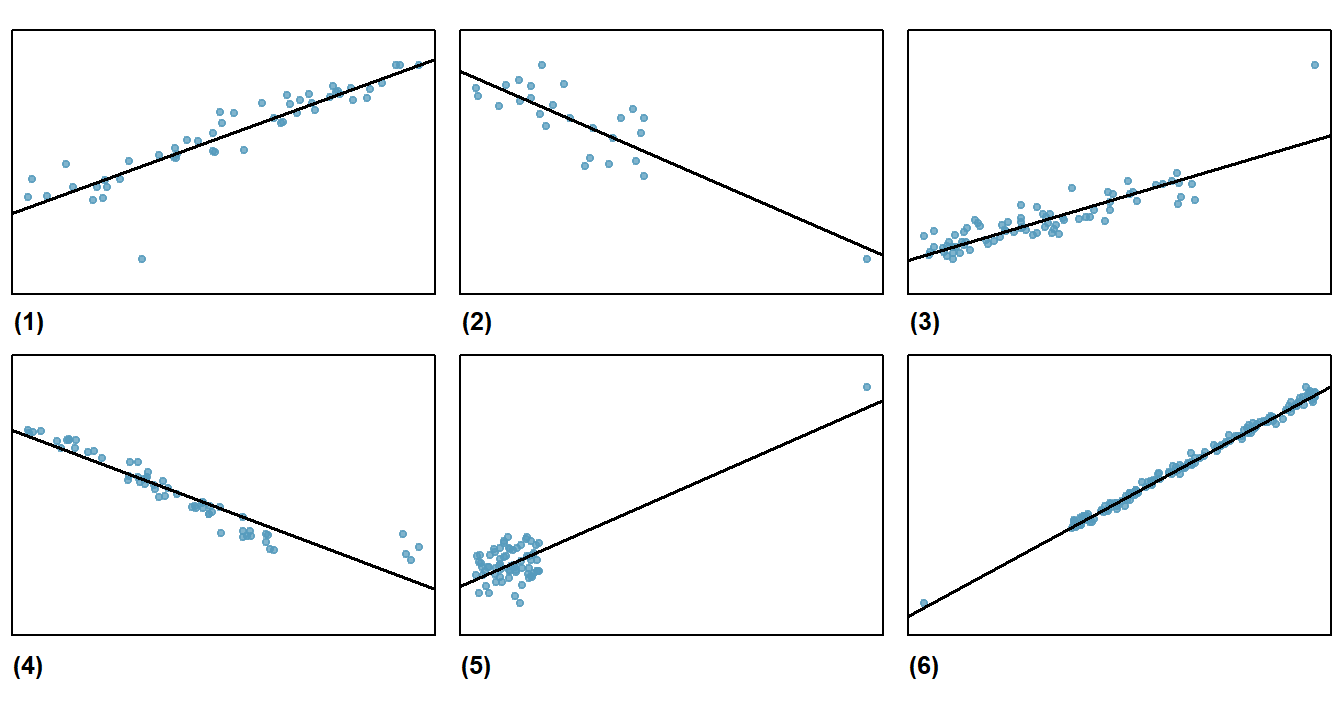
El cuarteto de Anscombe, publicado en 1973 por el estadístico Francis John Anscombe, fue obtenido con el fin de demostrar la importancia de analizar la calidad del modelo estimado desde diferentes perspecitivas, incluyendo su analisis gráfico.
Estos datos compartes las siguientes características:
Propiedad
Valor
Media de cada una de las variables \(x\)
9.0
Varianza de cada una de las variables \(x\)
11.0
Media de cada una de las variables \(y\)
7.5
Varianza de cada una de las variables \(y\)
4.12
Correlación entre cada una de las variables \(x\) e \(y\)
0.816
Recta de regresión
\(y=3+0.5 x\)
\(R^2\)
\(\sim 0.67\)
Como en el caso de multiples covariables, la verificación gráfica también representa retos significativos, en este capítulo presentamos algunas de las herramientas más importantes para verificar el cumplimiento o violación a los supuestos del modelo. Esto es fundamental para evaluar la calidad de la inferencia que se obtiene, los problemas potenciales y las modificaciones al modelo que pueden implementarse para resolverlos.
Existen formas de verificación del modelo visuales y numéricas. En primer lugar nos interesa verificar que no hay una violación importante al supuesto del modelo de regresión. Algunos problemas potenciales son:
Suposiciones sobre la estructura del error. Asumimos que:
los errores están distribuidos normalmente,
son independientes y
tienen tienen varianza constante (errores homocedásticos).
Suposiciones sobre el ajuste. Asumimos que el ajuste del modelo es correcto.
Problemas con valores atípicos y puntos de influencia. En este caso, un pequeño número de puntos en los datos podría tener un impacto inusualmente grande en las estimaciones de los parámetros. Estos puntos pueden dar una falsa impresión de que nuestro modelo tiene un buen ajuste o, por el contrario, de que no existe relación entre las variables.
2.1 Análisis de residuos
2.1.1 Residuos estandarizados
El análisis de los residuos de regresión, o alguna transformación de los residuos, es muy útil para detectar deficiencias en el modelo o problemas en los datos. Se asume que los verdaderos errores en el modelo de regresión son variables aleatorias normalmente distribuidas e independientes con media cero y varianza común, \[
\boldsymbol{\epsilon} \sim N\left(\mathbf{0}, \sigma^2 I_n \right).
\] Sin embargo, los residuos observados no son independientes y no tienen varianza común, incluso cuando se cumple la suposición \(\sigma^2 I_n\). Bajo las suposiciones usuales de mínimos cuadrados, \[
\boldsymbol{e}=(I_n-P) \boldsymbol{Y} \sim N_n\left(\mathbf{0},\ \sigma^2(I_n-P) \, \right).
\] En general, los elementos diagonales de \(\operatorname{Var}(\boldsymbol{e})\) no son iguales, por lo que los residuos observados no tienen varianza común y por otro lado, los elementos fuera de la diagonal no son cero, por lo que no son independientes.
Las varianzas heterogéneas en los residuos observados se corrigen fácilmente estandarizando cada residuo con su desviación estándar, pero ya que las varianzas son desconocidas, estimamos la varianza de los residuos como \(s^2 (I_n-P)\). Los residuos estandarizados se obtienen al dividir cada residuo por su desviación estándar. Los denotamos como \(r_i\). Esto es, \[
r_i=\frac{e_i}{s \sqrt{\left(1-h_{i i}\right)}},
\tag{2.1}\] donde \(h_{i i}\) es el \(i\)-ésimo elemento diagonal de \(P\).
Todos los residuos estandarizados (con \(\sigma\) en lugar de \(s\) en el denominador) tienen varianza unitaria. Pero \(\{r_i\}\) se comportan de manera similar a una variable aleatoria \(t\) de Student. La distribución no es exacta ya que el numerador y el denominador de \(r_i\) no son independientes.
2.1.2 Residuos “Studentizados”
Con el fin de que los términos del numerador y denominador fueran independientes, Belsley, Kuh, and Welsch (1980) sugirieron estandarizar cada elemento del vector de residuales con su desviación estándar pero forzar a que sea independiente considerando que para cada \(r_i\), la desviación estándar considerada está basada en las \(n_1\) observaciones de \(e\)’s que omiten justamente a \(e_i\). Esto es, \[
r_i^*=\frac{e_i}{s_{(i)} \sqrt{1-v_{i i}}}
\] con \[
s_{(i)}=\frac{\sum_{j\ne i}(e_i-\overline{\boldsymbol{e}})^2}{n-p-1}
\] Cada residual “Studentizado” \(r_i^*\) se distribuye \(t(n-p-1)\).
Nota: Los nombres de los residuales no son estándares y en algunos trabajos los residuales estandarizados, \(r_i\), se llaman como “Studentizados” y en otros trabajos a \(r_i^*\) se les denominan como residuales de verificación cruzada o jacknife.
2.1.3 Gráficas de Residuos
Las suposiciones sobre la estructura del error pueden verificarse visualmente con gráficos de residuos.
En R se pueden obtener algunas de estas gráficas aplicando la función plot() a un objeto lm. Este comando proporciona seis gráficos que nos permiten evaluar visualmente las suposiciones de un modelo lineal:
gráfico de residuos contra valores ajustados,
gráfico de escala-ubicación de \(\sqrt{|e|}\) contra valores ajustados,
gráfico Q-Q normal,
gráfico de residuos contra las palancas,
gráfico de distancias de Cook contra las etiquetas de las filas, y
gráfico de distancias de Cook contra leverage/(1-leverage).
Por defecto, los cuatro primeros se obtienen al aplicar plot().
NotaEjemplo: Grafica de diagnostico de R con plot()
Figura 2.1: Graficas de diagnosticos de R para objetos lm
2.1.4 Residuales Vs valores ajustados
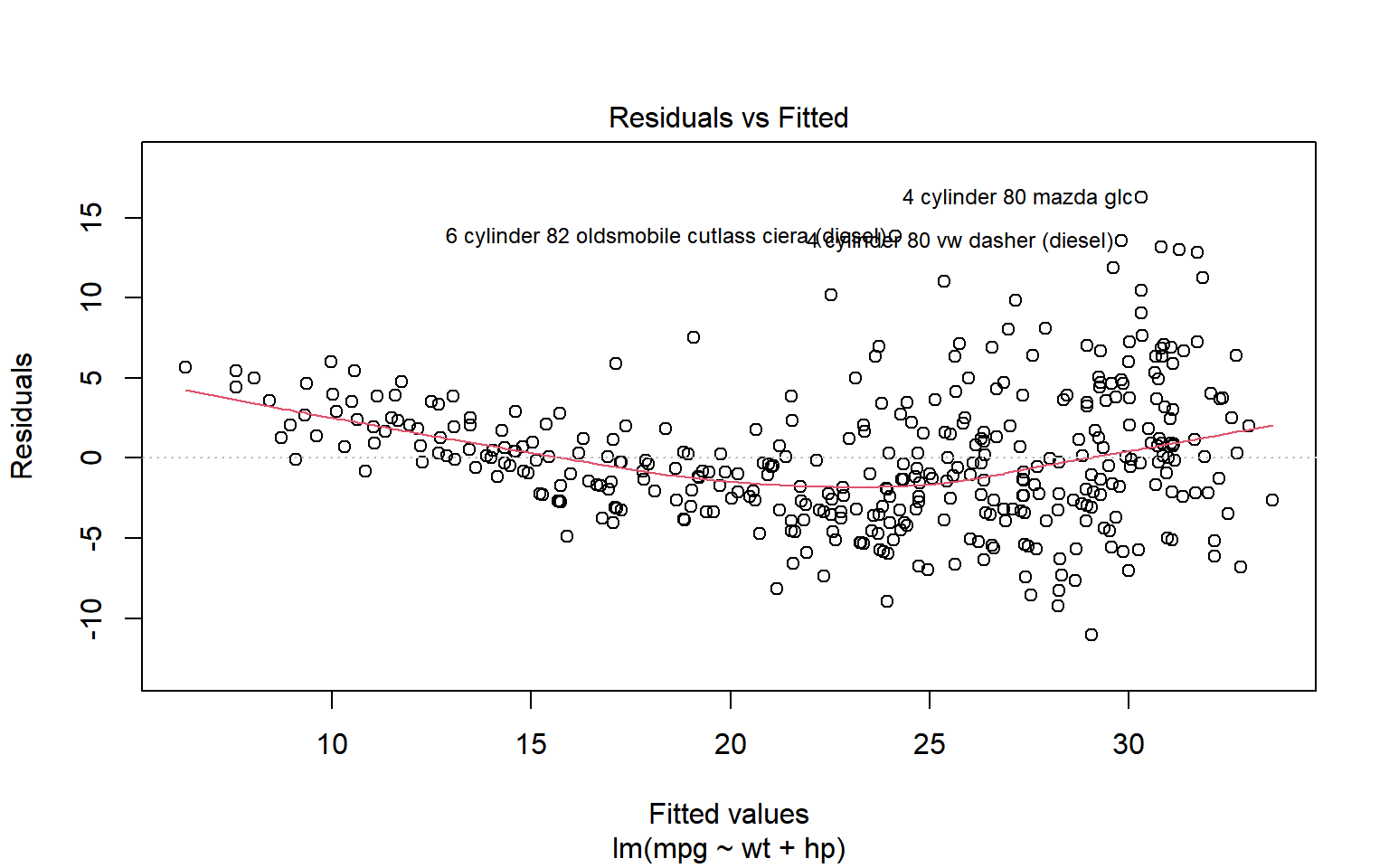
Este gráfico evalúa la linealidad del modelo y la homocedasticidad de los errores. La línea roja es una estimación suavizada de los valores ajustados frente a los residuos.
NotaEjemplo: Grafica 1 de plot.lm(): Residuos Etandarizados Vs valores ajustados
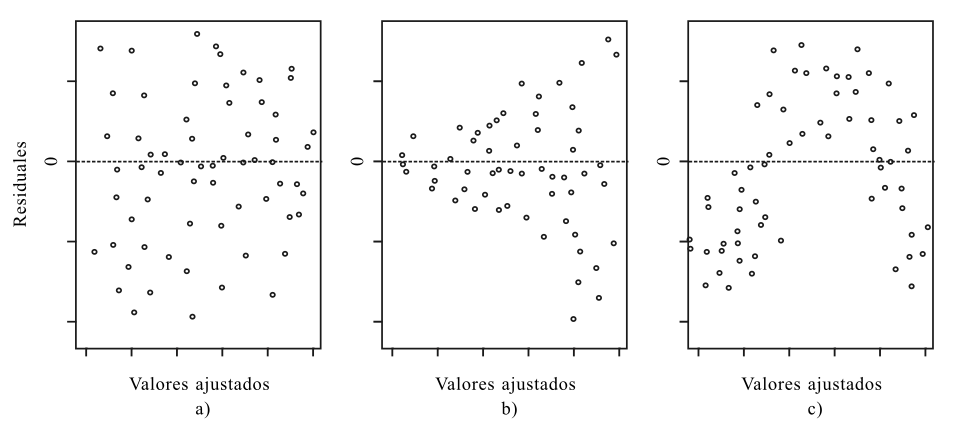
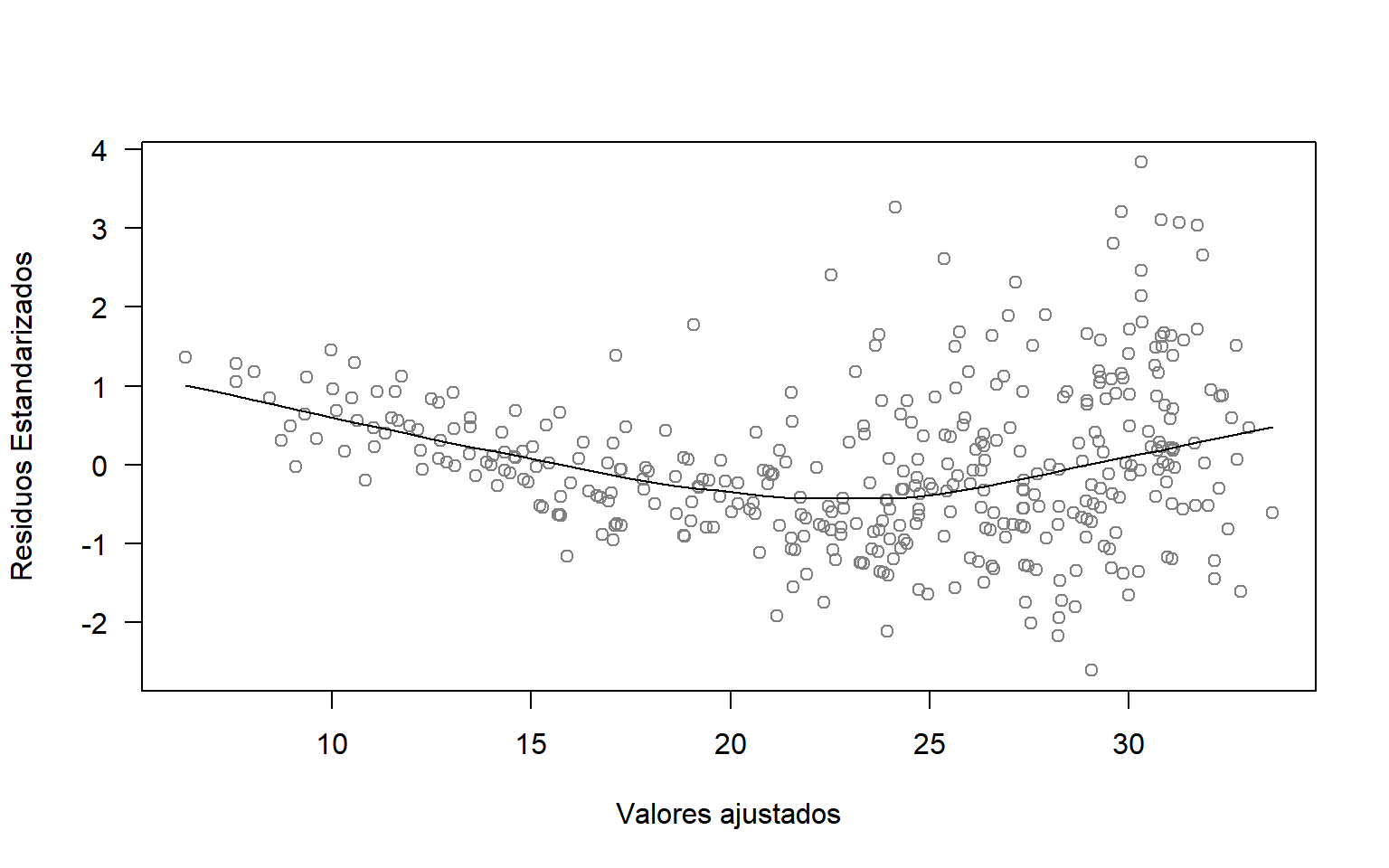
Idealmente, la línea roja debería coincidir con la línea horizontal punteada y los residuos deberían centrarse alrededor de esta línea discontinua (como en la Figura 2.3 a). Esto indicaría que un ajuste lineal es apropiado. Además, la dispersión alrededor de la línea discontinua debería ser relativamente constante en todo el gráfico, lo que indicaría homocedasticidad. En este caso, parece que hay alguna preocupación menor sobre la linealidad y la varianza del error no constante.
Nota: los puntos que están etiquetados son puntos con un valor residual alto. Son extremos. Discutiremos los valores atípicos y los puntos de influencia más adelante.
Figura 2.3: Casos de Residuales Vs valores ajustados
En la Figura 2.3, el caso b apunta hacia la heterocedasticidad en los errores y el c) en que el modelo considerado es inadecuado ya que prevalece en los errores una relación de los residuales y los valores ajustados. Esto sugiere un cambio en el modelo.
