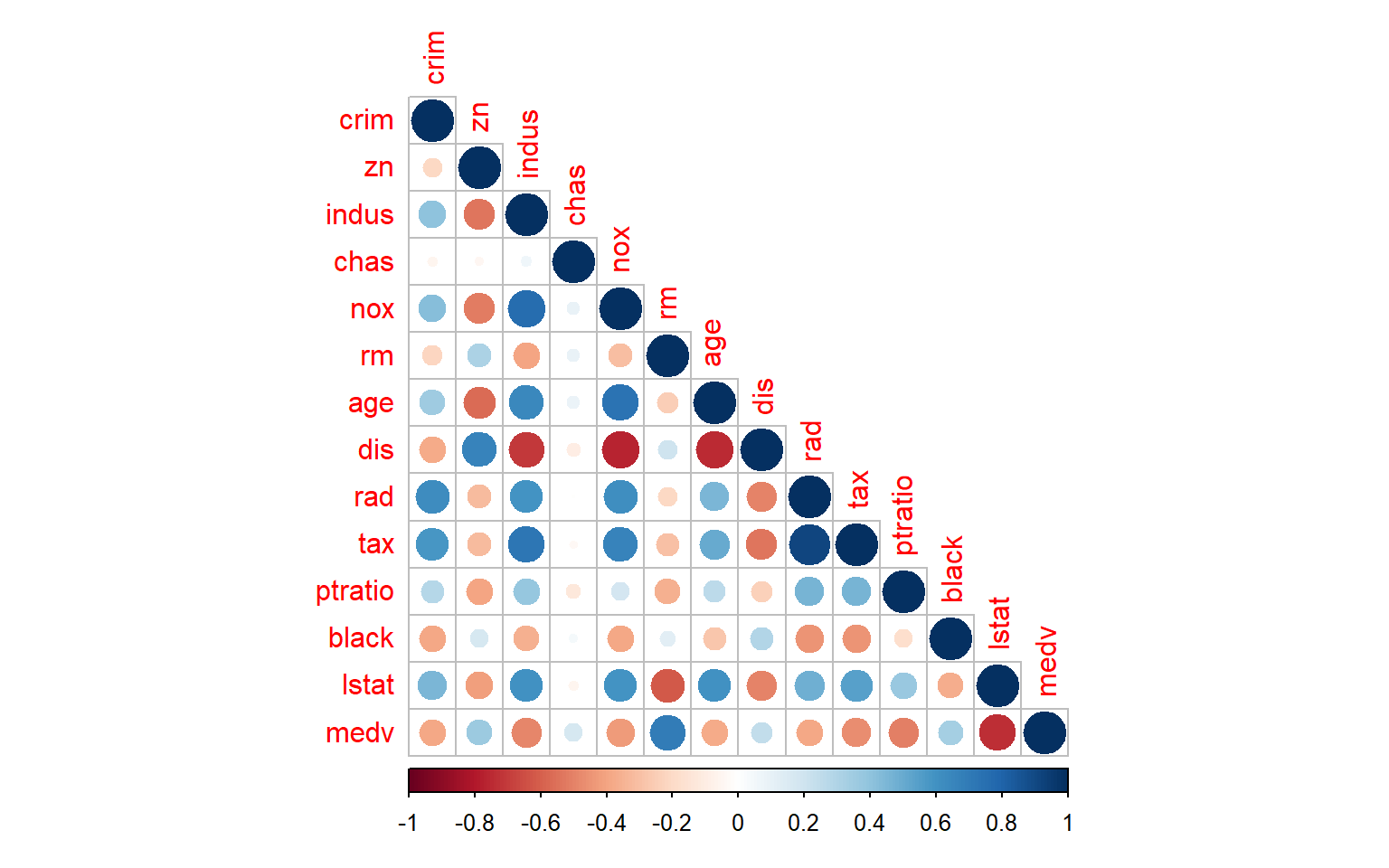
Usamos los datos “boston” que es un conjunto de datos que contiene los valores de las viviendas en 506 suburbios de Boston.
