Searching a Differentiable Architecture for Large-Scale Video Classification
Abstract — Automatic multi-label classification in large scale video datasets presents a challenging task that has been mainly addressed using deep learning. This paper presents a novel method of automatic design of efficient neural architectures for video classification based on differentiable architectures. The proposed method identified two neural cells in a search space of operations that work in the temporal domain of video data. The most suitable architecture is searched using the gradient-based differentiable architecture search using a decoupled scheme that separates the selection of inputs and their respective operation. The proposed method is evaluated on the YouTube-8M dataset, where it achieves better performance than 4 state-of-the-art base architectures, in terms of four evaluation metrics for multi-modal video classification. The best categorization performance is obtained by the proposed model on an architecture based on vectors of locally aggregated descriptors, that has been found and trained in competitive time.
Authors:
Fernando Cervantes-Sanchez, Omar Villanueva, Palash Goyal, Ivan Cruz-Aceves, Arturo Hernandez-Aguirre and Carlos EscamillaResearch paper submitted to 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2022), 22-27 May 2022, Singapore
Results on different sub-categories of the YouTube-8M dataset
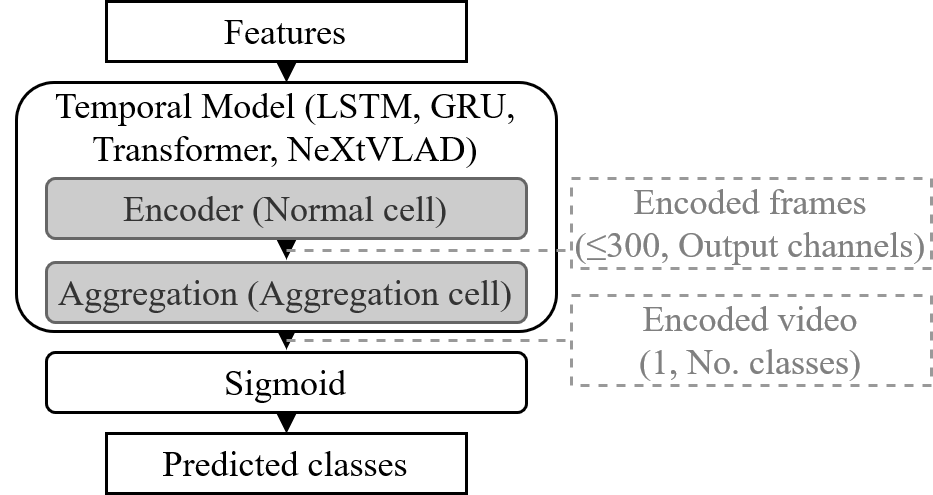
The grey neural cells (Normal, and Aggregation cells) are optimized using GDAS, using a new search space of operations.
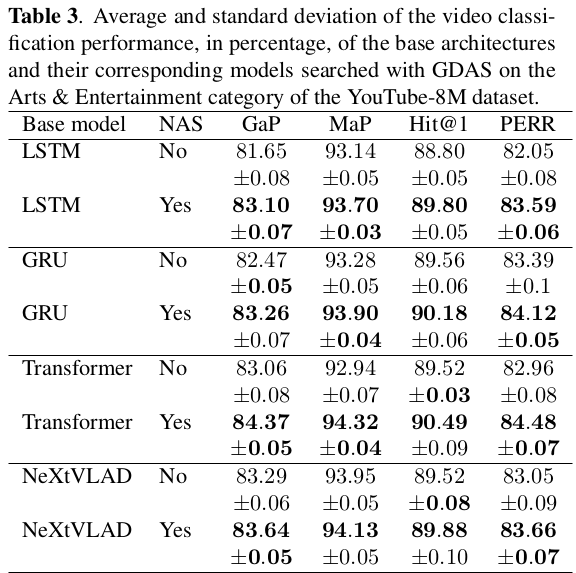
GDAS on the Arts and Entertainment category of the YouTube-8M dataset
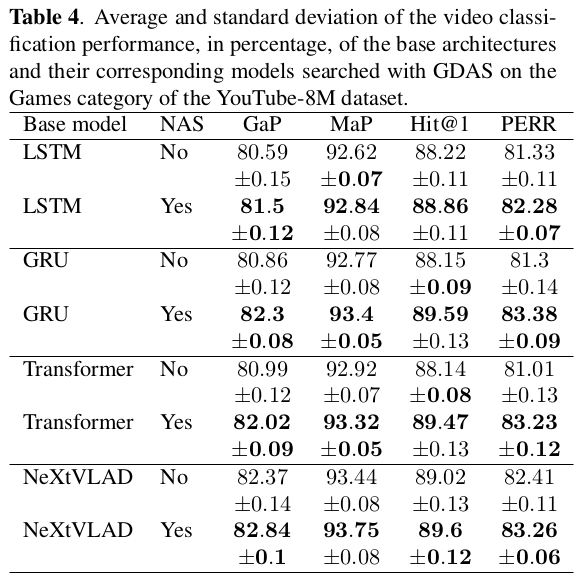
GDAS on the Games category of the YouTube-8M dataset.
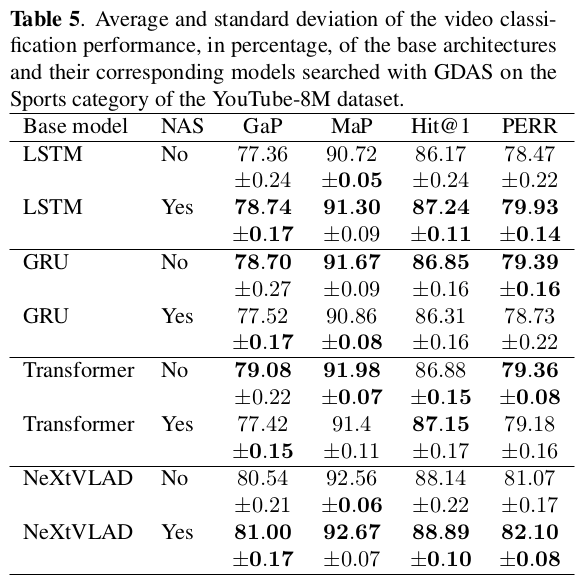
GDAS on the Sports category of the YouTube-8M dataset.