Para probar si la constancia es o o no variable se podria considerar el siguiente codigo:
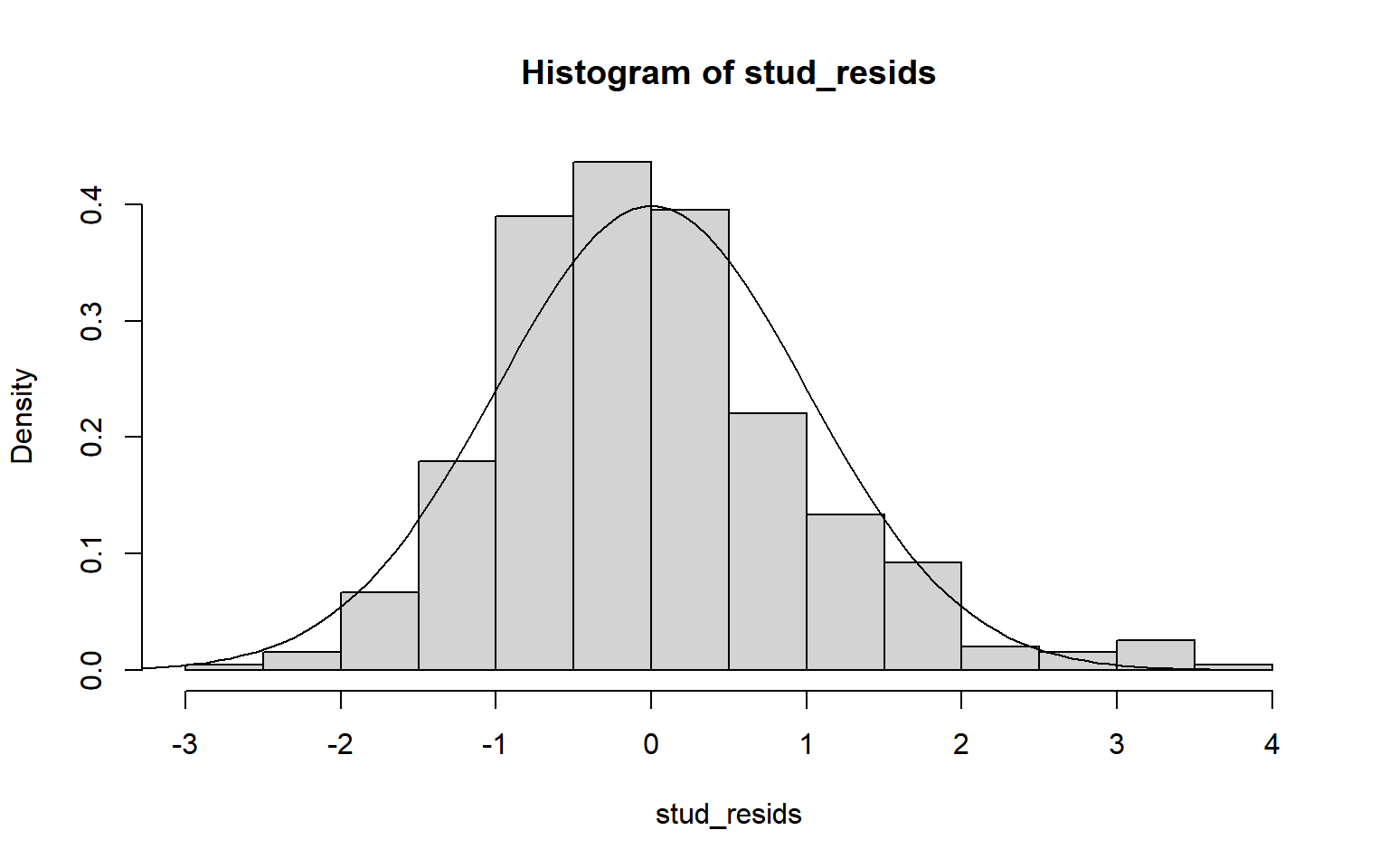
pero ni la distribución ni grados de libertad son exactos, como comentamos arriba. Podemos mejor indagar en la distribución de los residuos ‘Studentizados’.
NotaEjemplo: Grafica Residuos Etandarizados Vs valores ajustados
Los residuos studientizados se pueden obtener con la función studres del paquete MASS o con la función rstandard
Código
#### Ejemplo: Prueba de homocedasticidadscatter.smooth(rstandard(modelo_reducido)~fitted(modelo_reducido), col=grey(0.5),las=1, ylab="Residuos Estandarizados", xlab="Valores ajustados")
Figura 2.4: Grafica de residuos Studentizados Vs valores ajustados
Figura 2.5: Distribución empírica de los residuos Studentizados
2.1.5 Gráfica Q-Q
Los gráficos Q-Q (cuantil-cuantil) comparan dos distribuciones de probabilidad mediante el trazado de sus cuantiles uno contra el otro. Un gráfico Q-Q se utiliza para comparar las formas de las distribuciones, proporcionando una vista gráfica de cómo las propiedades, como la ubicación, la escala y la asimetría, son similares o diferentes en las dos distribuciones.
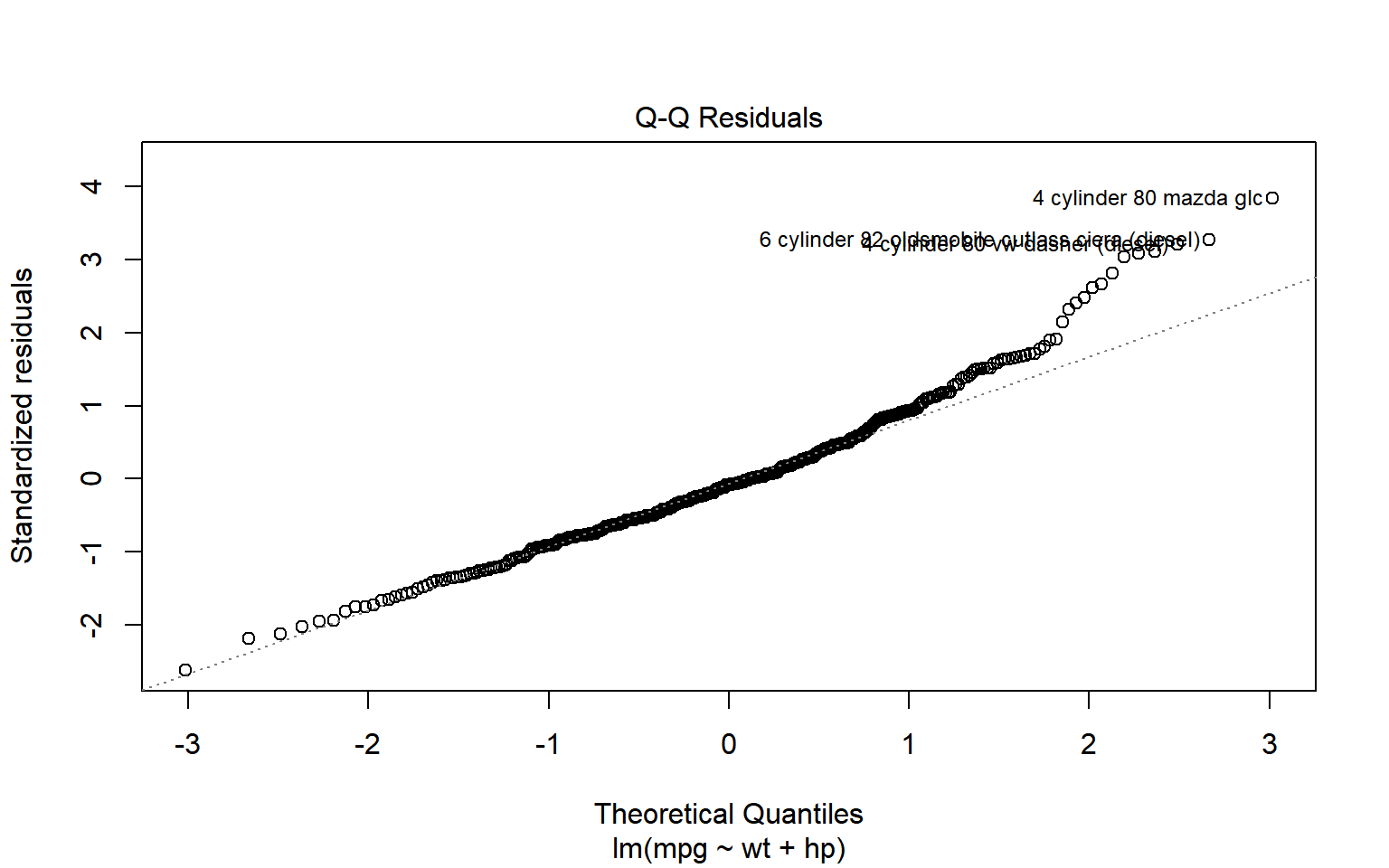
De acuerdo con R_plot_lm, la gráfica Q-Q aplicada a objetos lm obtiene la grafica cuantil-cuantil de los residuos estandarizados reales: \[
r_i=\frac{e_i}{s \sqrt{\left(1-h_{i i}\right)}},
\] y la distribución Normal estándar.
Idealmente, los puntos deberían caer a lo largo de la línea diagonal discontinua. En la figura obtenida para el ajuste hecho a los datos de carros parece que hay cierta asimetría hacia la izquierda o simplemente colas más largas que una distribución normal.
Figura 2.6: Residuales ‘estandarizados’ contra Y ajustada
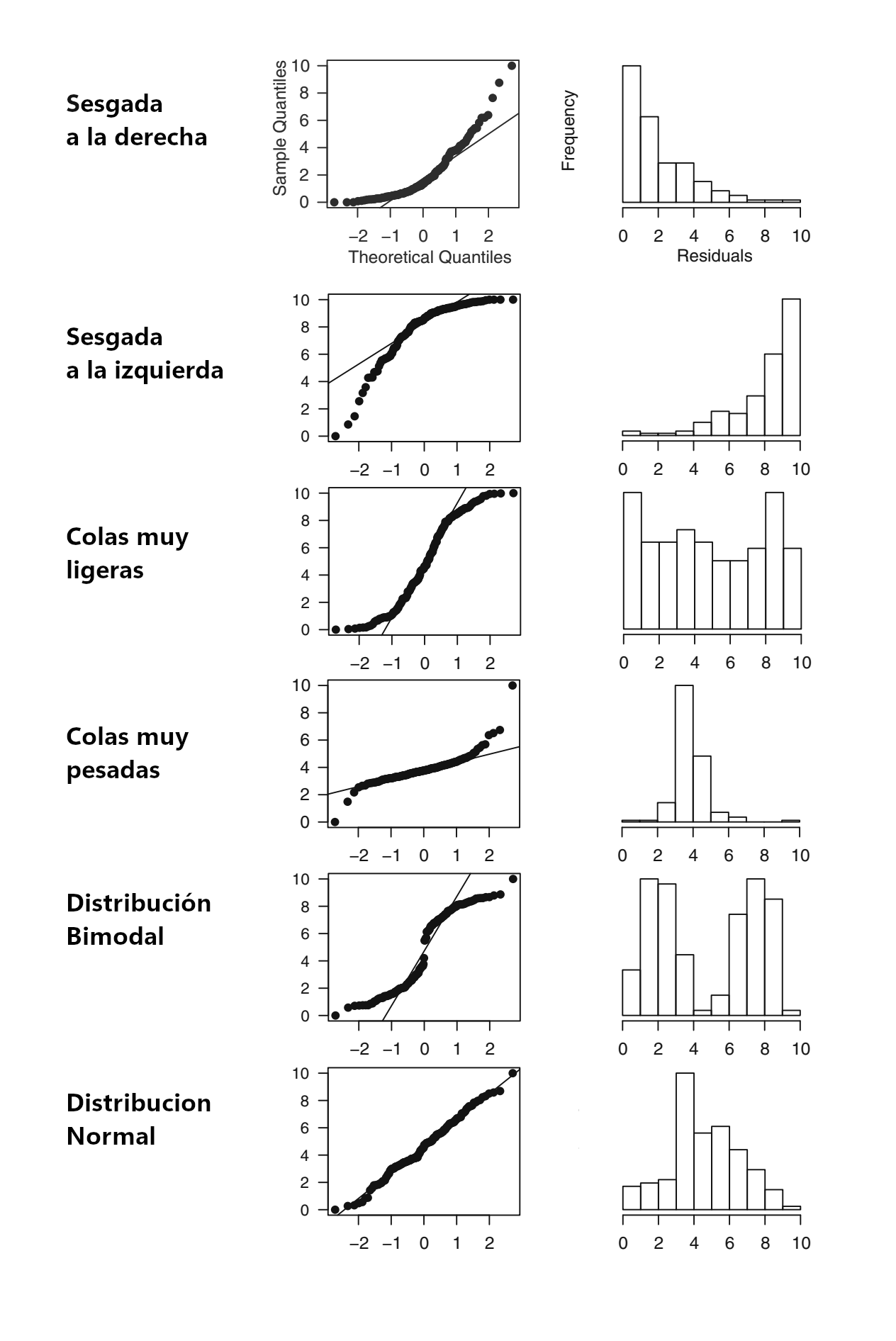
La siguiente figura presenta algunos casos de gráficas Q-Q para ilustrar como se relacionan sus formas y desviaciones de la recta con la forma de en que la distribución observada se desvía de la Normal.
Figura 2.7: Algunos casos de gráficas Q-Q
Prueba de Anderson-Darling
La prueba Anderson-Darling de bondad de ajuste es una de las pruebas basadas en la función de distribución empírica. Esta cuantifica la discrepancia entre las distribuciones teórica y empírica. Una forma general de medir esta discrepancia es mediante: \[
A^2=n \int_{-\infty}^{\infty}\left[F_n(x)-F(x)\right]^2 \psi(x) f(x) d x
\] donde \(F_n(x)\) es la función de distribución empírica, \(F(x)\) es la función de distribución teórica o hipotetizada, \(\psi(x)\) es una función ponderadora y \(f(x)\) es la densidad teórica. El caso especial de la Anderson-Darling ocurre cuando se toma la función ponderadora como: \[
\psi(x)=\frac{1}{F(x)[1-F(x)]}.
\]
Sea \(y_1, \cdots, y_n\) una muestra aleatoria proveniente de cierta distribución. Si queremos probar la hipótesis \(H_0: y \sim F\), el estadístico \(A^2\) toma la forma \[
A^2=-n-\frac{1}{n} \sum_{i=1}^n(2 i-1)\left[\log \left(z_i\right)-\log \left(1-z_{n-i+1}\right)\right],
\tag{2.2}\] donde \(z_i=F\left(y_i ; \theta\right)\). La regla de decisión consiste en rechazar \(H_0\) para valores grandes de \(A^2\) (para lo cual, necesitaremos la distribución de \(A^2\) ).
La distribución de \(A^2\) depende de \(n\). Una forma de tener un solo juego de cuantiles críticos es usar la siguiente modificación: \[
A_*^2=A^2\left(1+\frac{0.75}{n}+\frac{2.25}{n^2}\right)
\] Basados en \(A_*^2\) tenemos algunos cuantiles convenientes para pruebas de bondad de ajuste:
\(90 \%\)
\(95 \%\)
\(97.5 \%\)
\(99 \%\)
0.631
0.752
0.873
1.035
Para ver con más detalle la derivación de la expresión (2.2) y los cuantiles en la tabla anterior, ver Sección F.1
NotaEjemplo: Prueba Anderson-Darling para Normalidad
Código
#install.packages('nortest') #Anderson-Darling para normalidadlibrary(nortest)ad.test(modelo_reducido$residuals)
#>
#> Anderson-Darling normality test
#>
#> data: modelo_reducido$residuals
#> A = 2.425, p-value = 3.85e-06
Para este ejemplo entonces no podemos rechazar la hipótesis nula que indica que los datos tienen distribución Normal.
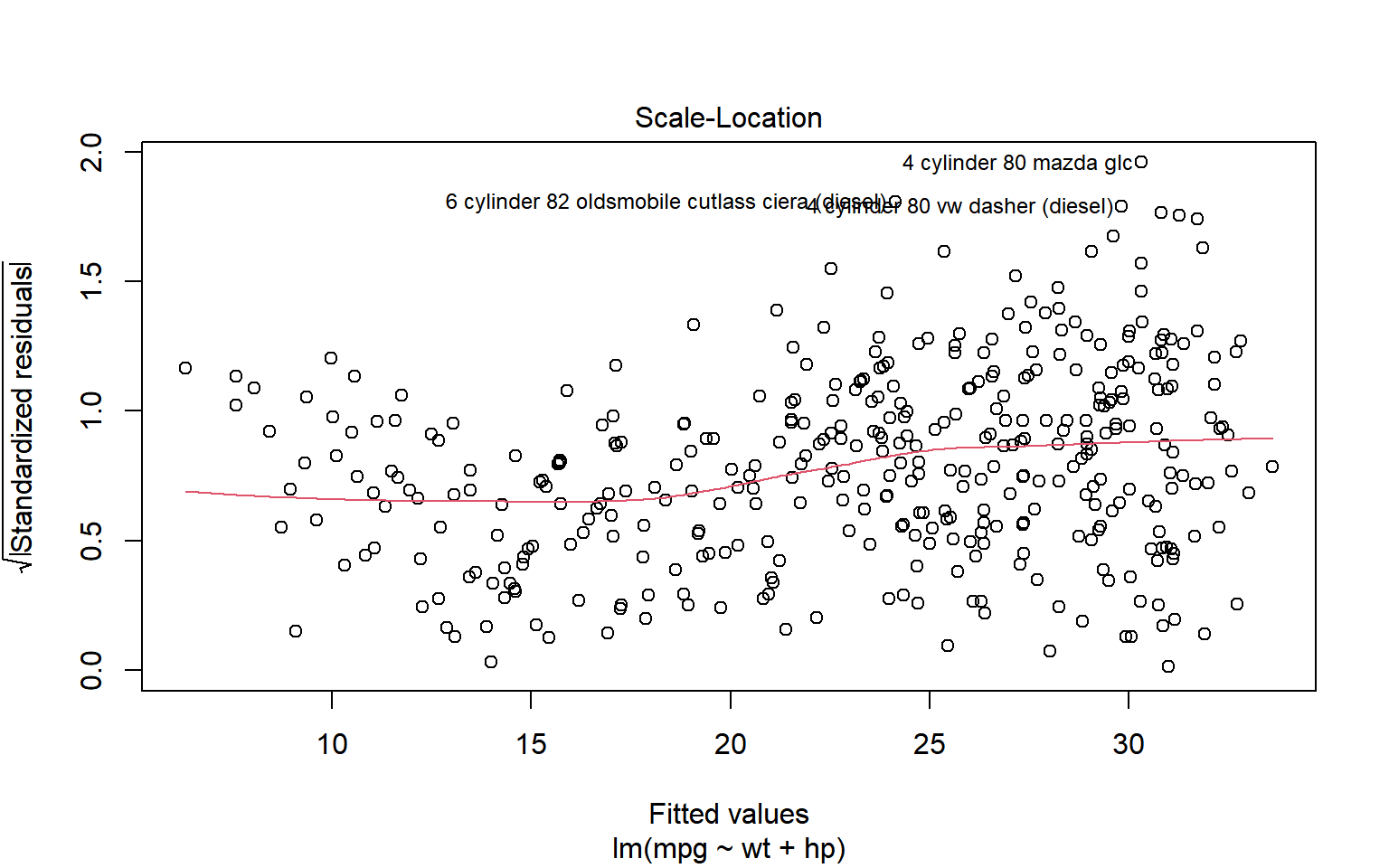
2.1.6 Gráficas escala-ubicación
El gráfico de escala-ubicación busca evaluar si la varianza del error no constante. Los residuos estandarizado que se consideran son meramente los residuales divididos por su desviación estándar: \[
e^{\prime}_i=\frac{e_i}{s}
\] La grafica presenta las raices cuadradas de los valores absolutos de los residuales, con el fin de disminuir su sesgo. De estas técnicas hablaremos más adelante.