‘crim’: Tasa de criminalidad per cápita por localidad.
‘zn’: Proporción de terrenos residenciales zonificados para lotes de más de 25,000 pies cuadrados.
‘indus’: Proporción de acres de negocios no minoristas por localidad.
‘chas’: Variable categorica del río Charles (= 1 si el tramo limita con el río; 0 en caso contrario).
‘nox’: Concentración de óxidos de nitrógeno (partes por cada 10 millones).
‘rm’: Número promedio de habitaciones por vivienda.
‘age’: Proporción de unidades ocupadas por sus propietarios construidas antes de 1940.
‘dis’: Media ponderada de distancias a cinco centros de empleo de Boston.
‘rad’: Índice de accesibilidad a carreteras radiales.
‘tax’: Tasa impositiva de propiedades con valor completo por cada $10,000.
‘ptratio’: Proporción de alumnos por maestro por localidad.
‘black’: \(1000(Bk - 0.63)^2\), donde \(Bk\) es la proporción de personas negras por localidad.
‘lstat’: Estatus bajo de la población (porcentaje).
‘medv’: Valor mediano de las viviendas ocupadas por sus propietarios en miles de dólares ($1000s).
Establecemos datos para ajuste y prueba (training and testing)
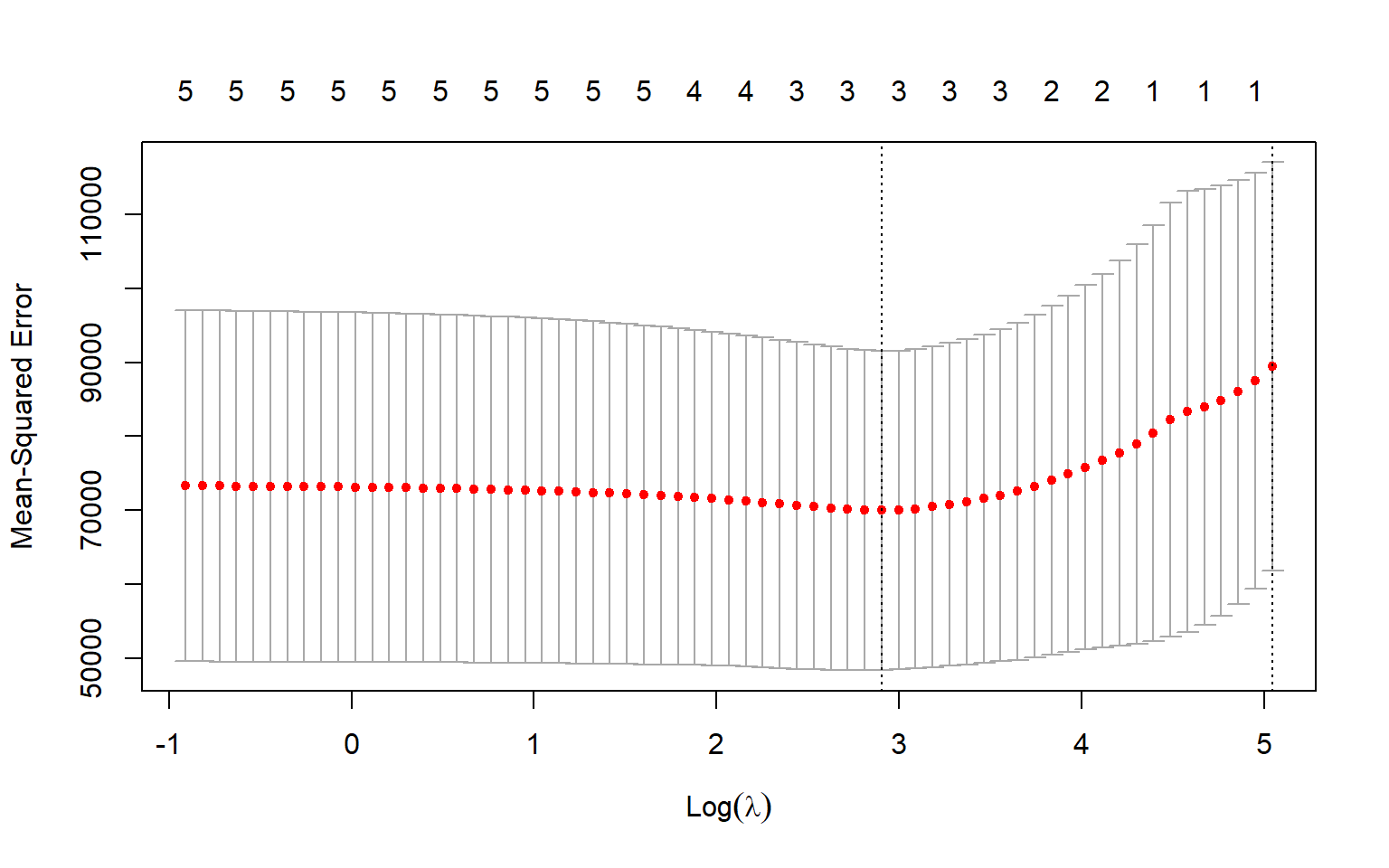
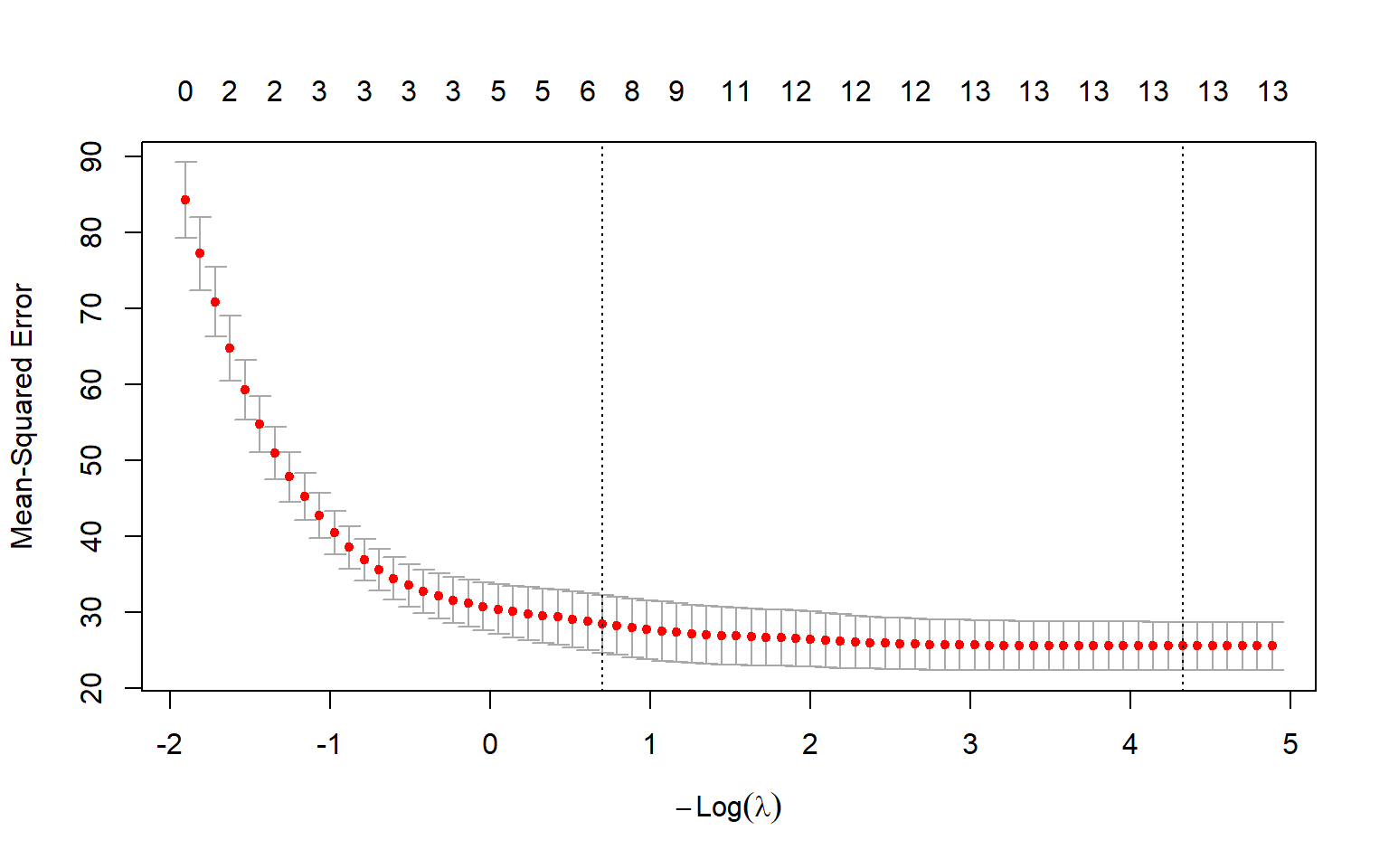
Código