Una linea horizontal roja indica errores homocedásticos.
NotaEjemplo: Grafica 3 de plot.lm(): Escala-ubicación
Figura 2.8: Residuales ‘estandarizados’ contra Y ajustada
2.2 Observaciones influyentes
En esta sección discutimos dos tipos de datos que pueden influir fuertemente en la calidad del modelo ajustado. Estos datos son
puntos atípicos (aberrantes o outliers). Son datos que se alejan del resto de conjunto de datos.
puntos influyentes (palanca). Son datos atípicos con una influencia grande en los resultados del ajuste.
No existe una definición precisa de un dato atípico, sino que la clasificación obedece la observación de si son observaciones que caen lejos de la “nube” de puntos.
Un valor atípico puede ser en la variable de respuesta o en alguna(s) variable(s) explicativa. Se denomia, en cualquiera de los dos casos, influyente si altera drásticamente los resultados de la regresión. Por ejemplo, causando grandes cambios en la pendiente estimada o en los \(p\) valores de las hipótesis, si se omite.
En el caso de regresión lineal simple, es fácil detectar cuales puntos son influyentes pues gráficas sencillas como las anteriores los mostrarán. En el caso multivariado no es obvio ver cuales puntos son influyentes pues no es suficiente con ver las distribuciones marginales de las variables (Ej. haciendo grafica de puntos de \(Y\) contra cada covariable o histogramas para cada covariable).
Los puntos atípicos, que potencialmente son influyentes son los puntos de datos que están en los bordes de la nube de puntos de muestra en el espacio \(X\). El elemento diagonal \(i\)-ésimo \(h_{i i}\) de la matriz de proyección \(P\) puede estar relacionado con la distancia del punto de datos \(i\)-ésimo al centroide del espacio \(X\). Esta medida de distancia tiene en cuenta la forma general de la nube de puntos de muestra. Por ejemplo, un punto de datos en el lado de una nube elíptica de puntos de datos tendrá un valor mayor de \(h_{i i}\) que otro punto de datos que se encuentre a una distancia similar del centroide pero a lo largo del eje mayor de la nube elíptica. El elemento diagonal \(i\)-ésimo de \(P\) se da por \[
h_{i i}=\boldsymbol{x}_i^{\top}\left(X^{\top} X\right)^{-1} \boldsymbol{x}_i
\tag{2.3}\] donde \(\boldsymbol{x}_i^{\top}\) es \(i\)-ésima fila de \(X\).
Las cotas de \(h_{i i}\) son \(1 / n \leq h_{i i} \leq 1\), y el límite inferior \(1 / n\) se alcanza solo si cada elemento en \(\boldsymbol{x}_i\) es igual a la media de esa covariable; en otras palabras, solo si el punto de datos se encuentra en el centroide. Si \(h_{ii} =1\) implica que la influencia del punto de datos es tan alta que obliga a la línea de regresión a pasar exactamente por ese punto.
El valor promedio de \(h_{ii}\) es igual a \(p/n\). ¿Por qué?
Estudios empíricos sugieren usar \[
h_{ii} > 2\frac{p}{n}
\] como punto de corte para identificar puntos palanca potenciales. (Ver Belsley, Kuh y Welsch de 1980).
Por otro lado, una forma de detectar puntos potencialmente influyentes es calcular su distancia al centroide de la nube de predictoras. La forma adecuada de calcular distancias es mediante la distancia de Mahalanobis (DM) y no la distancia Euclideana. La distancia de Mahalanobis es una “distancia estadística” que incorpora la correlación entre las predictoras.
En general, la distancia de Mahalanobis es una medida de distancia alternativa a las distancias euclídeas. Su utilidad radica en que es una forma de determinar la similitud entre dos variables aleatorias multidimensionales, teniendo en cuenta la correlación entre ellas.
Definición 2.1 (Distancia de Mahalanobis) La distancia de Mahalanobis entre dos variables aleatorias con la misma distribución de probabilidad se define formalmente como:
La distancia de Mahalanobis debe cumplir con tres propiedades, necesarias para ser una distancia, estas son: a) semipositividad, b) simetría y, c) desigualdad del triángulo.
En el caso de los modelos de regresión, nos interesa medir la distancia de Mahalanobis de cada una de las \(n\) observaciones, cada una con \(k\) covariables \(\boldsymbol{x}_i\) al centroide \(\overline{\boldsymbol{x}}\) usando una estimación de la matriz de precisión. A esta distancia la denotamos como \[
\text{DM}_i= \sqrt{(\boldsymbol{x}_i-\overline{\boldsymbol{x}})^{\top} (S^{\star})^{-1}(\boldsymbol{x}_i-\overline{\boldsymbol{x}})}.
\]
Proposición 2.1 (Relación entre \(\text{DM}_i\) y \(h_{ii}\))\[
h_{ii} = \frac{1}{n} + \frac{\text{DM}_i^2}{n-1}.
\]
Ahora, sea \(h_{ii}\) el \(i\)-ésimo elemento diagonal de la matriz de proyección sobre \(\mathcal{C}(X)\). Hagamos \(X=[\boldsymbol{1},X_1]\), donde \[
X_1 = \left[ \begin{array}{c} \boldsymbol{x}_1^{\top} \\ \boldsymbol{x}_2^{\top} \\ \vdots \\ \boldsymbol{x}_n^{\top} \end{array} \right]
\] donde \(\boldsymbol{x}_i\) es la \(i-\)ésima observación de las \(k\) covariables (observación reducida porque no incluye el 1 asociado a \(\beta_0\)). Entonces \[
h_{ii} = [1,\boldsymbol{x}_i^{\top}] \left( \left[ \begin{array}{c} \boldsymbol{1}^{\top} \\ X_1^{\top} \end{array} \right] [\boldsymbol{1},X_1] \right)^{-1}
\left[ \begin{array}{c}
1 \\ \boldsymbol{x}_i \end{array} \right] =
[1,\boldsymbol{x}_i^{\top}] \left[ \begin{array}{cc} n & \boldsymbol{1}^{\top} X_1 \\ X_1^{\top} \boldsymbol{1} & X_1^{\top} X_1 \end{array} \right]^{-1}
\left[ \begin{array}{c} 1 \\ \boldsymbol{x}_i \end{array} \right]=: [1,\boldsymbol{x}_i^{\top}] A^{-1}
\left[ \begin{array}{c} 1 \\ \boldsymbol{x}_i \end{array} \right]
\] haciendo \(A_{11} = n\), \(A_{12} = \boldsymbol{1}^{\top}X_1\), \(A_{21} = X_1^{\top} \boldsymbol{1}\) y \(A_{22} = X_1^{\top}X_1\), tenemos que el bloque inferior derecho de \(A^{-1}\) es la inversa de \[
\begin{align}
S_{2|1} &= A_{22} - A_{21}A_{11}^{-1}A_{12} \\
&= X_1^{\top}X_1 - X_1^{\top} \boldsymbol{1}\left( \frac{1}{n} \right) \boldsymbol{1}^{\top}X_1\\
&= X_1^{\top} \left(I_n - \frac{1}{n} J_{n} \right) X_1 \\
&= (n-1) S^{\star}.
\end{align}
\] donde \(S^{\star}\) es estimador de la matriz de covarianzas para las covariables en \(X_1\). Checa que la penúltima expresion generaliza las expresiones en los Ejemplos “2” y “Teorema D.4” de la Sección Formas Cuadráticas, en Apéndices. En particular, generalizamos (E.2) en el sentido que se tiene un matriz de observaciones de \(k\) variables. Esto es, estamos considerando \[
S^{\star}=\frac{X_1^{\top} \left(I_n - \frac{1}{n} J_{n} \right) X_1}{n-1}
\] con lo que tenemos que los estimadores de varianzas de la \(j\)-ésima covariable en \(X_1\) y las covarianzas de las covariables \(j\) y \(k\) son, respectivamente \[
\begin{align}
[S^{\star}]_{jj}=\widehat{\operatorname{Var}}(X_{1_j}) & =
\left(\sum_{i=1}^n [X_{1_j}]_i^2-\frac{\sum_{i=1}^n\sum_{w=1}^n[X_{1_j}]_i[X_{1_j}]_w}{n}\right)/(n-1)\\
&=\left(\sum_{i=1}^n [X_{1_j}]_i^2-n\overline{X}_{1_j}^{2}\right)/(n-1)\\[10pt]
[S^{\star}]_{jk}=\widehat{\operatorname{Cov}}(X_{1_j},X_{1_k}) &=\left(\sum_{i=1}^n [X_{1_j}]_i[X_{1_k}]_i-\frac{\sum_{i=1}^n\sum_{w=1}^n[X_{1_j}]_i[X_{1_k}]_w}{n}\right)/(n-1)\\
&=\left(\sum_{i=1}^n [X_{1_j}]_i[X_{1_k}]_i-n\overline{X}_{1_j}\,\overline{X}_{1_k}\right)/(n-1).
\end{align}
\] Regresando a los términos de \(A^{-1}\), obtenemos los restantes términos usando Proposición B.5 y Proposición B.6: \[
\left[ \begin{array}{cc} n & \boldsymbol{1}^{\top} X_1 \\ X_1^{\top} \boldsymbol{1} & X_1^{\top} X_1 \end{array} \right]^{-1} =
\left[ \begin{array}{cc} \frac{1}{n} + \overline{\boldsymbol{x}}^{\top} \frac{(S^{\star})^{-1}}{n-1} \overline{\boldsymbol{x}} & -\overline{\boldsymbol{x}}^{\top} \frac{(S^{\star})^{-1}}{n-1} \\ -\frac{(S^{\star})^{-1}}{n-1} \overline{\boldsymbol{x}} & \frac{(S^{\star})^{-1}}{n-1} \end{array} \right],
\tag{2.4}\] donde \(\overline{\boldsymbol{x}}\) es el vector de promedios de las \(k\) covariables presentes en \(X_1\).
Por ejemplo, verificamos que el primer de \(A^{-1}\) es como aparece en (2.4). Para esto, usamos Proposición B.6 con el fin de obtener la inversa de \(S_{1|2}\) (obtenida de Proposición B.5), \[
\begin{align}
S_{1|2}^{-1}&=\left(n- \boldsymbol{1}^{\top}X_1(X_1^{\top}X_1)^{-1}X_1^{\top} \boldsymbol{1}\right)^{-1}\\
&=\left(n- n\overline{\boldsymbol{x}}^{\top}(X_1^{\top}X_1)^{-1}n\overline{\boldsymbol{x}}\right)^{-1},
\end{align}
\] ya que \(\boldsymbol{1}^{\top}X_1=n\overline{\boldsymbol{x}}^{\top}\).
Ahora usando la Fórmula de Woodbury, considerando \(A=n\), \(U=- n\overline{\boldsymbol{x}}^{\top}\), \(V= n\overline{\boldsymbol{x}}\) y \(C=(X_1^{\top}X_1)^{-1}\), tenemos \[
\begin{align}
S_{1|2}^{-1}&=\frac{1}{n}+\frac{1}{n}n\overline{\boldsymbol{x}}^{\top}\left[(X_1^{\top}X_1)-n\overline{\boldsymbol{x}}\frac{1}{n}n\overline{\boldsymbol{x}}^{\top}\right]^{-1}n\overline{\boldsymbol{x}}\frac{1}{n} \\
&=\frac{1}{n}+\overline{\boldsymbol{x}}^{\top}\left[(X_1^{\top}X_1)-n\overline{\boldsymbol{x}}\overline{\boldsymbol{x}}^{\top}\right]^{-1}\overline{\boldsymbol{x}}\\
&=\frac{1}{n}+\overline{\boldsymbol{x}}^{\top}\left[(n-1)S^{\star}\right]^{-1}\overline{\boldsymbol{x}}\\
&=\frac{1}{n}+\overline{\boldsymbol{x}}^{\top}\frac{(S^{\star})^{-1}}{n-1}\overline{\boldsymbol{x}}
\end{align}
\] Se deja como ejercicio verificar las otras dos entradas en (2.4).
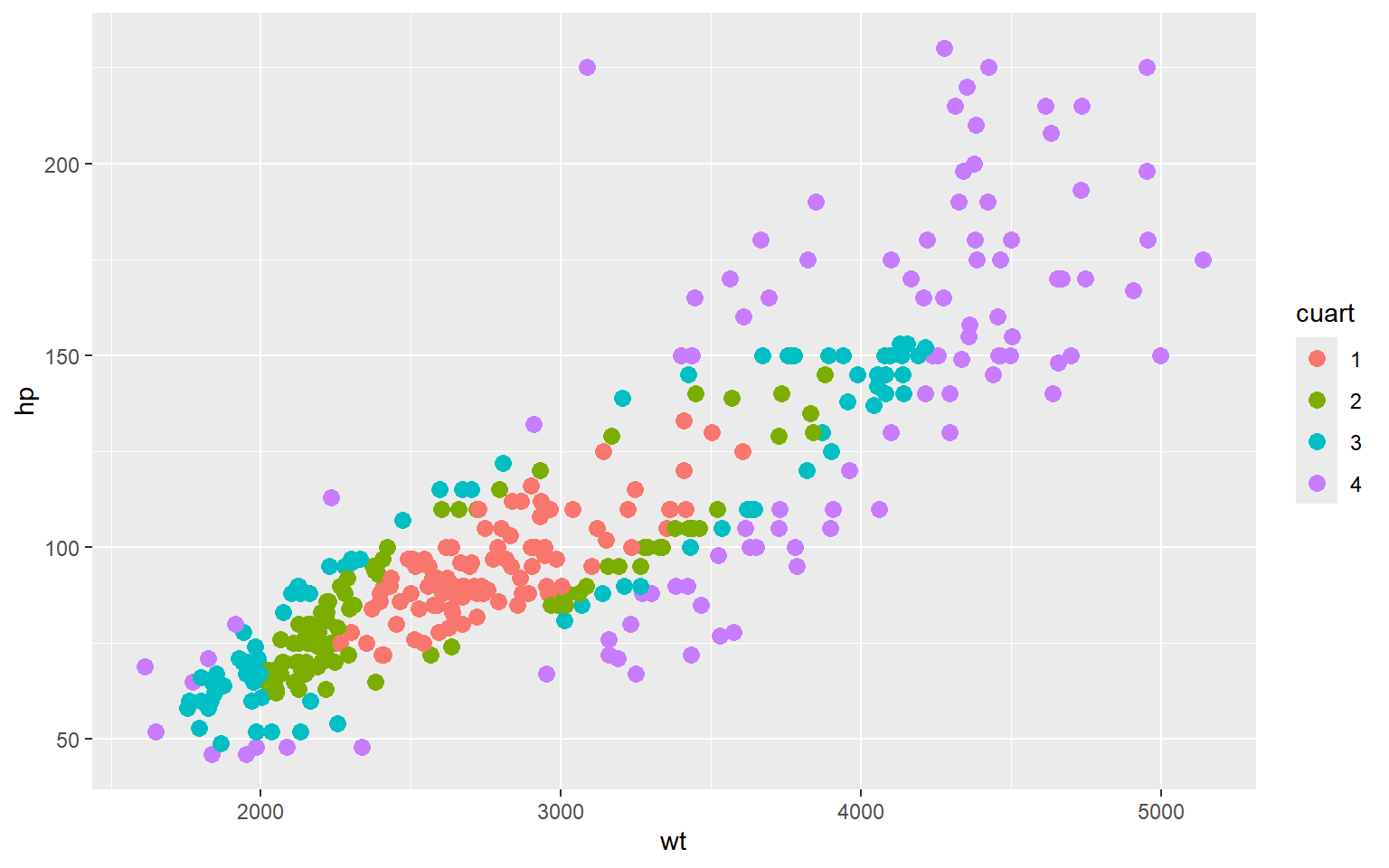
Figura 2.10: wt vs hp con colores según cuartil de \(h_{ii}\)
Los elementos diagonales de \(P\) solo identifican puntos de datos que están lejos del centroide del espacio de muestra \(X\). Tales puntos son potencialmente pero no necesariamente influyentes en determinar los resultados de la regresión. El procedimiento general para evaluar la influencia de un punto en un análisis de regresión es determinar los cambios que ocurren cuando se omite esa observación.
Se han desarrollado varias medidas de influencia utilizando este concepto. Se diferencian en el resultado particular de la regresión en el que se mide el efecto de la eliminación y la estandarización utilizada para hacerlos comparables en todas las observaciones. Todas las estadísticas de influencia se pueden calcular a partir de los resultados de la regresión única utilizando todos los datos.
2.2.1 Distancia de Cook
La distancia de Cook o D de Cook es una estimación comúnmente utilizada de la influencia de un punto de datos al realizar un análisis de regresión por mínimos cuadrados. En un análisis práctico de mínimos cuadrados ordinarios, la distancia de Cook puede usarse de varias maneras: para indicar puntos de datos influyentes que vale la pena verificar por su validez; o para indicar regiones del espacio de diseño donde sería bueno obtener más puntos de datos.
La distancia de Cook se calcula removiendo el \(i-\)-ésimo dato del modelo y recalculando la regresión. Resume que tanto los valores del modelos de regresión cambian cuando la \(i-\)-ésima observación no se considera.
Consideremos ahora que removemos la primera observación. Queremos comparar \(\widehat{\boldsymbol{\beta}}_{(1)}\) (los coeficientes estimados de regresión cuando no consideramos la observación 1) contra \(\widehat{\boldsymbol{\beta}}\). Particionamos la información a eliminar: \[
\boldsymbol{Y}=\left[ \begin{array}{c}
Y_1 \\ \boldsymbol{Y}_{(1)} \end{array} \right] =
X \boldsymbol{\beta} + \boldsymbol{\epsilon} = \left[ \begin{array}{c}
\boldsymbol{x}_1^{\top} \\ X_1 \end{array} \right] \boldsymbol{\beta} + \boldsymbol{\epsilon}
\] Queremos \(\widehat{\boldsymbol{\beta}}_{(1)}\), obtenido del ajuste de \[\boldsymbol{Y}_{(1)}=X_1\beta+\boldsymbol{\epsilon}_{(1)}\] entonces \(\widehat{\boldsymbol{\beta}}_{(1)}=(X_1^{\top}X_1)^{-1}X_1^{\top}\boldsymbol{Y}_{(1)}\).
La ecuación anterior implica que si queremos calcular el impacto de cada dato, se requerirían ajustar \(n+1\) regresiones. En realidad es suficiente con hacer una sola.
Notamos que \[
X^{\top}X=[\boldsymbol{x}_1,X_1^{\top}]\left[ \begin{array}{c} \boldsymbol{x}_1^{\top} \\ X_1 \end{array} \right]
= \boldsymbol{x}_1\boldsymbol{x}_1^{\top}+X_1^{\top}X_1,
\] entonces \(X_1^{\top}X_1=X^{\top}X-\boldsymbol{x}_1\boldsymbol{x}_1^{\top}\) y, por (B.1), tenemos \[
(X_1^{\top}X_1)^{-1} =
(X^{\top}X)^{-1}+(X^{\top}X)^{-1}\boldsymbol{x}_1(1-\boldsymbol{x}_1^{\top}(X^{\top}X)^{-1}\boldsymbol{x}_1)^{-1}\boldsymbol{x}_1^{\top}(X^{\top}X)^{-1}.
\] Similarmente, \[
X_1^{\top}\boldsymbol{Y}_{(1)} = X^{\top}\boldsymbol{Y} - \boldsymbol{x}_1Y_1,
\] entonces \[
\begin{align}
\widehat{\boldsymbol{\beta}}_{(1)} & = \;(X_1^{\top}X_1)^{-1}X_1^{\top}\boldsymbol{Y}_{(1)}\\[5pt]
&= \; (X^{\top}X)^{-1}X^{\top}\boldsymbol{Y}+(X^{\top}X)^{-1}\boldsymbol{x}_1\left[1-\boldsymbol{x}_1^{\top}(X^{\top}X)^{-1}\boldsymbol{x}_1\right]^{-1}\boldsymbol{x}_1^{\top}(X^{\top}X)^{-1}X^{\top}\boldsymbol{Y} \\
& \quad -(X^{\top}X)^{-1}\boldsymbol{x}_1\boldsymbol{Y}_1 -(X^{\top}X)^{-1}\boldsymbol{x}_1\left[1-\boldsymbol{x}_1^{\top}(X^{\top}X)^{-1}\boldsymbol{x}_1\right]^{-1}\boldsymbol{x}_1^{\top}(X^{\top}X)^{-1}\boldsymbol{x}_1\boldsymbol{Y}_1 \\[10pt]
& = \; \widehat{\boldsymbol{\beta}}+(X^{\top}X)^{-1}\boldsymbol{x}_1(1-h_{11})^{-1}\boldsymbol{x}_1^{\top}\widehat{\boldsymbol{\beta}}
-(X^{\top}X)^{-1}\boldsymbol{x}_1\boldsymbol{Y}_1 -(X^{\top}X)^{-1}\boldsymbol{x}_1(1-h_{11})^{-1}h_{11}\boldsymbol{Y}_1 \\[5pt]
& = \; \widehat{\boldsymbol{\beta}}+\frac{(X^{\top}X)^{-1}}{1-h_{11}} \left[
\boldsymbol{x}_1\widehat{\boldsymbol{Y}}_1 - (1-h_{11})\boldsymbol{x}_1Y_1 - \boldsymbol{x}_1h_{11}Y_1\right]\\[5pt]
& = \; \widehat{\boldsymbol{\beta}}-\frac{(X^{\top}X)^{-1}}{1-h_{11}} \boldsymbol{x}_1e_1 \\[5pt]
& = \; \widehat{\boldsymbol{\beta}}-(X^{\top}X)^{-1}\boldsymbol{x}_1 \frac{e_1}{1-h_{11}}.
\end{align}
\] En general, si eliminamos la observación \(i\) obtenemos \[
\widehat{\boldsymbol{\beta}}_{(i)} = \widehat{\boldsymbol{\beta}}-(X^{\top}X)^{-1}\boldsymbol{x}_i \frac{e_i}{1-h_{ii}},
\tag{2.5}\] esto es, los impactos individuales de cada observación pueden obtenerse del ajuste de regresión original.
En el siguiente ejemplo verificamos esta última expresión para una \(i\).
i<-14# eliminamos observacion 14n<-dim(autompg)[1]#Numero de observacionesX<-cbind(rep(1,length(autompg$wt)),autompg$wt, autompg$hp)H<-solve(t(X)%*%X)P<-X%*%H%*%t(X)# matriz de proyeccionh<-diag(P)# elementos diagonales de Pb<-H%*%t(X)%*%autompg$mpg# coef. estim. con todoscat("^beta =", b)
#> ^beta = 45.62093 -0.005788074 -0.04734371
Código
r<-autompg$mpg-X%*%b# residuales# Eliminamos i, y hacemos el ajuste directamentebmi<-solve(t(X[-i,])%*%X[-i,], t(X[-i,])%*%autompg$mpg[-i])cat("bmi = ", bmi)
#> bmi = 45.65918 -0.005893688 -0.04461523
Código
# Eliminamos i, y estimamos usando resultados anterioresbbmi<-b-H%*%X[i,]*r[i]/(1-h[i])cat("bbmi = ", bbmi)
#> bbmi = 45.65918 -0.005893688 -0.04461523
Código
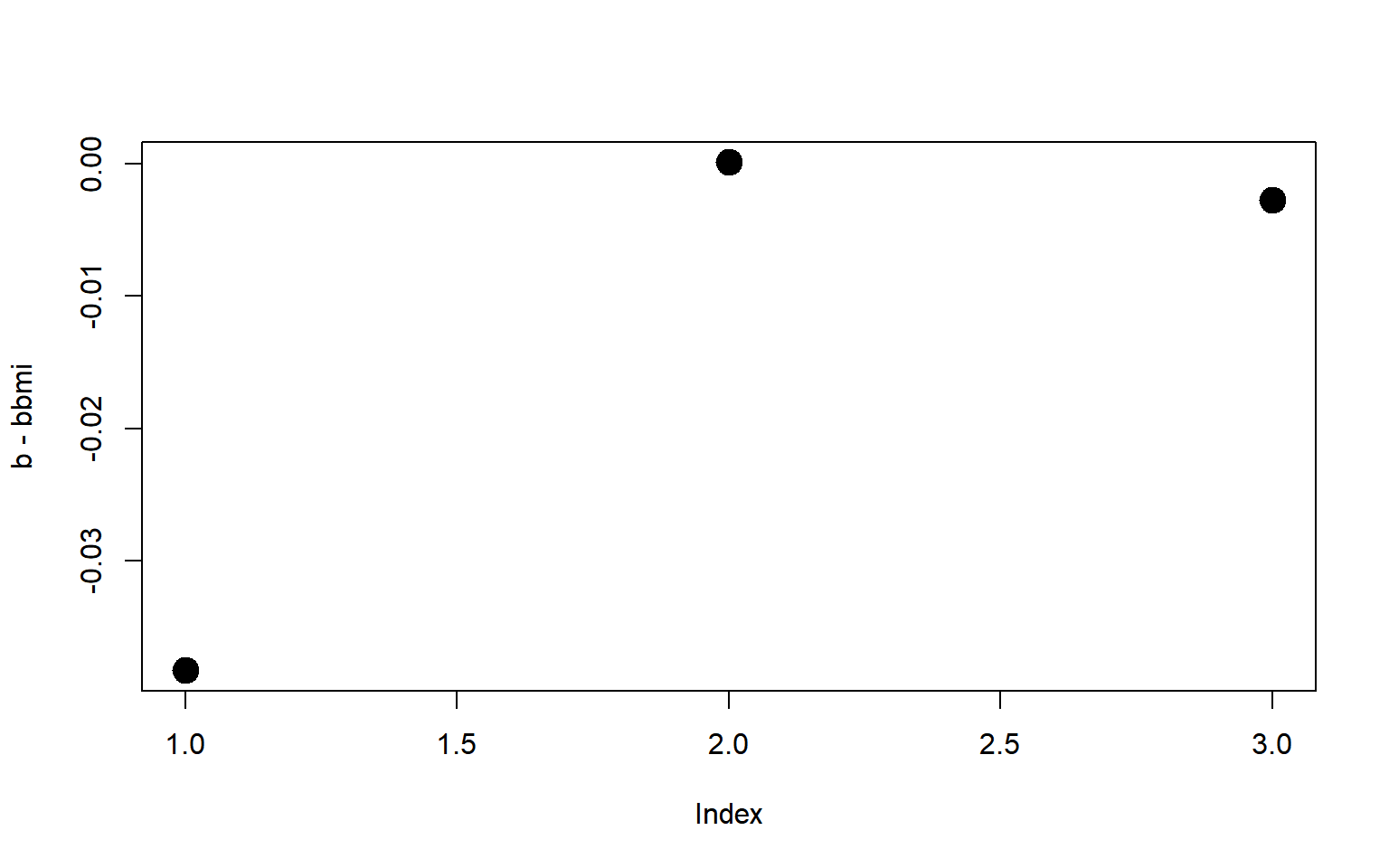
# Graficamos la diferencia entre las betasplot(b-bbmi,pch=19,cex=2)
Figura 2.11: Diferencia de betas con todos los datos y sin observación 14
Definición 2.2 (Distancia de Cook) El indicador de influencia \(D\) de Cook cuantifica el grado de disparidad entre \(\widehat{\boldsymbol{\beta}}\) y \(\widehat{\boldsymbol{\beta}}_{(i)}\), estimando una distancia estadística entre ellos: \[
D_i = \frac{(\widehat{\boldsymbol{\beta}}_{(i)}-\widehat{\boldsymbol{\beta}})^{\top}(X^{\top}X)\; (\widehat{\boldsymbol{\beta}}_{(i)}-\widehat{\boldsymbol{\beta}})}{p\, MS_{\mathrm{Res}}}
=\frac{\left(\widehat{\boldsymbol{Y}}_{(i)}-\widehat{\boldsymbol{Y}}\right)^{\top}\left(\widehat{\boldsymbol{Y}}_{(i)}-\widehat{\boldsymbol{Y}}\right)}{p\, s^2}.
\]
Usando la expresión (2.5) para \(\widehat{\boldsymbol{\beta}}_{(i)}\), se puede ver que una forma equivalente es: \[
D_i =\left( \frac{e_i}{s\sqrt{(1-h_{ii})}} \right)^2\left(\frac{h_{ii}}{p\,(1-h_{ii})}\right)=
\frac{{r_i}^2}{p} \left(\frac{h_{ii}}{1-h_{ii}}\right),
\tag{2.6}\] donde \({r_i}\) es el residual estandarizado como en (2.1).
Es facil demostrar la expresión anterior ya que \[
\begin{align}
G:&=\widehat{\boldsymbol{\beta}}_{(i)}-\widehat{\boldsymbol{\beta}}\\[5pt]
&= \widehat{\boldsymbol{\beta}}-(X^{\top}X)^{-1}\boldsymbol{x}_i\frac{e_i}{1-h_{ii}}-\widehat{\boldsymbol{\beta}}\\[5pt]
&=(X^{\top}X)^{-1}\boldsymbol{x}_i\frac{e_i}{1-h_{ii}}
\end{align}
\] y entonces, \[
\begin{align}
D_i&=\frac{1}{p\,s^2}G^{\top}(X^{\top}X)G\\
&=\frac{1}{p\,s^2}\left(\frac{e_i}{1-h_{ii}}\right)^2\boldsymbol{x}_i^{\top}(X^{\top}X)^{-1}(X^{\top}X)(X^{\top}X)^{-1}\boldsymbol{x}_i\\
&=\frac{1}{p\,s^2}\left(\frac{e_i}{1-h_{ii}}\right)^2\boldsymbol{x}_i^{\top}(X^{\top}X)^{-1}\boldsymbol{x}_i\\
&=\frac{1}{p\,s^2}\left(\frac{e_i}{1-h_{ii}}\right)^2h_{ii}\\
&=\left( \frac{e_i}{s\sqrt{(1-h_{ii})}} \right)^2\left(\frac{h_{ii}}{p\,(1-h_{ii})}\right).
\end{align}
\]
Una observación tendrá una \(D\) de Cook grande si su residual es grande (esto es, si \(\widehat{Y}_i\) esta lejos de \(\widehat{Y}\)) y el correspondiente \(h_{ii}\) es cercano a 1 (esto es si la \(\boldsymbol{x}_i\) esta alejada del centroide de las \(x\)’s).
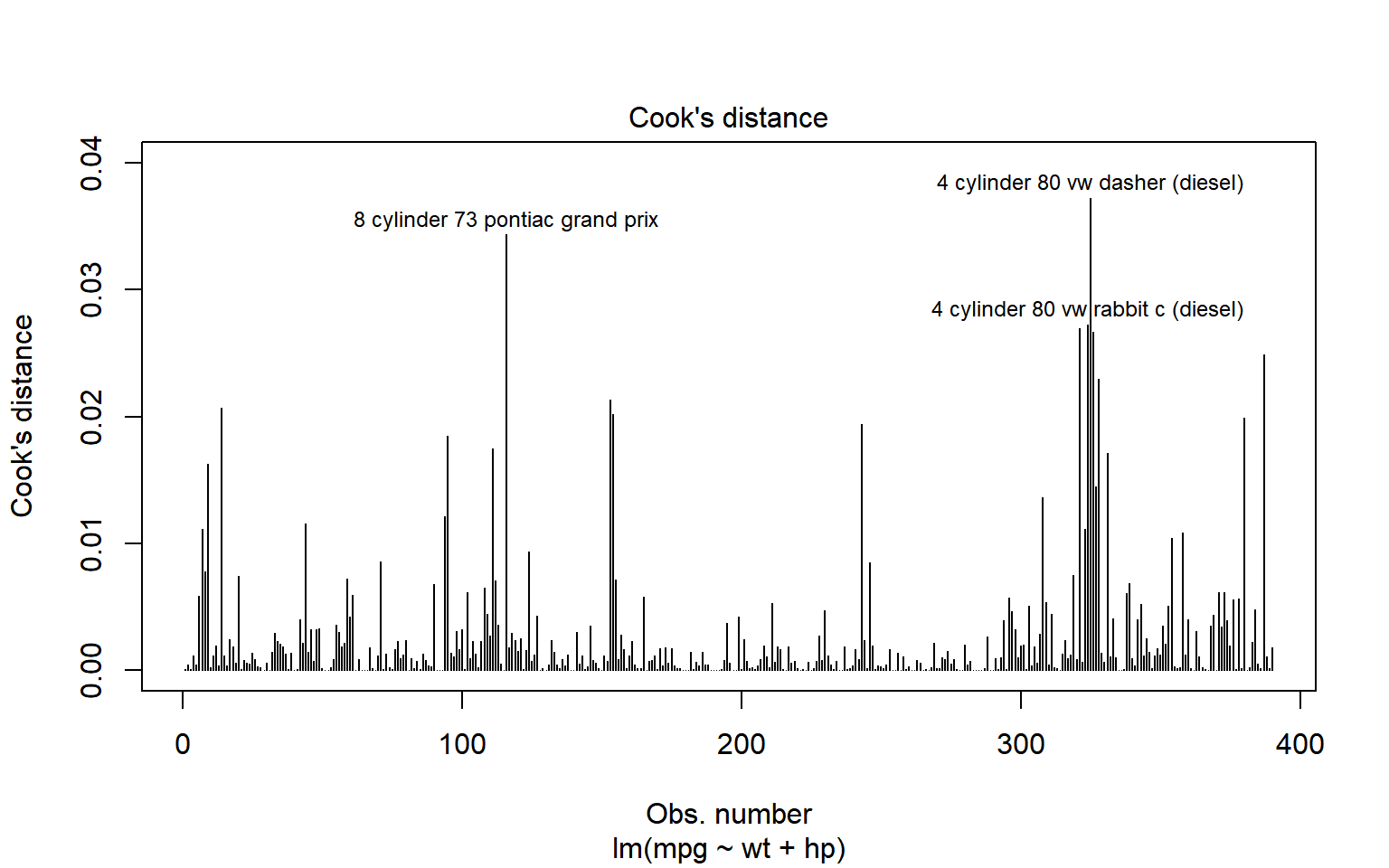
NotaEjemplo: Grafica 4 de plot.lm()-Distancia de Cook
Algunos textos mencionan el siguiente criterio para clasificar las observaciones:
Si \(D_i<0.5\), el \(i\)-ésimo dato tiene poca influencia
Si \(0.5\leq D_i< 1\), el \(i\)-ésimo dato es de influencia moderada
Si \(D_i>1\), el \(i\)-ésimo dato tiene alta influencia.
Otras fuentes solo sugieren identificar como potencialmente influyentes aquellos puntos cuyos \(D_i\)’s “se alejan del grupo”, pero otros textos consideran que el valor crítico para que un punto sea clasificado como influyente, en lugar de 1, sea \(4/n\) o \(4/(n-p)\). Con el fin de justificar el valor crítico de 1 examinamos el estadístico, \(F\), de prueba en hipótesis lineales: \[
\begin{align}
F&=\frac{(K^{\top}\widehat{\boldsymbol{\beta}}-\boldsymbol{m})^{\top}[K^{\top}(X^{\top}X)^{-1}K]^{-1}(K^{\top}\widehat{\boldsymbol{\beta}}-\boldsymbol{m})/q}{SS_{\mathrm{Res}}/(n-p)}\\[8pt]
&=\frac{(K^{\top}\widehat{\boldsymbol{\beta}}-\boldsymbol{m})^{\top}[K^{\top}(X^{\top}X)^{-1}K]^{-1}(K^{\top}\widehat{\boldsymbol{\beta}}-\boldsymbol{m})}{q\, MS_{\mathrm{Res}}},
\end{align}
\] el cual se distribuye \(F^q_{n-p}\) bajo \(H_0\) con \[
H_0: K^{\top}\boldsymbol{\beta}=\boldsymbol{m} \qquad \text{Vs.} \qquad H_0: K^{\top}\boldsymbol{\beta}\ne \boldsymbol{m}.
\] Si hacemos \(K^{\top}=I_p\) y \(\boldsymbol{m}=\boldsymbol{\beta}\), tenemos \[
F = \frac{(\widehat{\boldsymbol{\beta}}-\boldsymbol{\beta})^{\top}(X^{\top}X)\; (\widehat{\boldsymbol{\beta}}-\boldsymbol{\beta})/p}{MS_{\mathrm{Res}}}
= \frac{(\boldsymbol{\beta}-\widehat{\boldsymbol{\beta}})^{\top}(X^{\top}X)\; (\boldsymbol{\beta}-\widehat{\boldsymbol{\beta}})}{p\,MS_{\mathrm{Res}}}.
\] Notamos la semejanza de esta \(F\) con la \(D\) de Cook (Definición 2.2). si \(D_i\) cae en la región alrededor de \(\widehat{\boldsymbol{\beta}}\) donde \(0.8 \leq F(0.5;\ p ,n-p) \leq 1\) esto representaría que los coeficientes estimados al eliminar la observación \(i\) son afectados con un cambio de al menos el 50% en la distribución de \(F\). Esto es un impacto drástico. Entonces valores de la \(D\) de Cook mayores a 1 son outliers y potencialmente influyentes.
Otras herramientas de diagnóstico son, por ejemplo, DFFITS, DFBETAS y COVRATIO (ver Rawlings pags. 363-367). Estas medidas cubren diferentes aspectos del ajuste de un modelo (ajuste, impacto en coeficientes y en covarianzas, respectivamente), sin embargo todas ellas estan basadas en la misma idea de eliminar una observación a la vez y analizar su impacto.