predictors<-names(Boston)[!names(Boston)%in%"medv"]# ?createDataPartitionset.seed(667)inTrainingSet<-createDataPartition(Boston$medv, p =0.8, list =FALSE)# p es la proporcion que va a "training"train<-Boston[inTrainingSet, ]test<-Boston[-inTrainingSet, ]x=train[,predictors]y=train$medv# glmnet pide una matrix como inputx_train<-model.matrix(~.-1, train[,predictors])# Si no hubiera variables categoricas, se puede usar:#x_tran = as.matrix(x)
Código
## Ajuste de elastic netset.seed(333)fit_EN=glmnet(x_train, y, family ="gaussian", alpha =0.8, nfold=3,parallel=TRUE, standardize=TRUE, type.measur='auc')plot(fit_EN)
En ese ejemplo se grafica también la fracción de la desviación explicada como una forma para evaluar los modelos.
La desviación (Deviance, en inglés) es un concepto clave en los modelos lineales generalizados. Intuitivamente, \(\left(\boldsymbol{x}_i,Y_i\right), \ i=1,\ldots,n\) mide la desviación del modelo lineal generalizado instalado con respecto a un modelo perfecto para la muestra. Este modelo perfecto, conocido como el modelo saturado, es el modelo que mejor se ajusta a los datos, en el sentido de que las respuestas ajustadas \(\left(\widehat{Y}_i\right)\) se aproxima más a las observaciones \(\left({Y}_i\right)\).