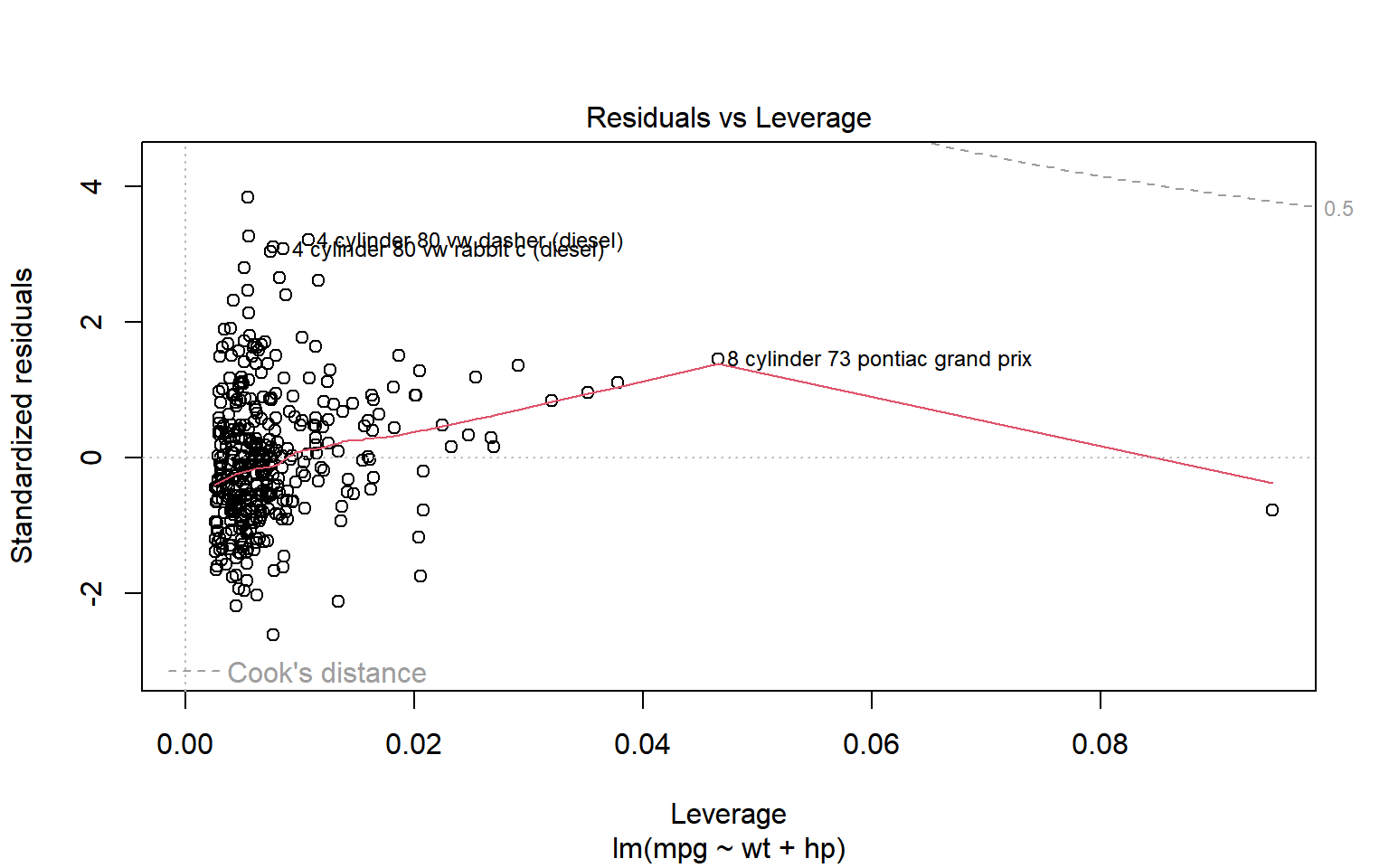
2.2.2 Gráficas residuales Vs influencia
El gráfico de residuos contra la influencia (leverage) es una buena manera de identificar observaciones que más impactan la inferencia. A veces, las observaciones influyentes son representativas de la población, pero también podrían indicar un error en el registro de datos o un valor atípico no representativo. Nunca se recomienda solo borrar estos datos sino investigar más sobre la validez y explicación de estos casos.
NotaEjemplo: Grafica 5 de plot.lm(): residuales contra influencia
A diferencia de los otros gráficos, los patrones no son tan relevantes. Una de las características que podemos identificar es si los residuales permanecen más o menos constantes para diferentes valores de la influencia (“leverage”).
Los puntos en esta gráfica se pueden obtener también usando
plot(resid(fit),hatvalues(fit))
pero la opción 5 de plot.lm incluye las curvas de nivel de la distancia de Cook (por default a niveles 0.5 y 1). Así que se puede evaluar fácilmente puntos que caen en las regiones de distancia \([0,0.5), [0.5,1)\) y \([1,+)\)
En el ejemplo tenemos que no hay obvia violación a la homocedasticidad y que aunque hay puntos atípicos con un nivel interesante de influencia, ninguno llega a tener una distancia de Cook mayor a 0.5.
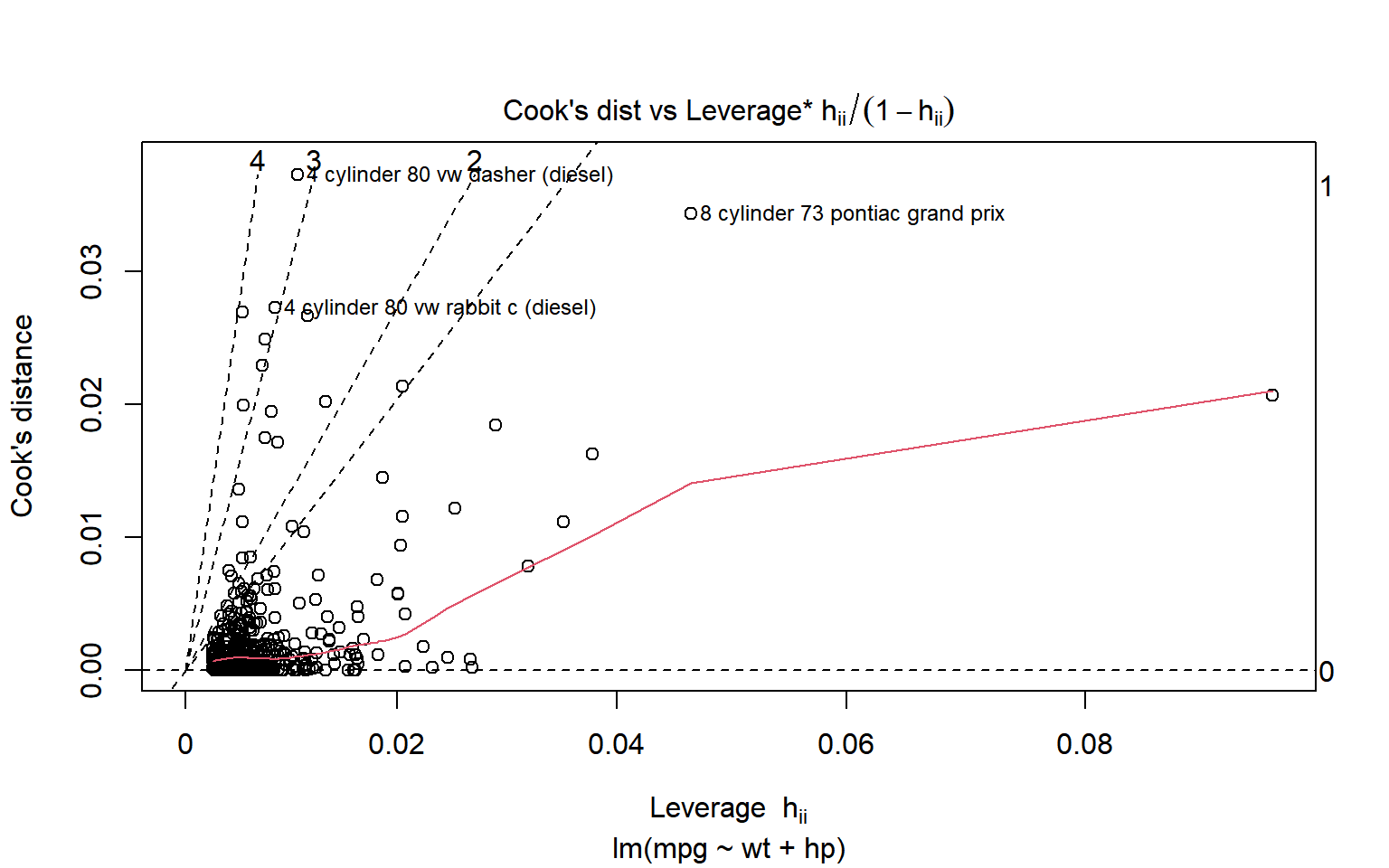
2.2.3 Grafica de la distancia de Cook Vs Lev./(1-Lev.)”
La sexta opción de plot.lm es la gráfica de la distancia de Cook contra \(h_{ii}/(1-h_{ii})\). Ésta es motivada por (2.6). Los contornos de los residuos estandarizados (rstandard) son líneas que pasan por el origen. Las líneas de contorno están etiquetadas con las magnitudes.
Figura 2.14: Distancia de Cook contra influencia/(1-influencia)
2.3 Multicolineariedad
La multicolinealidad es un alto grado de correlación (dependencia lineal) entre varias covariables. Ocurre comúnmente cuando se incorporan un gran número de éstas en un modelo de regresión. La alta relación entre variables se debe muchas veces a que algunas de ellas pueden medir los mismos conceptos o fenómenos.
Recordamos que para resolver las ecuaciones normales asumimos que las columnas de \(X\) son linealmente independientes y que, por lo tanto, \(X^{\top}X\) es invertible. En la práctica se puede buscar que esto se cumpla, sin embargo, un problema se puede presentar cuando en las columnas de la matriz \(X\) tiene multicolineridad (casi dependencias). La mera existencia de multicolinealidad no es una violación del supuesto para obtener los estimadores de mínimos cuadrados pero la multicolinearidad entre columnas de \(X\) puede tener efectos importantes en la calidad de la inferencia e interpretación de resultados.
Para indagar el efecto de la multicolinearidad consideramos \(X^{\top}X\) que es una \(p\times p\) matriz simétrica y de rango \(p\). Con el Teorema de Descomposición espectral (Teorema C.5), sabemos que \[
X^{\top}X=T\Lambda T^{\top}=
[\boldsymbol{v}_1,\cdots,\boldsymbol{v}_p]\left[ \begin{array}{ccc}
\lambda_1 & \cdots & 0 \\
\vdots & \ddots & \vdots \\
0 & \cdots & \lambda_p \end{array} \right]
\left[ \begin{array}{c} \boldsymbol{v}_1^{\top} \\ \vdots \\ \boldsymbol{v}_p^{\top} \end{array} \right]= \sum_{i=1}^p \lambda_i \boldsymbol{v}_i \boldsymbol{v}_i^{\top},
\] donde las \(\lambda_i\)’s son los eigenvalores de \(X^{\top}X\) y \(T\) es una matriz ortogonal. Entonces \(T^{-1}=T^{\top}\) y \[
\left(X^{\top}X\right)^{-1} = T\Lambda^{-1} T^{\top} = \sum_{i=1}^p \frac{1}{\lambda_i} \boldsymbol{v}_i \boldsymbol{v}_i^{\top}.
\]
De esta expresión vemos si algún eigenvalor es cercano a cero (multicolinearidad), algunos componentes de \(\left(X^{\top}X\right)^{-1}\) tendrán un peso muy alto. Ahora, recordando que \(\text{Var}(\widehat{\boldsymbol{\beta}}) = \sigma^2 (X^{\top}X)^{-1}\), tenemos que \[
\text{Var}(\widehat{\beta}_i)=\sigma^2 \sum_{j=1}^p \frac{1}{\lambda_j} v_{ij}^2\ ,
\] donde \(\boldsymbol{v}_i=(v_{1i},v_{2i},\ldots,v_{pi})^{\top}\), ya que \(\boldsymbol{v}_i\) es la \(i-\)ésima columna de la matriz \(T\).
Entonces, la varianza puede ser muy grande para algunos \(\widehat{\beta}_i\)’s.
Basicamente hay dos tipos de origenes para la multicolinearidad:
Multicolinealidad estructural: Este tipo ocurre cuando creamos un término del modelo utilizando otros términos. En otras palabras, es un subproducto del modelo que especificamos en lugar de estar presente en los datos. Por ejemplo, cuando elevamos al cuadrado la variable \(X\) para modelar la curvatura. Claramente habrá hay una correlación entre estas dos varibles.
Multicolinealidad de datos: Este tipo de multicolinealidad está presente en los datos mismos en lugar de ser un artefacto de nuestro modelo. Los experimentos observacionales tienen más probabilidades de exhibir este tipo de multicolinealidad.
Los principales efectos de la multicolinealidad son los siguientes:
Una multicolinealidad fuerte produce varianzas y covarianzas grandes para los estimadores de mínimos cuadrados. Así, muestras con pequeñas diferencias podrían dar lugar a estimaciones muy diferentes de los coeficientes del modelo. Es decir, las estimaciones de los coeficientes resultan poco fiables cuando hay un problema de multicolinealidad.
A consecuencia de la gran magnitud de los errores estándar de las estimaciones, muchas de éstas no resultarían significativamente distintas de cero: Ios intervalos de confianza serán ‘grandes’ y por tanto, con frecuencia contendrán al cero.
Los coeficientes del ajuste con todos los predictores difieren bastante de los que se obtendrían con una regresión simple entre la respuesta y cada variable explicativa.
La multicolinealidad, aunque no afecta al ajuste global del modelo (medidas como la \(R^2\), etc.) hacen que los errores estándar de las estimaciones de la respuesta media y de la predicción de nuevas observaciones, lo que afecta a la estimación en intervalo.
No hay un claro criterio para detectar la multicolinearidad sino diversos diagnósticos propuestos para intentar detectarla. Los más relevantes son los siguientes.
2.3.1 Los gráficos entre covariables
Estos son útiles para estudiar la relación entre las covariables y su disposición en el espacio, y con ello detectar correlaciones o identificar observaciones muy alejadas del resto de datos y que pueden influenciar notablemente la estimación. Consisten en gráficos de dispersión entre un par de covariables continuas o un par de factores, y gráficos de cajas cuando se trata de investigar la relación entre un factor y una covariable.
2.3.2 Correlaciones
Una medida simple de multicolinealidad consiste en la inspección de los elementos fuera de la diagonal de la matriz \(X^{\top} X\). Pero primero consideremos que estandarizamos las variables: \[
\boldsymbol{w}_i=\frac{\boldsymbol{X}_i-\overline{\boldsymbol{X}}_i}{s_i}
\] para \(i=1,\ldots,k\). Entonces si \(W=[\boldsymbol{w}_1,\boldsymbol{w}_2,\cdots,\boldsymbol{w}_p]\) es la matriz cuyas columnas de \(X\) son estandarizadas (olvidemonos por un momento de la ordenada al origen) y hacemos la regresión \[
\boldsymbol{y}=W\boldsymbol{\beta}+\boldsymbol{\epsilon},
\] la matriz \((W^{\top}W)^{-1}\) tiene el importante papel de ser proporcional a la matriz de varianzas y covarianzas del estimador \(\widehat{\boldsymbol{\beta}}\).
Por otro lado, los elementos fuera de la diagonal de \(W^{\top}W\) corresponden a las correlaciones simples \(r_{i j}\) entre todos los regresores.
Si dos regresores \(x_i\) y \(x_j\) son casi linealmente dependientes, entonces \(\left|r_{i j}\right| \approx 1\). Sin embargo, cuando la multicolinealidad involucra a varias variables, no hay garantías de detectarla a través de las correlaciones bivariadas.
NotaEjemplo: Datos de autos
Código
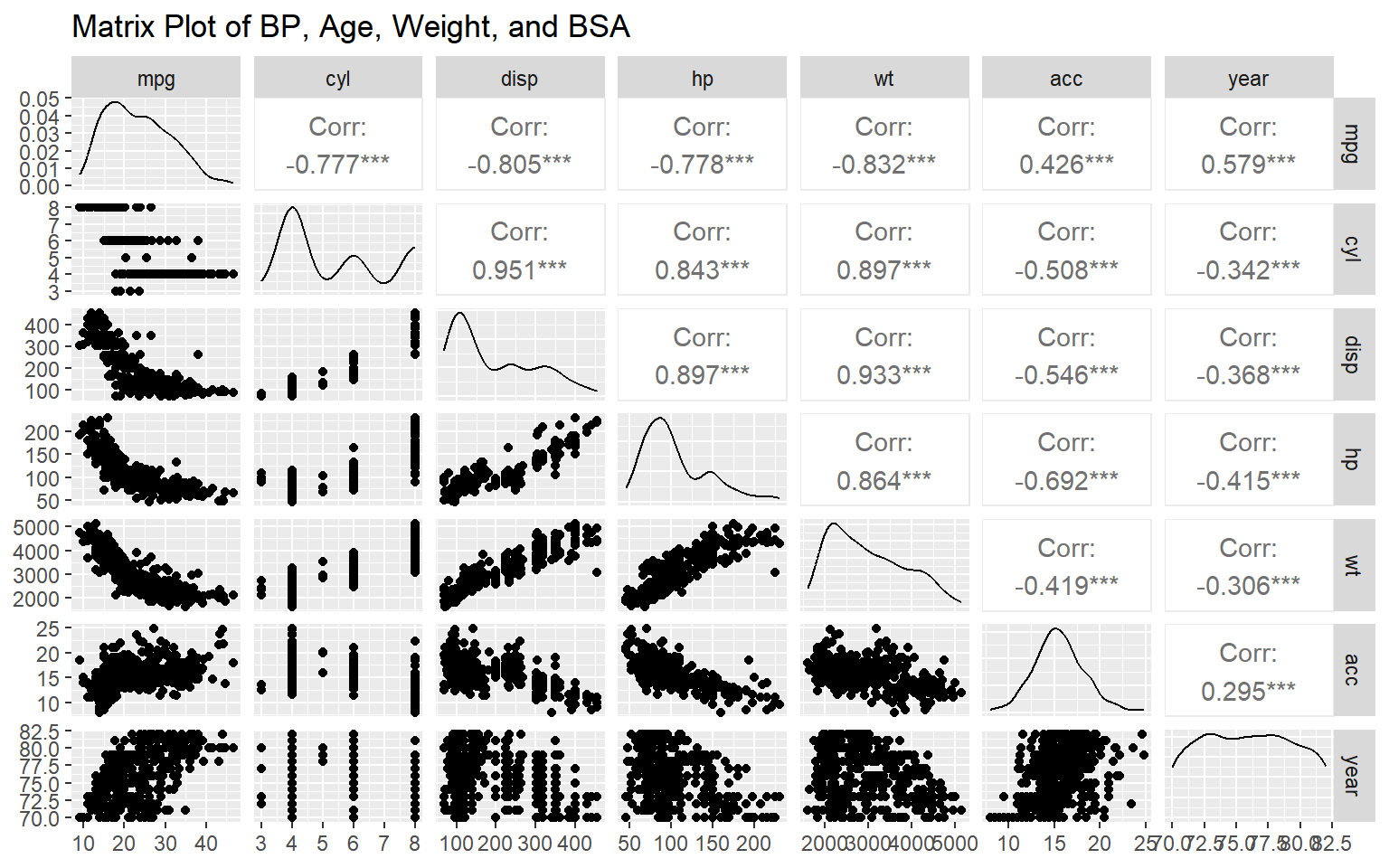
library(GGally)ggpairs(autompg, title ="Matrix Plot of BP, Age, Weight, and BSA")
Figura 2.15: Grafica y correlación de pares de covariables.