Formalmente, la desviación \(D\) se define a través de la diferencia de las logverosimilitudes del modelos ajustados \(\ell\left(\widehat{\boldsymbol{\beta}}\right)\) y el modelo saturado, \(\ell_s\): \[
D:=-2\left[\ell(\hat{\boldsymbol{\beta}})-\ell_s\right].
\] Como \(\ell\left(\widehat{\boldsymbol{\beta}}\right)\leq \ell_s\), tenemos que \(D\geq 0\).
Bibliografía:
Montgomery, D. C., Peck, E. A., & Vining, G. G. (2021). Introduction to linear regression analysis. John Wiley & Sons.
Hastie, T., Tibshirani, R., & Wainwright, M. (2016). Statistical learning with sparsity: The Lasso and Generalizations. Monographs on statistics and applied probability, CRC 143(143), 8. Libro descargable
Referencias:
Hoerl, A. E., & Kennard, R. W. (1970). Ridge regression: Biased estimation for nonorthogonal problems. Technometrics, 12(1), 55-67.
Wright, Stephen J. (2015). “Coordinate descent algorithms”. Mathematical Programming.
Wu, T. T., & Lange, K. (2008). Coordinate descent algorithms for lasso penalized regression. ArXiv
Zou, Hui; Hastie, Trevor (2005). Regularization and Variable Selection via the Elastic Net. Journal of the Royal Statistical Society, Series B. 67 (2): 301–320.