El comando ggpairs muestra en el panel superior la correlación entre las variables continuas, el inferior los diagramas de dispersión entre las variables continuas, la diagonal los gráficos de densidad de las variables continuas. Cuando hay variables categóricas, añade diagramas de caja para la combinación entre variables continuas y categóricas. Ver más en ggpairs.
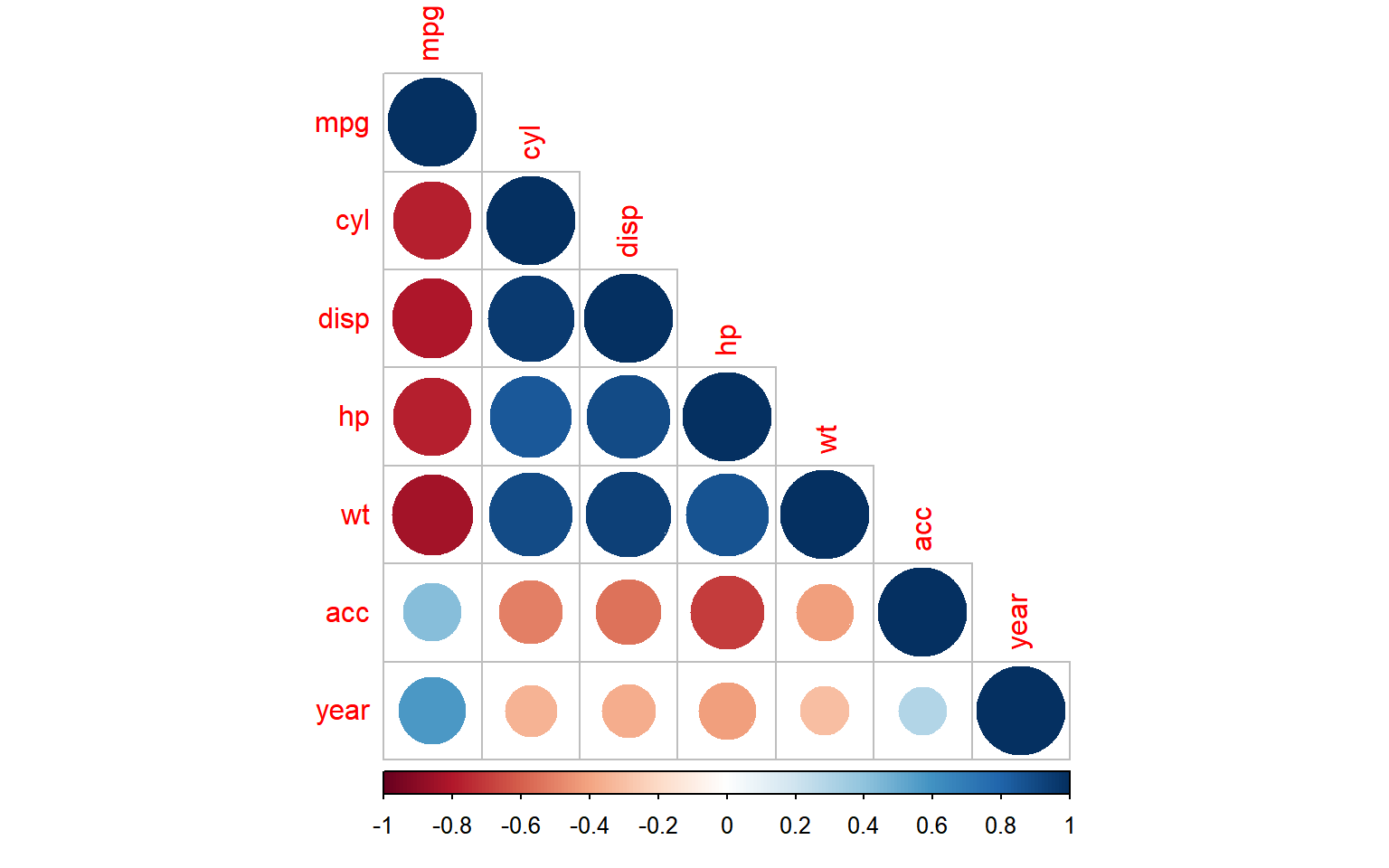
Código
# Calcular la matriz de correlaciónlibrary(corrplot)# Calcular la matriz de correlacióncor_matrix<-cor(autompg)# Generar la gráfica de matriz de correlacióncorrplot(cor_matrix, method ="circle", type ='lower',title ="")
Figura 2.16: Grafica de colores para correlación de pares de covariables.
Puesto que uno de los efectos principales de la multicolinealidad es la inflación de la varianza y covarianza de las estimaciones, es posible calcular unos factores de inflación de la varianza, FIV (VIF por su nombre en inglés), que permiten apreciar tal efecto.
Consideramos nuevamente \(W\) como la matriz cuyas columnas de \(X\) son estandarizadas. Veamos la estructura de esta matriz en relación a su primera variable. \[
\begin{align}
W^{\top}W & = \; \left[\begin{array}{c}\boldsymbol{w}_1^{\top} \\ \boldsymbol{w}_2^{\top} \\ \vdots \\ \boldsymbol{w}_k^{\top} \end{array} \right] \left[ \boldsymbol{w}_1,\boldsymbol{w}_2,\cdots,\boldsymbol{w}_k \right]
= \left[ \begin{array}{c} \boldsymbol{w}_1^{\top} \\ M_1^{\top} \end{array} \right] \left[ \begin{array}{cc} \boldsymbol{w}_1 & M_1 \end{array} \right] \\[10pt]
& = \; \left[ \begin{array}{cc} \boldsymbol{w}_1^{\top}\boldsymbol{w}_1 & \boldsymbol{w}_1^{\top}M_1 \\ M_1^{\top}\boldsymbol{w}_1 & M_1^{\top}M_1 \end{array} \right] =:
\left[ \begin{array}{cc} A_{11} & A_{12} \\ A_{21} & A_{22} \end{array} \right]
\end{align}
\] entonces, recordando la inversa de matrices en partes (Proposición B.5): \[
\left(W^{\top}W\right)^{-1} = \left[ \begin{array}{cc} \left(A_{11} - A_{12}A_{22}^{-1}A_{21}\right)^{-1} & - \quad \\ - & - \quad \end{array} \right]
\] de modo que el primer elemento de la diagonal de \((W^{\top}W)^{-1}\) es \[
\begin{align}
q_{11}: &= \left(\boldsymbol{w}_1^{\top} \boldsymbol{w}_1 - \boldsymbol{w}_1^{\top}M_1(M_1^{\top}M_1)^{-1}M_1^{\top} \boldsymbol{w}_1\right)^{-1} \\
&=\left(\boldsymbol{w}_1^{\top}\left[I_{n}-M_1(M_1^{\top}M_1)^{-1}M_1^{\top}\right] \boldsymbol{w}_1\right)^{-1}\\
&=\left(\boldsymbol{w}_1^{\top}\left[I_{n}-P_{(1)}\right]\boldsymbol{w}_1\right)^{-1}
\end{align}
\] donde \(P_{(1)}\) es la matriz de proyección de \(X\) pero excluyendo su primera columna. Podemos ver que entonces \(\boldsymbol{w}_1^{\top}\left[I_{n}-P_{(1)}\right]\boldsymbol{w}_1\) es la suma de residuales cuadrados considerando como variable de interés a \(\boldsymbol{w}_1\) y como regresoras a las restantes \(k-1\) variables. Ver (1.2).
Si denotamos a \(R_1^2\) como el coeficiente de determinación de la regresión de \(\boldsymbol{w}_1\) en las variables de \(M_1\), entonces usando la Definición 1.5, tenemos que \[
R_1^2=1-\frac{SS_{\mathrm{Res},1}}{SS_{\mathrm{T},1}}.
\] Sea \(\hat{\beta}_1^*\) el estimador de los coeficientes de la variable estandarizada \(W_1\). Como \[
\text{Var}\left(\hat{\beta}_1^*\right) = \sigma^2_{W_1} \left[(W^{\top}W)^{-1}\right]_{1,\,1} \quad \text{ y } \quad SS_{\mathrm{Res},1} = \boldsymbol{w}_1^{\top}\left[I_{n}-P_{(1)}\right]\boldsymbol{w}_1,
\] entonces \[
\text{Var}\left(\hat{\beta}_1^*\right)=\sigma^2_{W_1} \frac{1}{SS_{\mathrm{Res},1}}.
\] Como \(\overline{W}_1=0\) y \(s_{W_1}^2=1\) entonces \(SS_{\mathrm{T},1}=(n-1)s_{W_1}^2=(n-1)\). Así, \[
\text{Var}\left(\hat{\beta}_1^*\right)=\frac{\sigma^2_{W_1}}{n-1}\frac{1}{1-R_1^2}.
\] En general, \[
\text{Var}\left(\hat{\beta}_j^*\right)=\frac{\sigma^2_{W_j}}{n-1}\frac{1}{1-R_j^2}.
\] De modo que si la variable \(W_j\) depende altamente del resto de variables entonces \(R_j^2\) estará cercano a 1 y por lo tanto \(\text{Var}(\hat{\beta}_j^*)\) estará “inflada”.
Definición 2.3 (FIV) El Factor Inflación de la Varianza (FIV) se define como \[
\text{FIV}_j=\frac{1}{1-R_j^2}.
\]
Generalmente, valores de un FIV superiores a 10 (\(R_j^2\,>\,0.90\)) dan indicios de un problema de multicolinealidad, si bien su magnitud depende del modelo ajustado. Lo ideal es compararlo con su equivalente en el modelo ajustado, esto es con \(1 /\left(1-R^2\right)\), donde \(R^2\) es el coeficiente de determinación del modelo. Los valores FIV mayores que esta cantidad implican que la relación entre las variables independientes es mayor que la que existe entre la respuesta y los predictores, y por tanto dan indicios de multicolinealidad.
2.3.4 Número e índices de condición
En el campo del análisis numérico, el número de condición de una función respecto de su argumento mide cuánto se modifica el valor de salida si se realiza un pequeño cambio en el valor de entrada. Para los sistemas lineales (como \(X\boldsymbol{\beta}\)) se define a partir de los eigenvalores del operador.
Dado que la multicolinealidad afecta a la singularidad (rango menor que \(p\) ) de la matriz \(X^{\top} X\), sus valores propios \(\lambda_1, \lambda_2, \ldots, \lambda_p\) pueden revelar multicolinealidad en los datos. De hecho, si hay una o más dependencias casi lineales en los datos, entonces uno o más de los valores propios será pequeño.
En lugar de buscar valores propios pequeños, se puede optar por calcular el número de condición de \(X^{\top} X\), definido por: \[
\kappa=\lambda_{\max } / \lambda_{\min }
\] que es una medida de dispersión en el espectro de valores propios de \(X^{\top} X\). Una regla empírica es que, si el número de condición es menor que 100, no hay problemas de multicolinealidad. Números de condición entre 100 y 1000 implican multicolinealidad moderada, y mayores que 1000 implican multicolinealidad severa.
Los índices de condición de la matriz \(X^{\top} X\) también son útiles para el diagnóstico de multicolinealidad y se definen como: \[
\kappa_j=\lambda_{\max}/\lambda_j, \qquad j = 1, \ldots, p
\] El número de índices de condición que son grandes (por ejemplo, \(\kappa_j\geq 1000\) ) es una medida útil del número de dependencias casi lineales en \(X^{\top} X\).
2.3.5 Componentes Principales
El análisis de componentes principales se plantea sobre conjuntos de variables relacionadas linealmente entre sí y tiene como finalidad la de definir un conjunto menor de nuevas variables obtenidas como combinación lineal de las originales. Si el análisis de componentes principales resulta significativo, estamos reconociendo multicolinealidad. Este tipo de análisis lo retomaremos más adelante.
2.4 Poder predictivo / generalidad
Una vez que hemos resuelto los problemas del modelo en relación a los supuestos, cuando el modelo quiere ser utilizado para hacer predicción, nos interesa también hacer su evaluación en términos de su capacidad para hacer predicciones adecuadas.
El que modelo se ajuste muy bien a los datos y cumpla con los supuestos, no es garantía de que sea muy bueno para predecir datos futuros. Esto es fácil de observar cuando el modelo tiene un sobre ajuste de los datos observados, al punto de perder la generalidad necesaria para describir los datos que fenómeno puede producir.
La herramienta de evaluación que describimos aquí no solo puede aplicarse a modelos lineales o lineales generalizados sino que a cualquier modelo de aprendizaje que produzca predicciones.
La validación cruzada es un conjunto de métodos estadístico para evaluar el rendimiento de generalización de un modelo. La idea de la validación cruzada se originó en la década de 1930 (Larson S.,1931) donde una muestra se utilizó para la estimación de un modelo de regresión y una segunda muestra se utlizó para la predicción.
Mosteller y Tukey (1963), y varias otras personas desarrollaron aún más la idea. Aparecieron por primera vez una clara declaración de validación cruzada, que es similar a la versión actual de validación cruzada ‘\(k\)- fold’, que apareció por primera vez en Mosteller F. and Tukey J.W. (1968). En la década de 1970, se empleó por primera vez la validación cruzada como medio para elegir parámetros modelo adecuados.
Actualmente, la validación cruzada es ampliamente aceptada en la minería de datos y la comunidad de aprendizaje automático, y sirve como un procedimiento estándar para la estimación del rendimiento y la selección de modelos.
Hay dos posibles metas en la validación cruzada:
Para estimar el rendimiento y la generalidad del modelo ajustado con los datos disponibles.
Comparar el rendimiento de dos o más algoritmos diferentes y encontrar el mejor algoritmo para los datos disponibles, o alternativamente comparar el rendimiento de dos o más variantes de un modelo parametizado.
Si el objetivo final es comparar dos algoritmos de aprendizaje, las muestras de rendimiento obtenidas a través de la validación cruzada se pueden utilizar para realizar pruebas de hipótesis estadísticas de dos muestras.
2.4.1 Validación ‘Hold-Out’ (suspensión).
En lugar de evaluar el modelo usando los mismos datos de entrenamiento, se prefiere un conjunto de pruebas independiente.
Un enfoque natural es dividir los datos disponibles en dos partes:
una para la estimación (ajuste, entrenamiento) y
otra para pruebas.
De esta forma, la validación ‘Hold-Out’ da una estimación más precisa para el rendimiento de generalización del algoritmo.
La desventaja es que este procedimiento es que no utiliza todos los datos disponibles para el ajuste del modelo y los resultados dependen en gran medida de la elección de datos para entrenamiento y prueba. Además pueden existir elementos externos para la selección de los datos puede sesgar los resultados. Por ejemplo criterios para incluir ciertos datos resultan en datos demasiado fáciles (difíciles) de clasificar.
Estos problemas se pueden abordar parcialmente repitiendo la validación de retención varias veces y promediando los resultados, pero a menos que esta repetición se realice de manera sistemática, algunos datos pueden ser incluidos en el conjunto de pruebas varias veces, mientras que otros no están incluidos en absoluto, o a la inversa algunos datos siempre pueden caer en el conjunto de pruebas y nunca tener la oportunidad de contribuir a la fase de aprendizaje.
Para hacer frente a estos desafíos y utilizar eficientemente los datos disponibles se puede optar por la validación cruzada ‘\(k\)-fold’.
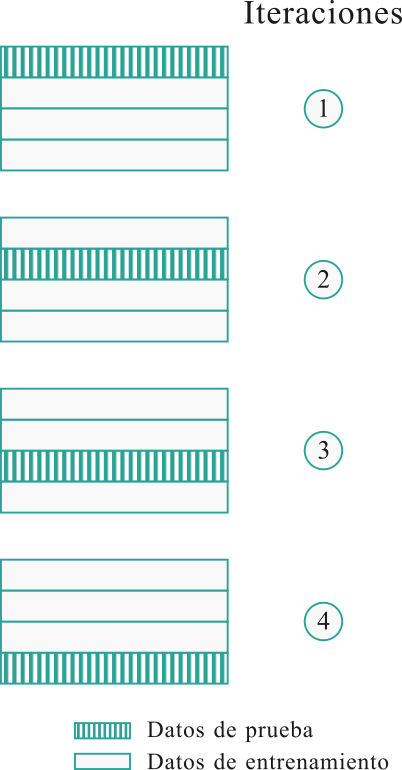
2.4.2 Validación cruzada ‘\(k\)-Fold’
Los datos se dividen primero en \(k\) segmentos, grupos o ‘pliegues’ de tamaño igual (o casi igual).
Posteriormente, se realizan \(k\) iteraciones de entrenamiento y validación tales que dentro de cada iteración se mantiene un pliegue diferente de los datos para su validación, mientras que los restantes \(k-1\) pliegues se utilizan para el aprendizaje.
Las estadísticas del error cuadrático medio consideran el ajuste y la varianza estimada. Por ejemplo una medida de discrepancia entre el los datos es \[
MSE_j=\frac{1}{n}\sum_{i=m}^{m}(Y_i-\widehat{Y}_i(j))^2 \quad \text{ y }\quad
MSE_{\operatorname{CV}}=\sum_{j=1}^k MSE_{j}.
\] donde, \(\widehat{Y}_i(j)\) es el modelo ajustado en la \(j-\)ésima iteración pero evaluado en el \(i-\)ésimo elemento del conjunto de prueba.
Los datos se estratifican comúnmente antes de dividirse en pliegues \(k\). La estratificación es el proceso de reorganizar los datos para asegurar que cada pliegue sea un buen representante del todo.
Figura 2.17: Ilustración Validación cruzada “4-fold”
Por ejemplo, en un problema de clasificación binaria en el que cada clase comprende el 50 por ciento de los datos, lo mejor es organizar los datos de tal manera que en cada clase comprende alrededor de la mitad de las instancias.
NotaEjemplo: Validación Cruzada ‘k-fold’
Código
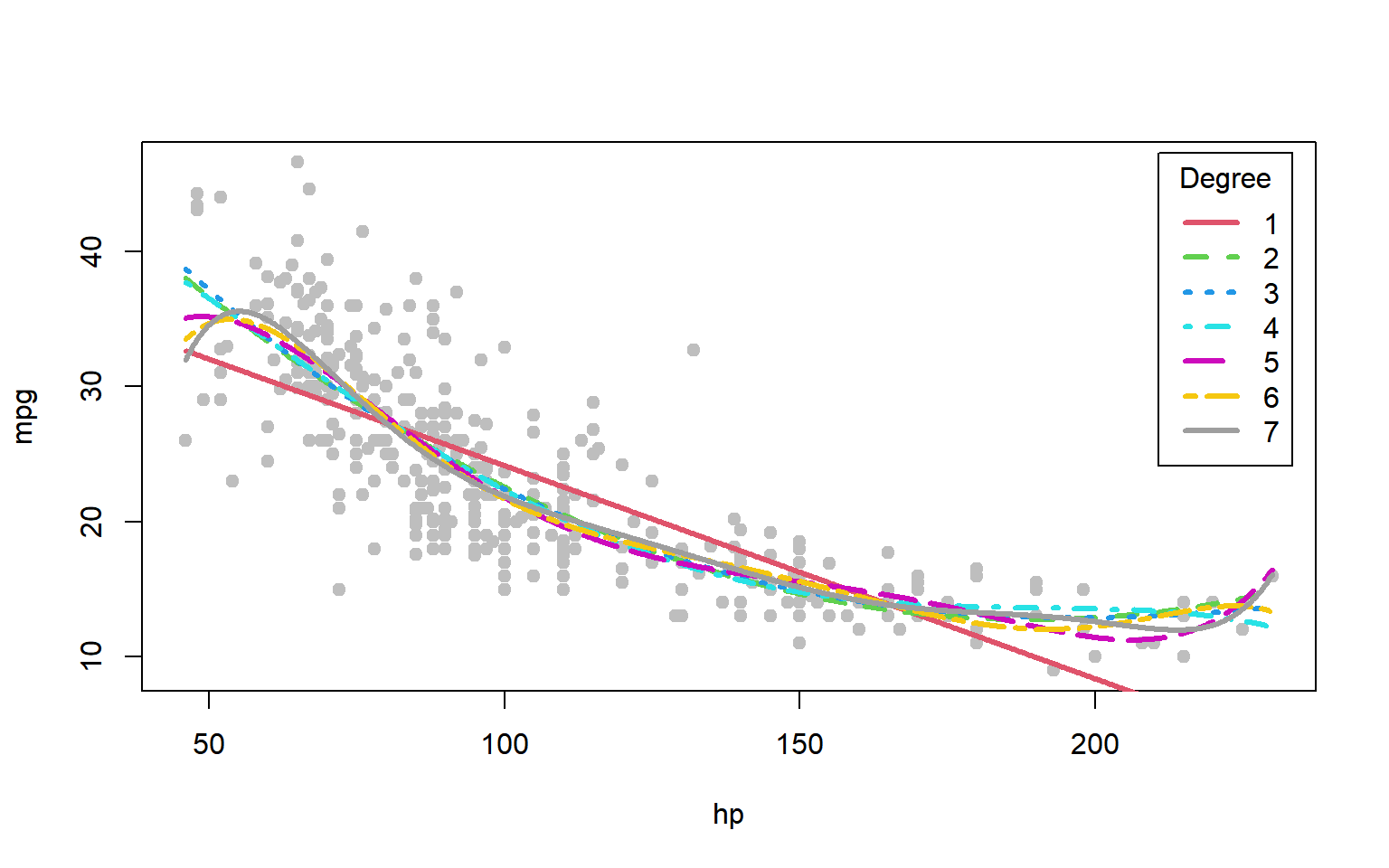
hp_graf<-with(autompg, seq(min(hp), max(hp), length =1000))plot(mpg~hp, data =autompg, pch=19, col="grey", main="Promedio de diferentes de polinomios de grado p")for(pin1:7){m<-lm(mpg~poly(hp, p), data =autompg)mpg_graf<-predict(m, newdata =data.frame(hp =hp_graf))lines(hp_graf, mpg_graf, col =p+1, lty =p, lwd =3)}legend("topright", legend =1:7, col =2:9, lty =1:7, lwd =3, title ="Grado p", inset =0.02)
Figura 2.18: Modelos de regresión a contrastar
El ajuste lineal es claramente inapropiado; los ajustes para (\(p = 2\)) (cuadrático) hasta (\(p = 4\)) son muy similares; y el ajuste para (\(p = 5\)) podría sobreajustar los datos al perseguir uno o dos valores relativamente altos de millas por galón (mpg) a la derecha (pero consulta los resultados de validación cruzada reportados más adelante).
Existen muchos paquetes en R, Python, etc. que facilitan la creación de las particiones, como el package cv y caret de R, o scikit-learn (sklearn) en Python.
Por ejemplo, en R el codigo siguiente obtiene \(CV\) del modelo polinómico de grado 2 con \(k = 10\).
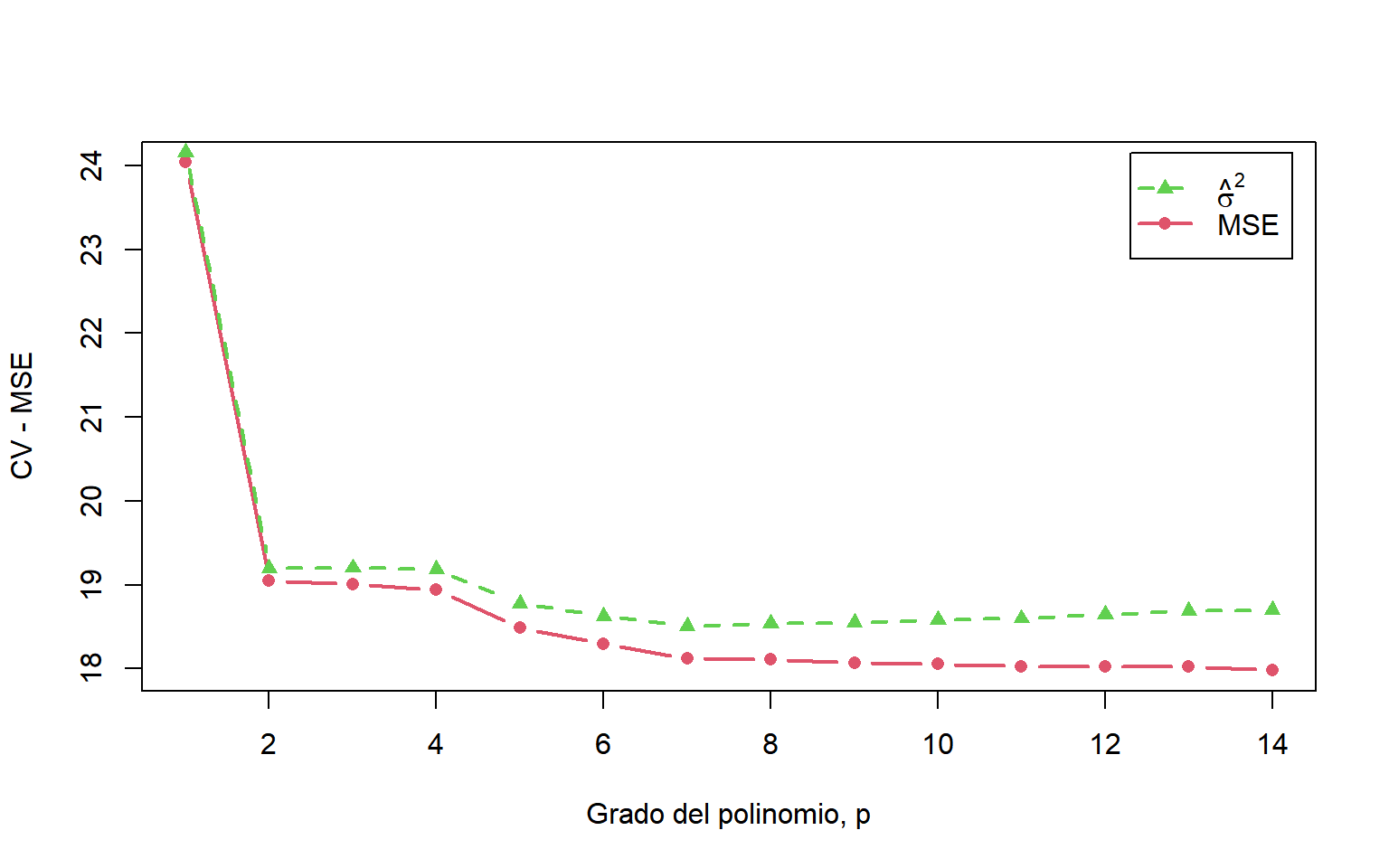
La siguiente gráfica muestra dos medidas de error (cuadrado) estimado en función del grado de la regresión polinómica: el error cuadrático medio, definido como \[
\text{MSE} = \frac{1}{n} \sum_{i=1}^n \left(y_i - \widehat{y}_i\right)^2,
\] y la varianza residual usual, definida como \[
\widehat{\sigma}^2 = \frac{1}{n - p - 1} \sum_{i=1}^n \left(y_i - \widehat{y}_i\right)^2.
\] El primero necesariamente disminuye con \(p\) (o, más estrictamente, no puede aumentar con \(p\)), mientras que el segundo se vuelve ligeramente mayor para los valores más grandes de \(p\), con el “mejor” valor, por un pequeño margen, para \(p = 7\).
Código
library("cv")np<-14var<-mse<-mse_cv5<-mse_cv20<-numeric(np)for(pin1:np){m<-lm(mpg~poly(hp, p), data =autompg)mse[p]<-mse(autompg$mpg, fitted(m))var[p]<-summary(m)$sigma^2mse_cv5[p]<-cv(m,k=5)mse_cv20[p]<-cv(m,k=20)}plot(c(1, np), range(mse), type ="n", xlab ="Grado del polinomio, p", ylab ="CV - MSE - MSE_CV")lines(1:np, mse, lwd =2, lty =1, col =2, pch =16, type ="b")lines(1:np, var, lwd =2, lty =2, col =3, pch =17, type ="b")lines(1:np, mse_cv5, lwd =2, lty =2, col =4, pch =17, type ="b")lines(1:np, mse_cv20, lwd =2, lty =2, col =6, pch =17, type ="b")grid()legend("top", inset =0.02, box.col="white", legend =c("MSE",expression(hat(sigma)^2), "MSE_CV5", "MSE_CV20"), lwd =2, lty =2:1, col =c(2:4,6), pch =c(16,17,17,17))
Figura 2.19: Modelos de regresión a contrastar
El método lm utiliza por defecto mse() como criterio de validación cruzada (CV) y la identidad matricial de Woodbury (Hager, 1989) para actualizar la regresión con cada segmento eliminado, sin necesidad de volver a ajustar el modelo literalmente.
El resultado de este método puede ser susceptible a sesgo cuando el valor de \(k\) es pequeño. Al usar un número pequeño de segmentos (por ejemplo, \(k=2\) o \(k=3\)) se genera un mayor sesgo porque el conjunto de entrenamiento es mucho más pequeño que el conjunto de datos completo. Esto puede conducir a una subestimación del rendimiento del modelo, ya que no se entrena con suficiente información.
Por otro lado, hay un sesgo que puede surgir al hacer la asignación de segmentos. Si los datos no son tan uniformes (por ejemplo que sea muy desbalanceado o con grupos), la selección aleatoria puede resultar en segmentos que no son representativos de la base, induciendo un sesgo en las estimaciones de rendimientos.
Una alternativa para disminuir este tipo de sesgo es el de estratificar los segmentos originando la validación cruzada \(k\)-fold estratificada. Si en la base la distribución de clases es desigual se busca garantizar que cada segmento tenga una representación proporcional de instancias de cada clase.
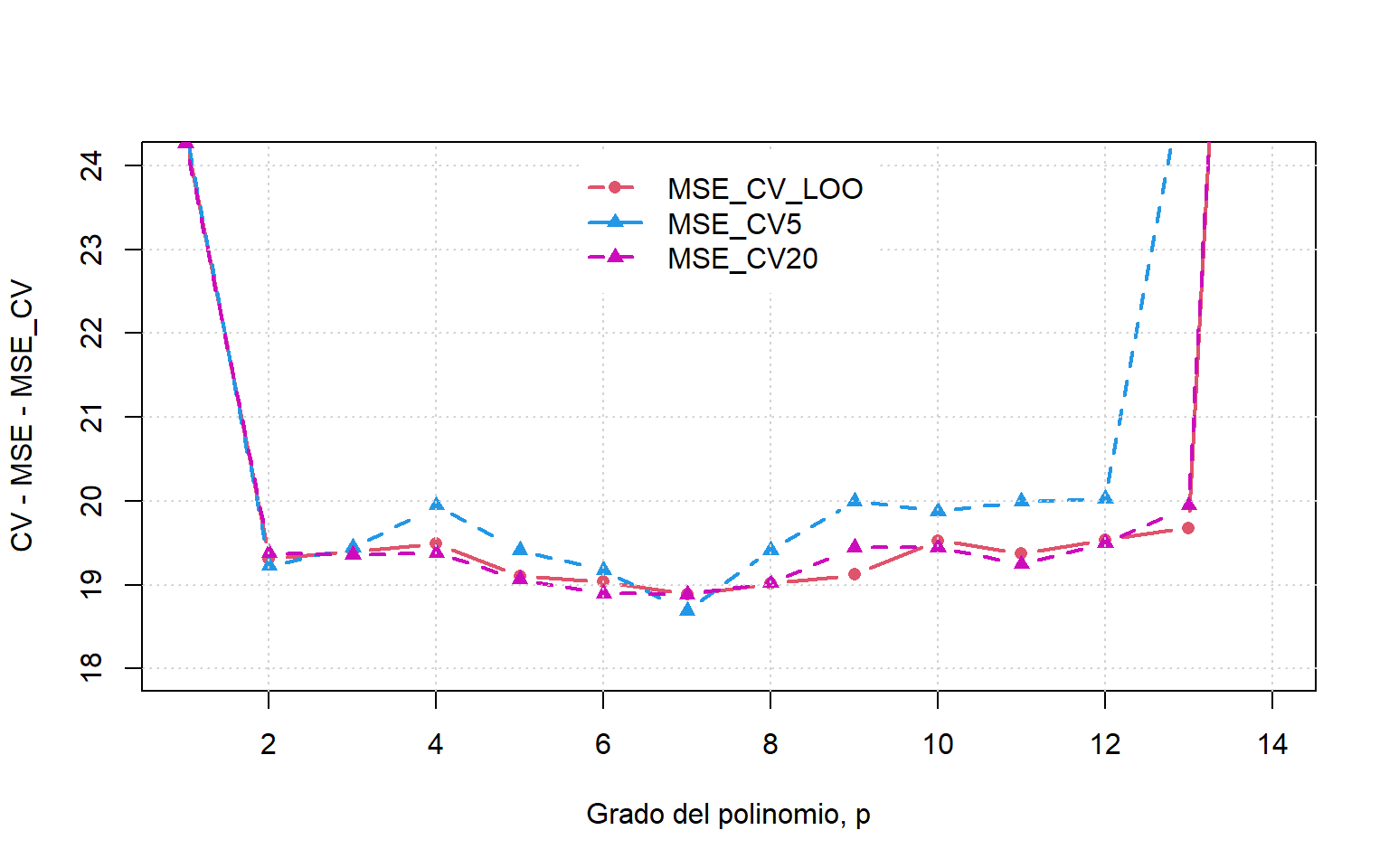
2.4.3 Validación cruzada “Leave-One-Out”
La validación cruzada “Leave-One-Out” (LOOCV) es un caso especial de la \(k-\)fold en la que \(k\) es igual al número de instancias en los datos.
En otras palabras, en cada iteración casi todos los datos excepto para una sola observación se utilizan para el entrenamiento y el modelo se prueba en esa sola observación. Entonces se tienen \(n\) diferentes iteraciones.
Como ajustar \(n\) modelos puede ser computacionalmente caro para \(n>>1\), este método se utiliza generalmente cuando los datos disponibles no son muchos, especialmente en bioinformática, donde sólo se dispone de docenas de muestras de datos.
En contraste al problema de considerar pocos segmentos, cuando éstos incrementan al punto de tener \(k=n\) se reduce el sesgo porque los datos de entrenamiento se aproximan a la base de datos completa.
Sin embargo, puede aumentar la varianza en la estimación de rendimientos debido dos aspectos:
Por un lado la alta correlación entre los modelos de entrenamiento (bases casi idénticas) originan modelos muy similares y sus predicciones son altamente correlacionadas.
Por otro, como el el conjunto de validación consiste de una sola observación, el rendimiento (como el MSE y precisión) puede estar fuertemente influenciado por valores atípicos o datos ruidosos. Si el dato sobre el que se va a evaluar el modelo, no es representativo, el resultado del desempeño del modelo en cuanto a su generalización, no es correcto y aumenta la variabilidad de este estadístico.
NotaEjemplo: Validación Cruzada ‘Leave-one-out’
Código
library("cv")np<-14var<-mse_cv_loo<-mse_cv5<-mse_cv20<-numeric(np)for(pin1:np){m<-lm(mpg~poly(hp, p), data =autompg)mse_cv_loo[p]<-cv(m, k="loo")$CVmse_cv5[p]<-cv(m,k=5)mse_cv20[p]<-cv(m,k=20)}plot(c(1, np), range(mse), type ="n", xlab ="Grado del polinomio, p", ylab ="CV - MSE - MSE_CV")lines(1:np, mse_cv_loo, lwd =2, lty =1, col =2, pch =16, type ="b")lines(1:np, mse_cv5, lwd =2, lty =2, col =4, pch =17, type ="b")lines(1:np, mse_cv20, lwd =2, lty =2, col =6, pch =17, type ="b")grid()legend("top", inset =0.02, box.col="white", legend =c("MSE_CV_LOO", "MSE_CV5", "MSE_CV20"), lwd =2, lty =2:1, col =c(2,4,6), pch =c(16,17,17))
Figura 2.20: Leave one out
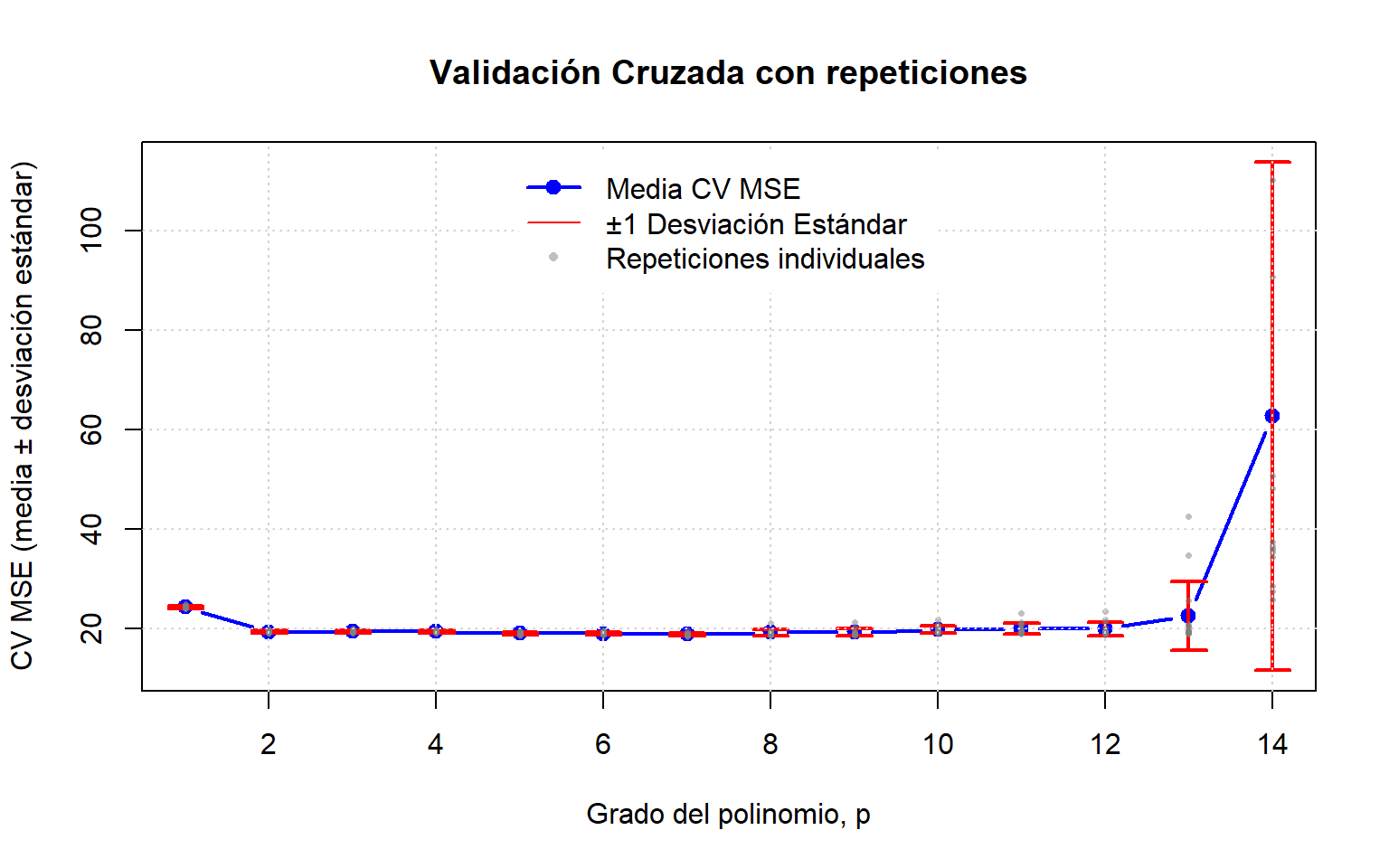
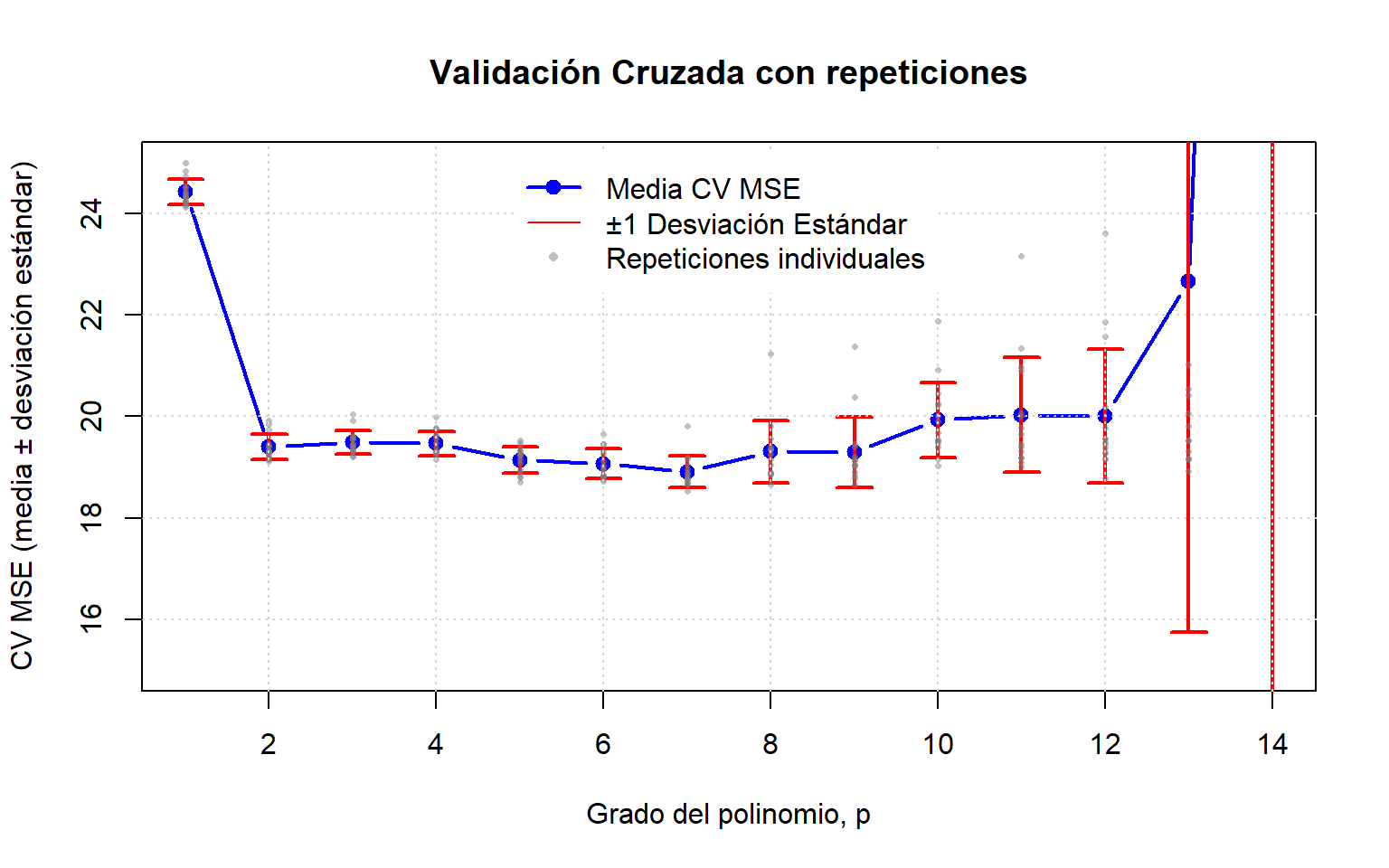
2.4.4 Validación Cruzada ‘\(k\)-fold’ con repeticiones
Para obtener una estimación o comparación de rendimiento confiables, siempre se prefieren un gran número de estimaciones. En Validación Cruzada ‘\(k\)-fold’ sólo se obtienen \(k\) estimaciones. Un método comúnmente utilizado para aumentar el número de estimaciones es ejecutar este método varias veces. Los datos se reestructuran antes de cada ronda.
En R, las repeticiones se pueden hacer usando, por ejemplo
NotaEjemplo: Validación Cruzada ‘k-fold’ con repeticiones
Código
nrep<-15np<-14# Número máximo de grados polinomialesresultados_cv<-matrix(NA, nrow =nrep, ncol =np)# 10 repeticionesset.seed(123)# Para reproducibilidadfor(pin1:np){# Ajustar modelo polinomialm<-lm(mpg~poly(hp, p), data =autompg)cv_resultado<-cv(m, k =5, reps =nrep)for(repin1:nrep){resultados_cv[rep, p]<-cv_resultado[[rep]]$`CV crit`}}# Media y desviación estándar para modelomse_medio<-colMeans(resultados_cv, na.rm =TRUE)mse_sd<-apply(resultados_cv, 2, sd, na.rm =TRUE)plot(c(1, np), range(c(mse_medio-mse_sd, mse_medio+mse_sd)), type ="n", xlab ="Grado del polinomio, p", ylab ="CV MSE (media ± desviación estándar)", main ="Validación Cruzada con repeticiones")lines(1:np, mse_medio, lwd =2, lty =1, col ="blue", type ="b", pch =19)arrows(x0 =1:np, y0 =mse_medio-mse_sd, x1 =1:np, y1 =mse_medio+mse_sd, code =3, angle =90, length =0.1, col ="red",lwd=2)for(repin1:nrep){points(1:np, resultados_cv[rep, ], pch =16, cex =0.5, col =rgb(0.5, 0.5, 0.5, alpha =0.5))}grid()legend("top", legend =c("Media CV MSE", "±1 Desviación Estándar", "Repeticiones individuales"), col =c("blue", "red", rgb(0.5, 0.5, 0.5, alpha =0.5)), lty =c(1, 1, NA), pch =c(19, NA, 16), inset =0.02, box.col="white", pt.cex =c(1, NA, 0.7), lwd =c(2, 1, NA))plot(c(1, np), range(c(mse_medio-mse_sd, mse_medio+mse_sd)), type ="n", xlab ="Grado del polinomio, p", ylab ="CV MSE (media ± desviación estándar)", main ="Validación Cruzada con repeticiones", ylim=c(15,25))lines(1:np, mse_medio, lwd =2, lty =1, col ="blue", type ="b", pch =19)arrows(x0 =1:np, y0 =mse_medio-mse_sd, x1 =1:np, y1 =mse_medio+mse_sd, code =3, angle =90, length =0.1, col ="red",lwd=2)for(repin1:nrep){points(1:np, resultados_cv[rep, ], pch =16, cex =0.5, col =rgb(0.5, 0.5, 0.5, alpha =0.5))}grid()legend("top", legend =c("Media CV MSE", "±1 Desviación Estándar", "Repeticiones individuales"), col =c("blue", "red", rgb(0.5, 0.5, 0.5, alpha =0.5)), lty =c(1, 1, NA), pch =c(19, NA, 16), inset =0.02, box.col="white", pt.cex =c(1, NA, 0.7), lwd =c(2, 1, NA))cat("Mejor grado polinomial:", which.min(mse_medio), "\t MSE medio del mejor grado:", round(min(mse_medio), 4), "\n")
#> Mejor grado polinomial: 7 MSE medio del mejor grado: 18.9064
Código
# Resultadoslibrary(knitr)resultados_df<-data.frame( Grado =1:np, MSE_Medio =round(mse_medio, 4), SD =round(mse_sd, 4))kable(resultados_df, caption ="Resultados de Validación Cruzada con Repeticiones")
Resultados de Validación Cruzada con Repeticiones
Grado
MSE_Medio
SD
1
24.4218
0.2546
2
19.3994
0.2473
3
19.4874
0.2377
4
19.4703
0.2405
5
19.1392
0.2605
6
19.0692
0.2916
7
18.9064
0.3106
8
19.3084
0.6143
9
19.2935
0.7013
10
19.9270
0.7443
11
20.0314
1.1294
12
20.0082
1.3142
13
22.6594
6.9090
14
62.7526
51.0683
Figura 2.21: k-fold con repeticiones
Figura 2.22: k-fold con repeticiones
Figura 2.23: k-fold con repeticiones
Bouckaert (2003) estudió el problema del error tipo I inflado de la validación cruzada ‘10-fold’ y argumenta que dado que las muestras son dependientes (porque los conjuntos de entrenamiento se superponen), los grados reales de libertad son mucho más bajos de lo que teóricamente se esperaba. Este estudio comparó un gran número de esquemas para la prueba de hipótesis, y recomendó una validación cruzada ‘10 x 10 -fold’ para obtener 100 muestras, seguidas con prueba \(t\) con 10 grado de libertad (en lugar de 99). Sin embargo, este método no se ha adoptado ampliamente y la validació cruzada ‘10-fold’ sigue siendo el procedimiento de validación más utilizado.
Bibliografía:
D. A. Belsley, E. Kuh, and R. E. Welsch (1980). Regression Diagnostics: Identifying Influential Data and Sources of Collinearity. Wiley, New York.
Rawlings, J. O., Pantula, S. G., & Dickey, D. A. (Eds.). (1998). Applied regression analysis: a research tool. New York, NY: Springer New York.
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An introduction to statistical learning (Vol. 112, No. 1). New York: springer. Liga a ebooks
Referencias:
Bouckaert R.R. (2003) Choosing between two learning algorithms based on calibrated tests. In Proc. 20th Int. Conf. on Machine Learning, 2003, pp. 51–58.
Larson S. (1931) The shrinkage of the coefficient of multiple correlation. J. Educat. Psychol., 22:45–55.
Mosteller F. and Wallace D.L. (1963) Inference in an authorship problem. J. Am. Stat. Assoc., 58:275–309.
Mosteller F. and Tukey J.W. (1968) Data analysis, including statistics. In Handbook of Social Psychology. Addison-Wesley.
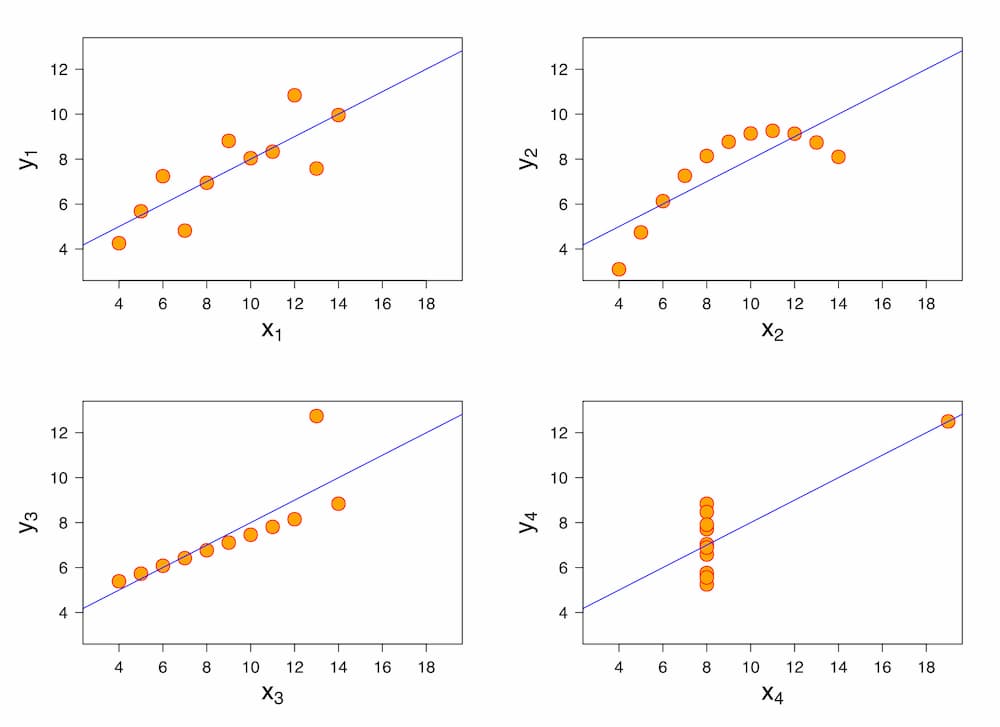 Estos datos compartes las siguientes características:
Estos datos compartes las siguientes características: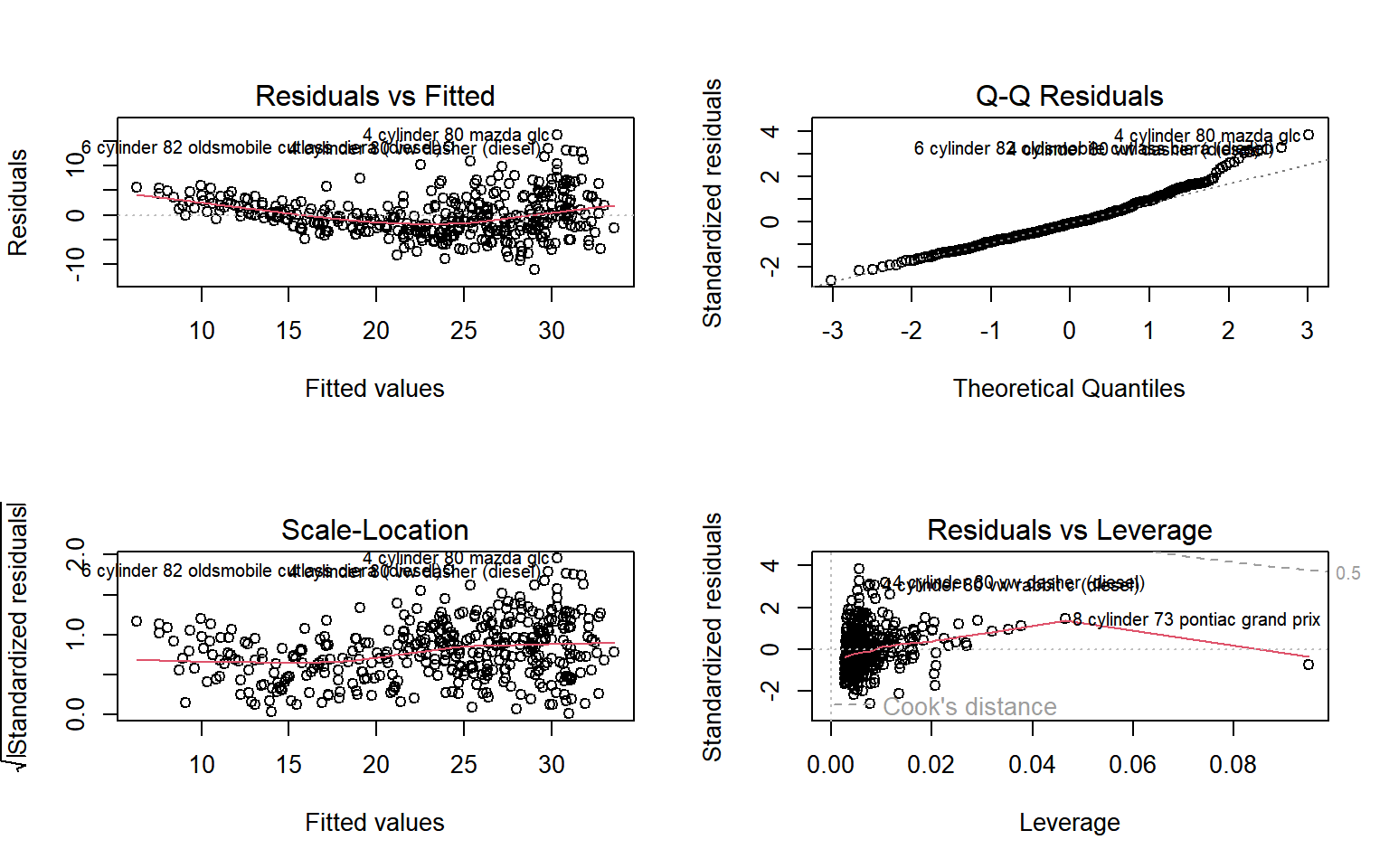
 En el caso de regresión lineal simple, es fácil detectar cuales puntos son influyentes pues gráficas sencillas como las anteriores los mostrarán. En el caso multivariado no es obvio ver cuales puntos son influyentes pues no es suficiente con ver las distribuciones marginales de las variables (Ej. haciendo grafica de puntos de
En el caso de regresión lineal simple, es fácil detectar cuales puntos son influyentes pues gráficas sencillas como las anteriores los mostrarán. En el caso multivariado no es obvio ver cuales puntos son influyentes pues no es suficiente con ver las distribuciones marginales de las variables (Ej. haciendo grafica de puntos de 
{kind=link}